I wish EDT could preserve the settings while doing changes in configuration. Even if I do a slight change, as little as adding a New Column step somewhere in between the flow, the following steps lose the configuration completely even though the table, data and columns (except for adding 1 column at the end of the table) actually did not change.
So I wish the configuration in EDT for the individual settings in the step would be preserved and only clear if that underlying field, column etc, got deleted for example.
Right now even if I add column ad the end, I have to redo whole workflow, I don’t need to add steps, they are all there but the steps are completely broken and lost configuration so I have to reconfigure all of them and it takes a bit time to figure out how did I set it up.
So right now I am doing backup of the EDT file along with the CSV I use as template to configure so that I have a working backup to look at for my reference if I need to change things.
Another thing on my wishlist is ability to run multiple sessions of EDT application. I can’t figure out how to open multiple windows. When I click NEW, the application doesn’t open a new window, it closes existing one (ask to save) and opens a blank new canvas. [RESOLVED]
EDT works internally with the position of columns and not their names, see Documentation. In case input file might change use Stack as one of the first steps as mentioned in documentation to ensure the intended sequence of columns. I even use stack to order pivot results, in case that sometimes not all expected values exist, so that the further steps work as intended.
In addition I use the comment tab in the right pane intensively to document what is done and which fields/comments are used, so that in case the order of columns changes, I can retrace the intended columns and correct without search in backups.
In file menu is a topic “New Window” on Mac with shortcut Shift-Command-N, which opens further windows/instances.
My bad, I didn’t see that New Window option under all the other options there, I was looking at the top expecting it there.
With regards to position of columns - I am not talking about changes to CSV file. I am talking about adding a step of creating a new column in the existing workflow. Not creating a column manually in CSV and then loading the new CSV in EDT. I wouldn’t expect that to notice new column.
All I needed is open a the recipe and add a step somewhere New Column. When I do that, it doesn’t matter where to column goes, even if it goes to the end and no other step becomes affected, still the recipe settings break and I have to reconfigure the steps.
If you delete a connection then all column related options downstream will be lost. So try not to delete connections. You can insert and delete transforms without delelting connections:
As long as you don’t delete connections, then Easy Data Transform should be robust to adding, redordering and deleting columns via transforms. If you have found a case where that isn’t true, please let us know.
Okay so I tested, when I add a Split Col transformation in front of an existing chain for (SplitCol/RenameCol) transformations it will break the subsequent ones.
I have inserted the transformation by highlighting the connection.
When the new Split Col step creates 2 new columns with names e.g. Info1 and Info2. But these columns were used by later Split Col steps. So adding it in front, now the Info1 and Info2 column names are not available and the Split transformations need to be opened one by one and reselect the Column for the particular Split Col transformation.
I thought it would revise the column names for the subsequent transformations but it doesn’t, or it could add another name for the new Split Col step by using a different name. Both not the case.
Similar situation happened when I added an IF transformation without even configuring it fully and then changed my mind, decided to the IF transformation again (not the connection). As soon as I deleted the newly added IF transformation, all of the subsequent Split Col transformations break (the field Column: in the Split Col configuration is cleared and the column must be selected again).
I tried this with the “fillphone2.transform” from the other discussion. I added an IF between the UNIQUE and the SPLIT COL transaction I even used an additional REORDER COLS and moved the new IF result column to front before the SPLIT. Afterwards I deleted the IF first everything worked fine when I delete the REORDER next, still all is working as before.
Can you load an example, before adding something, with the added parts and after removing. Please load all 3 versions. I do this adding and removing all the time, normally ist doesn’t break as Admin said. WIth the 3 files we might be able to see something. Maybe there is an issue with your environment.
I don’t remember which file now was the issue but if I come across the recipe I will try if I can upload but remoting to a system now so won’t be able to upload.
Probably have to download an update but I also noticed if I have Remove Col followed by Replace tool, then if later I reselect a column at the beginning of the table (to no longer remove it), the Replace tool points to wrong column, it shifts so that the replace formula works in the wrong column (the replace column selected shifted by 1 to left, because I have reselected 1 column in Remove Col that was previously unchecked.
I noticed another issue…when I have Spread tool in the workflow and if the CSV contains a column called “Type” which defines the type of transaction and it is the Key Column in Spread tool and if my CSV suddenly contains a new type new type of data (e.g. a new type of transaction which wasn’t included in the CSV template that was originally used to setup the workflow) then Spread will create a new column (which is all right, that’s what I want) but then the following tools are broken, for instance if after Spread comes If too, then the If tool logic will point to the wrong column, it would be shifted by 1 column … and that is apparently because my table is now 1 column larger due to the Spread creating additional column.
The saved workflow must only be opened with exactly same type of data-set, including the range of data. As mentioned before with my example for the Type column, if I do not have a full range of values in my dataset which are used for the Spread function, then the whole workflow breaks, the filters for instance get reset, Stats. Concat Col etc gets reset and I can get on spend more hours configuring again.
Second situation is running it from batch will make a difference, but it doesn’t. If the dataset is different, the resulting tables are junk. The output produces ghost columns. Because the dataset is missing, the columns in Spread get not created, but the output still wants to add columns so it adds junk columns even though they don’t exist in the branch. I have removed the columns using Remove Col step. Still, if there is not enough columns, it the output will force show the columns that were previously hidden with Remove Col.
