I just recently downloaded the platform have been playing around with it. I was wondering if you guys could give me a head start.
I’m Web scraping data for a project. On multiple different sites then aggregating them into a CSV.
On every site “generally at least” the product has been called something similar but not the same.
So it would look something like this
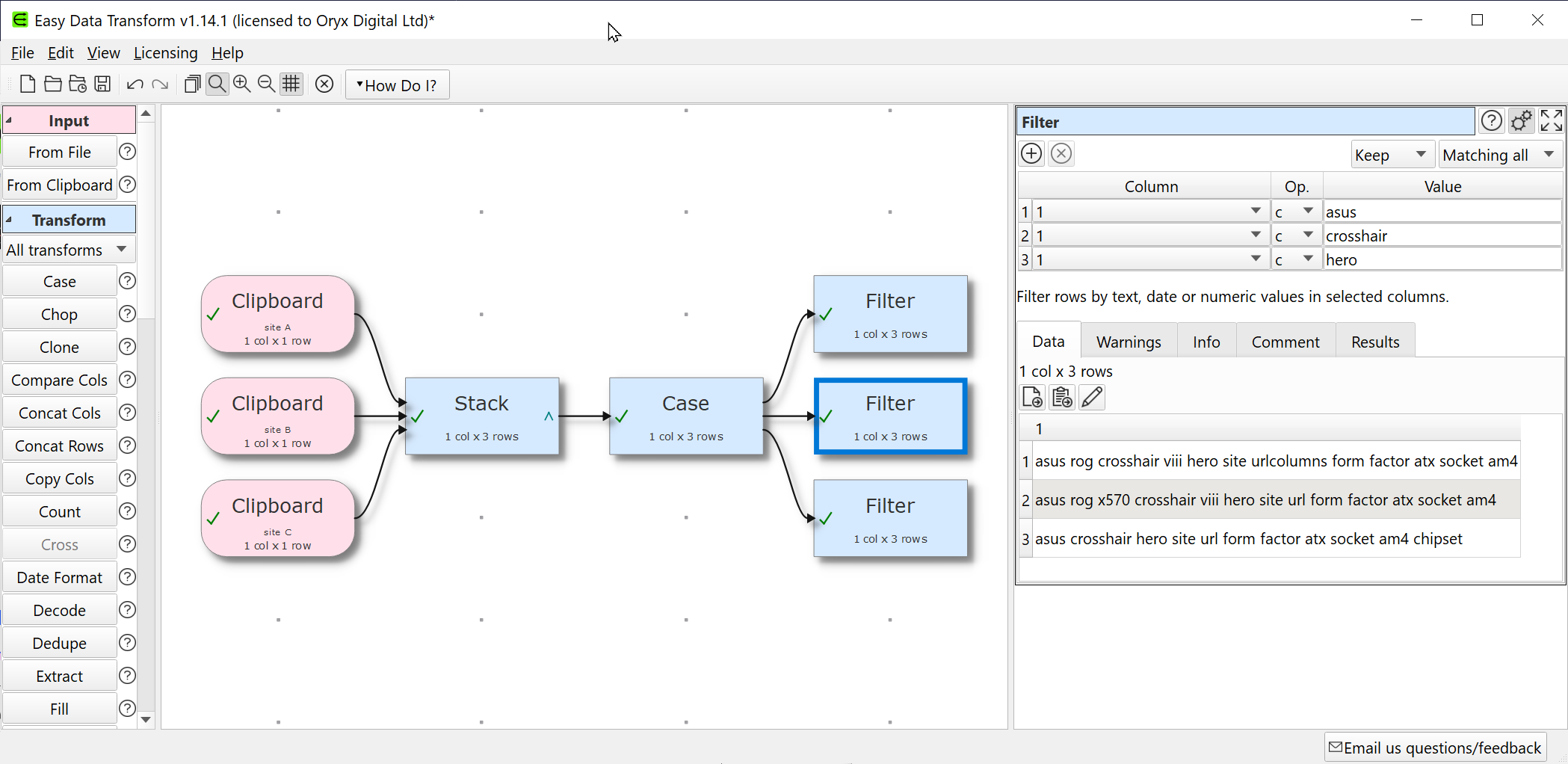
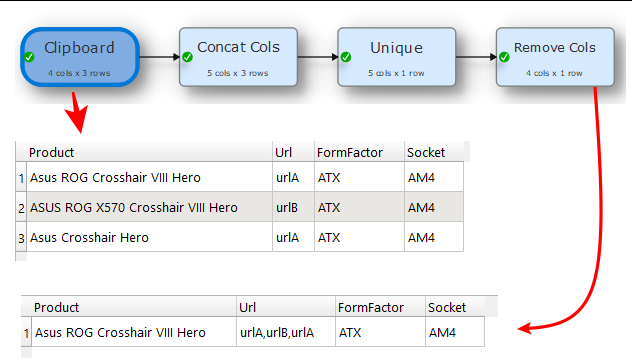
Site A Asus ROG Crosshair VIII Hero Site URLcolumns form factor ATX Socket AM4
Site B ASUS ROG X570 Crosshair VIII Hero Site URL form factor ATX Socket AM4
Site C Asus Crosshair Hero Site URL form factor ATX Socket AM4 Chipset
all the same Motherboard but different names on different sites. Is there a way to identify all the duplicating rows then merge these duplicates into one row? So it would look like this
Asus ROG Crosshair VIII Hero Site A URL Site B URL Site C URL form factor ATX Socket AM4
I have about 5000 thousand listings and have been doing them manually. Its obviously extremely time-consuming. Several people have recommended using panda, I’m not great with python. Many have also recommended EDT!
