I’m a non-technical user and am trying to figure out how to make Easy Data Transform work for us.
We are a small, independent book publisher with a tiny staff of 1.5.
Today, we receive compensation (aka sales) reports from 4 different distribution channels. The reports come in the form of CSV files, and the data structure is different for each of them.
We have a sales and royalty tracking system. To get the sales data into our system, I created a normalized template in Excel. Today, I manually map and copy and paste data from the distribution channel’s report to the common import template.
In ALL cases, I also have to do a level of data transformation. For example, a report may be in GBP, and in the common import template, I manually copy the GBP amount and paste it in the correct column, then I add an exchange rate to another field, and then calculate the USD amount.
I’m having trouble getting out of the starting gate. Using Easy Data Transform, am I copying a field from one spreadsheet to another, or am I essentially creating a new Excel file?
I am also unsure how to add variables into the mix. For example, the GBP to USD conversion rate changes every month; it’s not a constant from month to month.
Here’s an example of just some of the fields in one of the source files
Title
Author
SKU
Marketpace
My Wonderful Book
John Doe
B0DKC99YWP
Library A-Go-Go
Destination Import File
Channel
Date
ISBN
Sales Source
Mega Distributor
1/31/2025
B0DKC99YWP
Library A-Go-Go
I have lots more questions, but this will get me out of the starting gate.
You should use Easy Data Transform to transform your inputs (whether files or pasted from the clipboard) to create one or more new CSV or Excel files.
To add a conversion rate, just use the New Col transform. You can then use the Calculate transform to multiple or divide this to do your currency conversion. You can manually change the conversion rate next time you run it.
You show 2 typical records, but I don’t know what you want to do with them. Do you want to combine them to produce a new record? If so, what would that look like in this case?
Is that information in the file name? If so, you can bring it in automatically with metadata rather than adding it manually. It does not need to be actual channel name, just a unique and reliable identifier you can transform to the channel name in EDT.
You could also maintain or download as required a separate file with currency conversions for import, saving the step of changing the currency on each run.
The more data you can provide which shows at least the critical components of the actual input and desired output, with data on file names, the more readily people will come up with solutions for you.
I had some thoughts about it and adapted the suggestion of @Admin.
I would create for each of the 4 distribution channels an own EDT transformation file. Based on the specific fields and order of the field. I would use a dedicated processing (input) folder and would name the file to be processed with the identical name each time it is processed.
Further more I would create a fiel with the exchange rates in the processing folder where I maintain the rates (inn the file there can be different currencies in the columns).
With this the transformation sequence can calculate the amount in the target currency.
With this idea you copy the new to be processed file into the proceeding folder, rename it to the foreseen name and start the right EDT transformation file for that channel and it generates directly the Excel output file with a current date information and you have no need to change anything within EDT.
If this works you could even execute the edit transformation later on in command line mode without GUI and the output file is created. But this a for sure a later step.
@RYGP A pity about the file naming but it just means some preliminary work which might otherwise be automated. EDT can bring in more than one file at a time, or separate file and clipboard data, as @Olaf has made clear. It may be possible to use a schema to capture those with source currency data while stopping on those without, to slightly reduce work.
It is still ambiguous whether you have four input formats from the four channels or they may be more variable than that. Your task appears to me to appropriate for a schema and a couple of inputs but I may be quite wrong. More information on the source data and expected output will help.
All the essential elements listed as inputs, headers and typical contents, and the corresponding desired outputs. How many file formats are received and, if existing, commonalities between them or special cases that might need to be handled.
Put another way, what are all the input formats and what is the desired output content and format? Given that, my experience here is that people will come up with various solutions then Anonymous could tell us how it really should be done.
I’m afraid I’m not a technical person, but I am good with data.
Then you are right with EDT, the good thing is you don‘t need to program, you just need to get an overview about the possibilities in EDT and then you klick the flow you intend to do with the data together.
Sometime you need an idea how to do something and the forum will typically help and discuss.
I receive 3 different CSV files. One of the distributors sends a separate file for each currency: USD, GBP, and AUD. One of them mixes the currencies in the same file, and the last one sends a file, and the values have already been converted to USD by them.
I’ll start with the one where I receive a separate file for each currency, because this is probably the most complex. I hope this isn’t overkill.
On the left is the source file field name (aka column header), and on the right is what I manually map to today. I’ve also noted where I do special manual processing. But that’s worth calling out here separately. Unlike most other businesses on the planet, bookstores can return books to the distributor and get their money back. The publisher pays for it. Both the sales and returns for a period are in one row of data. It is possible for a given book title in a file it is possible to have the following conditions:
Sales and Returns
Sales and No Returns
No Sales and Returns
Today, I have to do the following manually:
If Sales and Returns, I add a row to my common import file, one to record the sales and one to record the returns. So one row in the source file becomes two rows in the import file.
If Sales and No Returns, I create one row to record the sale
If No Sales and Returns, I create one row to record the returns, but many of the fields are either null or filled with zero; the fields I mainly care about is the number returned and the negative amount we’re being hit with. The negative value is deducted from both our sales and royalties received.
I apologize if this is overkill. This mapping and logic process is all done manually today. It’s not that complicated because I’ve done it so often, but it’s extremely time-consuming.
Here is a list of the column headers:
Source File Field
Common Import File Field
Notes
publisher_number
Ignore
publisher_name
Ignore
isbn
Ignore
sku
Ignore
parent_isbn
ISBN
title
Title
NULL DOES NOT EXIST
Sales Source
For this file type this field is null in the import file. It is mapped for other files received
NULL DOES NOT EXIST
Author Copy?
