Yes, technically once in production file is generated once and passed on to other scripts. If you do consider this , it could be part of SHUFFLE feature to generate UUID also
UUID 4 atleast is complete random , not requiring any input from user side. Hence no reversibility
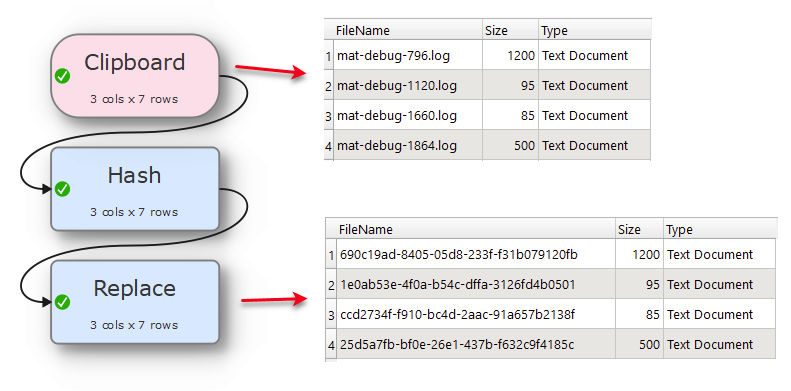
Do it in a single transform by hashing a suitable column (or concatenation), or generate a random number and hash or base64 that. What is the length you desire?
Hello,
Could you please explain how can to do it directly with EDT (without JavaScript)?
I also need to anonymise some columns with random unique values.
Thank you in advance
SHA1 produces 40 characters so I have chopped it to 32 in case that is a criterion.
If you want to retain a separate lookup table of the original codes against the hashes then copy the original data, join, and delete not-required columns
A hash can be used to generate a long alphanumeric. It is useful for anonymising things. But the same input to the hash will always give the same output. Also, you can get collisions where 2 different values could conceivable return the same hash value. Although this is unlikely with a well designed hash.
UUIDs produce a large random number[1], based on no input. They are incredibly unlikely to produce the same UUID twice.
[1]Mostly. There are various different types of UUID.
I don’t think the third party library we use (Qt) has any way to change the UUID seed. If it did that would make it more likely to generate the same UUID twice, which would defeat the object of using UUIDs.
I also need to anonymise some columns with random unique values.
You might consider using Random to add a column of random values, Concat Cols with, say, their name to get values like:
98430238JohnSmith
32980712JaneSmith
Then hash those.
Note that it is possible that 2 different strings could result in the same hash (a ‘hash collision’). But this is very unlikely and you can check for it with a Verify transform.
SHA1 collisions have a likelihood of about 1 in 2^80 (10^24). For 100,000 records that comes down to about a 3.4x10^-39 probability of collision.
If that is not sufficiently rare then use SHA256 or greater on padded data. The randomness of any arbitrary number of alphanumeric characters, whether or not case-sensitive, is not varied by calling it a UUID rather than a hash. Other than encoding bits, the example I gave represents UUID V5.
I noted earlier that hashing a key is for anonymisation, where you keep a separate secure file for lookups. Some Census bureaux do this for current anonymity yet for the benefit of historians after 99 or so years.
If non-repeatable keys are desired then hash a random number, as Andy and I both mentioned.
The 8-4-4-4-12 structure to which Prashant referred is the addition of separators (given Prashant did not express the need for codification bits), probably achievable with a bit of Regex. I have not looked more closely at that.
I guess part of the problem here is ill definition. Is a random key to be generated from scratch or from existing unique data? How much data? What collision probability is acceptable? UUID itself has slightly less than the theoretically calculable options for its length because strictly it uses a nibble to encode its type.
Math.random() in JS has a cycle length of 2^128 apparently (2^30 for older versions) so the question is the seed, which comes back to my original request for easy variation of it or even to have it as metadata.
Speculation on a change:
The default seed EDT generates for a new file could be retained in Random while a separate seed is generated from a hash of the input data (extracting digits) and made available through metadata. The suggestion of a “Generate now” button in Random would also be retained.