In other cases the output produced additional junk columns, columns I don’t even have anywhere in my table or in the workflow.
This is related to the same issue I am describing with the Spread function and the volatility the settings. The settings seem a bit too fragile for my use.
I am looking also at easycsv and csvbox because I don’t know if I can reliable use this tool.
No, the number of columns or format of the CSV stays exactly the same. No change.
What is changing is the data.
If I have columns TYPE, COLOR, MATERIAL etc… and TYPE for instance has values Small, Medium, Big and I do a spread using TYPE column. Then if the new CSV does not contain data with all 3 values in the column TYPE (e.g. the CSV only has records with TYPE either Small or Big), then the workflow will break and the output will be broken. I am trying to simplify here to explain what is going on.
Also, as result of the above, the order of the columns gets randomly mixed up even though I set it in Reorder Cols tool.
The issue could be related to above because the columns that do appear in the output (when they are not supposed to) also get mixed around in the order in the Reorder Cols tool.
Another issue with columns is when Spread tool creates automatically additional new columns, they are all added in Remove Cols tool and automatically checked to show them. Instead I would prefer to not show the additional new columns, but rather decide if I need them to show in my output file.
Ideally there should be an option as whether to keep or remove new columns for the Remove Cols tool, but we don’t have that yet.
Trying to match up column related options to columns in the dataset through a directed graph where columns are added, removed, inserted and renamed at each node is the most complicated part of Easy Data Transform. Clearly there is at least 1 bug related to this. We hope to have a fix in the next release.
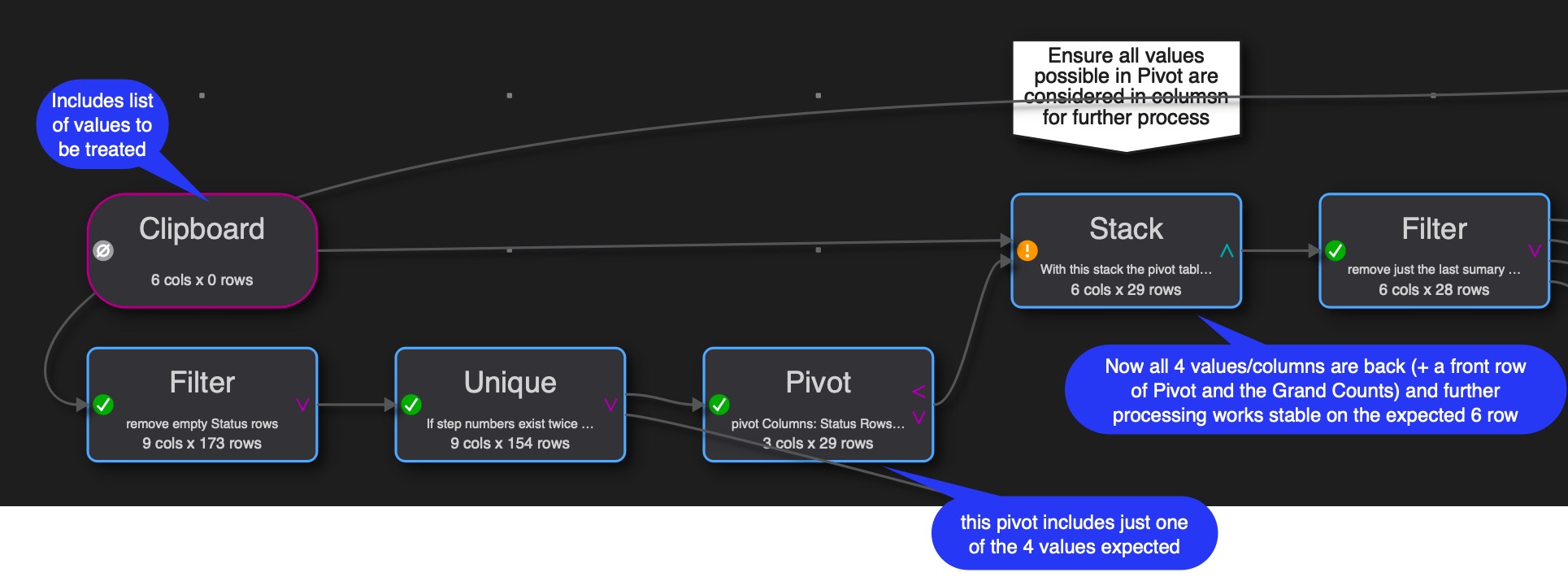
Mixing up columns based on the values in the date happens with Spread and Pivot, maybe in more. Order will not help as it based on the existing values. So it will loose values which are gone or do unexpected changes. Best is to create a list of values (headers) you want to handle and put them in one file with just the header names and use Stack with that header file and the data you process before you do the next steps. With Stack you can even decide if new/additional values occur at the end of the column list or are ignored. This is what I meant in my first reply with the results of pivots I stack, as not all possible values are in the pivot each time when I process the data. Without stack my process will break every time a value is missing a new one comes up.