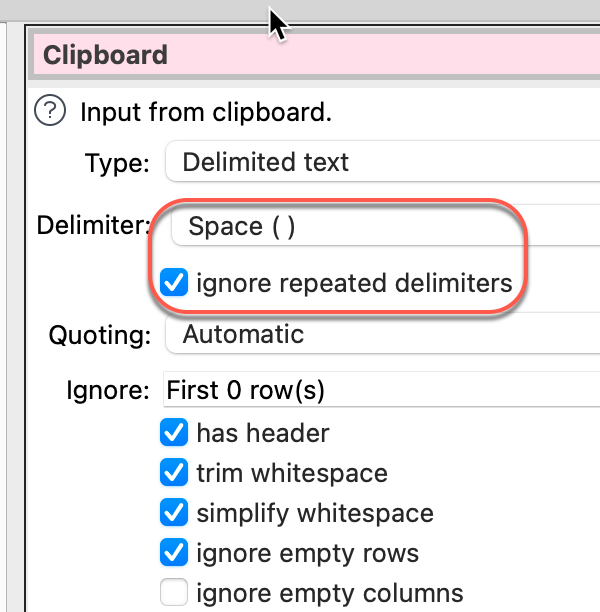
I’m playing with the trial version, I’m impressed. However I can’t work out whether it is possible to shift rows left after copying data from a website.
Currently the data when copied looks like this
Col 1. Col 2. Col 3. Col 4. Col 5
A. B. C. D. E.
A. B. C. D. E.
A. B. C. D. E.
What I would like to achieve is similar to BBEdit where you select all of the data and use the Shift Left command to move everything to the left, this would move the 2nd and 3rd rows under the first.
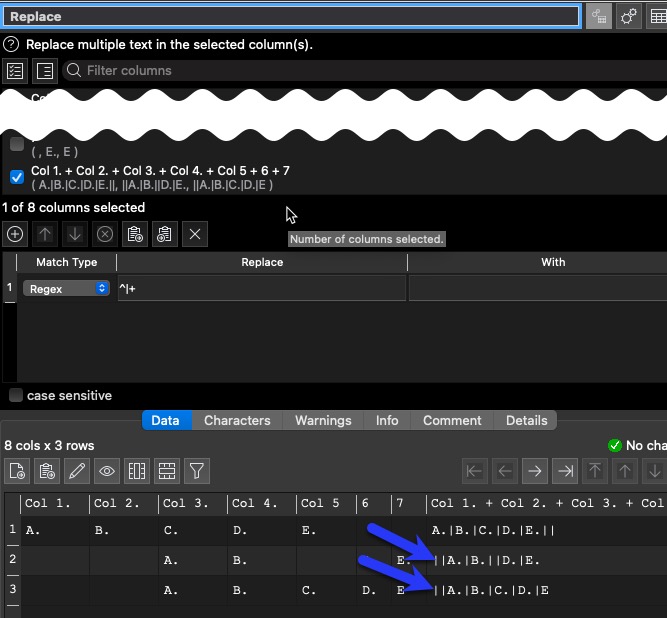
Thanks for the very quick response, I was able to use your method of concatenation but used the Keep Empty Values setting to preserve the empty cells in the middle of the data. My example didn’t include this but the live data I am working on has lots of empty cells.
This posed a problem that keeping the empty values also kept the data that I was trying to remove at the start of the lines. I used the Replace node after the Concat Cells to remove the leading and trailing vertical bars with Regex before it ran the Split Col and this worked for me.
The Regex looks like this, the ^ is the anchor for the start of the line and the $ is the end of line
A regex that could be applied per row on import would work, in this case I just need to remove the leading whitespace which would be the same as a shift left.
In BBEdit I can select all of the text and shift left several times, it will keep going until it meets up with a character, this will not affect lines that start with a character other than white space.
It’s difficult after the import since you have already constructed columns and I can’t process the row without concatenation.