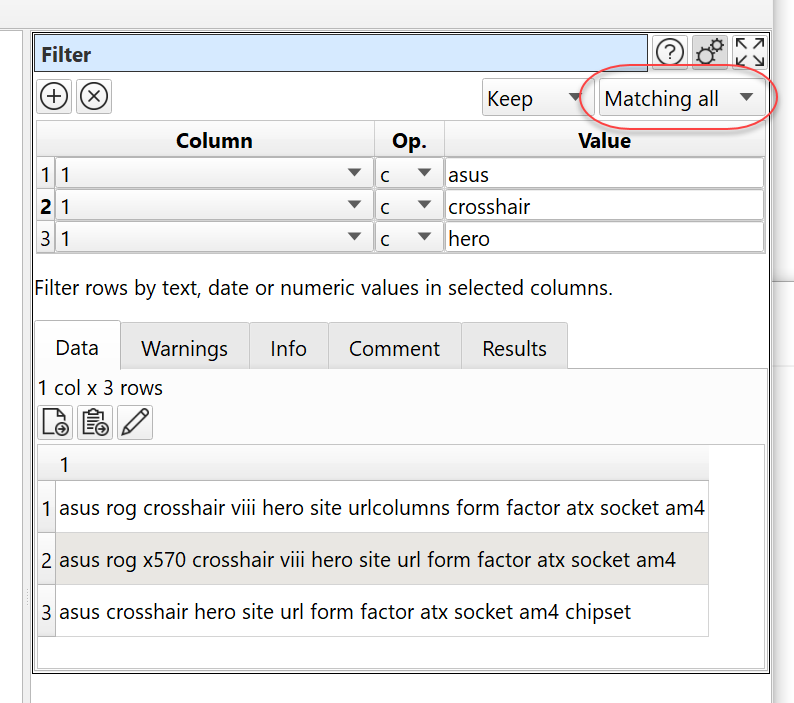
I know the general logic if Name Matches 65% of other Name & Socket & ATX are the same merge row. I just don’t know how to do it or where to start.
(you can also use regular expressions in the filters)
You can then re-run EDT any time the input changes. You can also add a new filter if a new product appears.
Obviously it would be nice to have some form of ‘fuzzy matching’ to do all this automatically. We don’t currently support fuzzy matching. Maybe one day.
Fuzzy matching is tricky. It requires a lot of domain knowledge to understand that “Asus ROG Crosshair VIII Hero form factor ATX Socket AM4” is the same as “ASUS ROG X570 Crosshair VIII factor ATX Socket AM4” but different to “ASUS ROG X670 Crosshair VIII factor ATX Socket AM4”. If you are feeling brave you could try to code up your own solution in Python. Or maybe there is a library that can do it. Try looking at https://en.wikipedia.org/wiki/Levenshtein_distance . But I think that is mostly used for single words.