Okay now I understand. It wasn’t initially obvious so maybe you can mention it in your user help manuals.
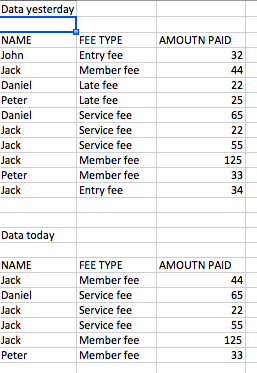
Simple example:
The workflow is setup with Dataset for yesterday in mind and the workflow includes the Spread function on the column FEE TYPE.
Today I received the same CSV, but it has less data in it so when the Spread function runs, it always results in a different situation.
If yesterday the spread produced 4 columns, today it will produce 2 columns only.
So subsequent Concatenate, Filter, Remove Cols functions will break.
This may need to be mentioned in the user manual for the following functions at least that produce columns based on the data in the table: Pivot, Spread but also Split Col function since Split Cols also can do similar thing as Spread.
Looks like one bug I found. I made copy of the transformation before I did change. And I created a blank CSV just with the complete headers. Stack step worked fine
I have following steps … Spread - Stack - Concat Col - Filter …
The transformation where I added Stack, has broken the Filter step. The Concat Col step worked fine but Filter broke. The Filter step lost the configuration completely so adding Stack will wipe the Filter step and I had to re-add the rule. Not a big issue, but just wanted to mention that.
Also - unrelated to the Spread / Split / Stack discussion here:
Adding or removing a column in Concat Col transformation (check / uncheck a field) still does break a Filter transformation (the filter settings are gone and the filter step is reset to blank). If there was an expectation to resolve it, then this i not resolved yet. If I misunderstood, please correct me.
Thank you for suggestion for the Sort function, this is important and I missed it there. Without that there could be issues. So now I think it is air-tight. I’ll try to send the file once I am in the office but working on my mobile phone again.
Wondering I didn’t understand what is the purpose of the Maximum and Minimum values option to produce same amount of columns. What is the use of having empty columns? If the data is missing, then Spread will not know what headers to use.
I use now the Stack with “template table” to add the missing columns if there is some column missing from the “working table”.
Can you please what the Max and Min does? The user guide page says on the bottom same thing what you suggested but doesn’t explain what it means.
If you set both Maximum and Minimum to 10, then it will always produce 10 columns, no matter what the input. Potentially this saves you having to do a Stack assuming the column order is the same.
Some of the columns may be empty
You could lose some columns (e.g. if it would otherwise output >10 columns).