It’s cryptic to read sometimes but for the first one, the ^ character means start at the beginning of the line
Then \| is the literal | character, in this case we need to escape the | as it is used in regex
The + is one or more, so I’m looking for multiple vertical bars at the start of the line and replacing them with nothing.
The second one is much the same except the $ is the end of the line, so find one or more vertical bars at the end of the line and replace with nothing.
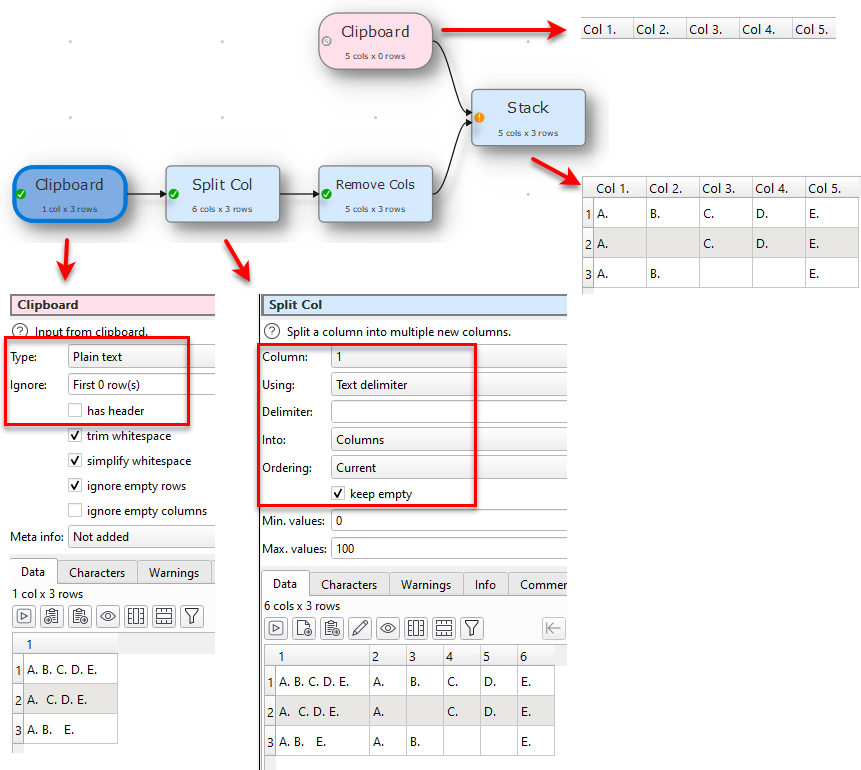
Here is an another idea, import the file just as Plain text, then the leading and trailing spaces are removed auto by EDT during import and then simply split on the delimiter.
Steps.
Bring in the headers only
Bring in the data only no Headers
Split the data on the delimiter (in my case space) and check Keep Empty
A per row regex could be tricky as I am not sure how you could handle text that spanned multiple cells.
A transform that moved everything left (or up, right or down) until all empty cells were filled would be relatively straightforward to add. I’m not sure what we would call it though. Shuffle and Fill are already taken.
Unless you import as plain text, in which case it will import everything into 1 column. Then you have to split it back out into rows, as shown by @Anonymous above.
Admittedly a per row regex would only work with text files, but the ability to affect the input before it becomes a row of cells would be useful, it would save me taking the data through BBEdit.
Until today, most of the data wrangling I have done is a mix of FileMaker and BBEdit with GREP, it’s a powerful combination but I can see an easier route with EDT, it’s a great tool.
I’m not sure about multiple cells either, but given that you would probably have to craft the regex to fit the data anyway, you would probably take that into account. I’ve done a lot with tabular data especially swapping columns or names like first with last etc.
Thanks, that’s a really good solution, I like the use of Stack to put the header on the data. I also tried concatenating just the first two columns and using Reorder Cols to put them at the start but it didn’t work as expected.
I also experimented with Header, that works well if you import without a header so the header is part of the data and then use Header to promote the first row.