For this file type populated with “No”
NULL DOES NOT EXIST
Type of Order
For this file type populated with “Regular”
NULL DOES NOT EXIST
Order Number
For this file type this field is null in the import file. It is mapped for other files received
NULL DOES NOT EXIST
Invoice Number
For this file type this field is null in the import file. It is mapped for other files received
NULL DOES NOT EXIST
Retailer
For this file type this field is null in the import file. It is mapped for other files received
author
Ignore
page_count
Ignore
binding_type
Format
There are three binding types. If “Perfectbound (Trade Paper” then filled with “Paperback”; If"Trade Cloth/Laminate" then filled with Hardcover
book_type_id
Ignore
list_price
Ignore
wholesale_discount_%
Ignore
PTD_Quantity
QTY Sold
PTD_avg_list_price
Average List Price and Unit Price Local Curreny
This is mapped to two fields in the import file
NULL DOES NOT EXIST
Was a Return?
If there is data populated in the PTD_return_quantity, then this field si filled with “Yes” if not, it is filled with “No”
NULL DOES NOT EXIST
Discount Given
For this file type this field is null in the import file. It is mapped for other files received
NULL DOES NOT EXIST
Currency Code
For this file type this field is null in the import file and because I “know” what the currency is, I fill it manually. It is mapped for other file types received
NULL DOES NOT EXIST
Exchange Rate
This is manually filled in the import sheet
NULL DOES NOT EXIST
Unit Offer Price Local Currency
This is manually mapped to PTD_avg_list_price from the source file
NULL DOES NOT EXIST
Total Sale Local Currency
This is a calculated value of Average List Price * Qty Sold
NULL DOES NOT EXIST
Discount Amount Per Unit Local Currency
This is a calculated value of Average List Price * Discount Given, if there is no discount, this is filled with zero
NULL DOES NOT EXIST
Unit Offer Price After Discount Local Currency
This is a calculated value of Average List Price - Discount Discount Amount Per Unit Local Currency
NULL DOES NOT EXIST
Total Sale After Discount Local Currency
This is a calculated value of Unit Offer Price After Discount Local Currency * - QTY Sold
NULL DOES NOT EXIST
Unit Offer Price USD
This is a calculated value of Average List Price and Unit Price Local Currency converted to USD using Exchange rate
NULL DOES NOT EXIST
Total Sale USD Before Discount
This is a calculated value of Unit Offer Price USD * QTY Sold
NULL DOES NOT EXIST
Discount Amount Per Unit USD
This is a calculated value of Discount Amount Per Unit Local Currency converted to USD using Exchange rate
NULL DOES NOT EXIST
Unit Offer Price After Discount USD
This is a calculated value of Unit Offer Price USD - Dicount Amount Per Unit USD
NULL DOES NOT EXIST
Total Sale After Discount USD
Unit Offer Price After Discount USD * QTY Sold
PTD_extended_list
Ignore
PTD_avg_discount_%
Ignore
PTD_extended_discount
Ignore
PTD_avg_wholesale_price
Ignore
PTD_extended_wholesale
Ignore
PTD_avg_print_charge
Ignore
PTD_extended_print_charge
Print Manufacturing and Delivery Charge
PTD_gross_pub_comp
Ignore
PTD_extended_adjustments
Ignore
PTD_extended_recovery
Ignore
PTD_pub_comp
Total Royalty Local Currency
NULL DOES NOT EXIST
Total Royalty Amount USD
This is a calculated value of Totally Royalt Local Currency converted to USD using the exchange rate
NULL DOES NOT EXIST
Notes
For this file type this field is null in the import file and because I “know” what the currency is, I fill it manually. It is mapped for other file types received
YTD_quantity
Ignore
YTD_avg_list_price
Ignore
YTD_extended_list_price
Ignore
YTD_avg_discount_%
Ignore
YTD_extended_discount
Ignore
YTD_avg_wholesale_price
Ignore
YTD_extended_wholesale
Ignore
YTD_avg_print_charge
Ignore
YTD_extended_print_charge
Ignore
YTD_gross_pub_comp
Ignore
YTD_extended_adjustments
Ignore
YTD_extended_recovery
Ignore
YTD_pub_comp
Ignore
deferral_balance
Ignore
reporting_currency_code
Ignore
period_name
Ignore
original_deferral_amount
Ignore
PTD_return_quantity
Qty Returned
SPECIAL HANDLING. If the quantity returned is NOT Null, then TWO rows are created in the import sheet. One row for the books sold and one row for the books returned.
PTD_return_wholesale
Ignore
PTD_return_charge
Ignore
PTD_return_total
Total Royalty Amount USD
SPECIAL HANDLING. If the quantity returned is NOT Null, then TWO rows are created in the import sheet. This field converted to a negative value and mapped to both Total Sale After Discount Local Currency and Total Royalty Local Currency
Sorry to ask to confirm the obvious, @RGYP, but I take it the output fields are the input fields excluding those marked “Ignore”, and with currency conversion or other changes as shown in your Notes?
You show one record. Are additional records vertically stacked, that is, repetition of the Source File Field names and contents in two columns, or is there one set of Source File Field names then a variable number of columns depending on the number of books?
OK, thanks, I will have a look at it. My solution for currency exchange is / will be to add the currency multiplier (1 if already USD) via the clipboard, so the Transform itself would not need modification each time.
Some of your descriptions are unclear, for example creating additional rows (do you mean columns?) or “map to two fields in the import”. Might this file format be in one currency, i.e. is each file-currency unique, or multiples in one?
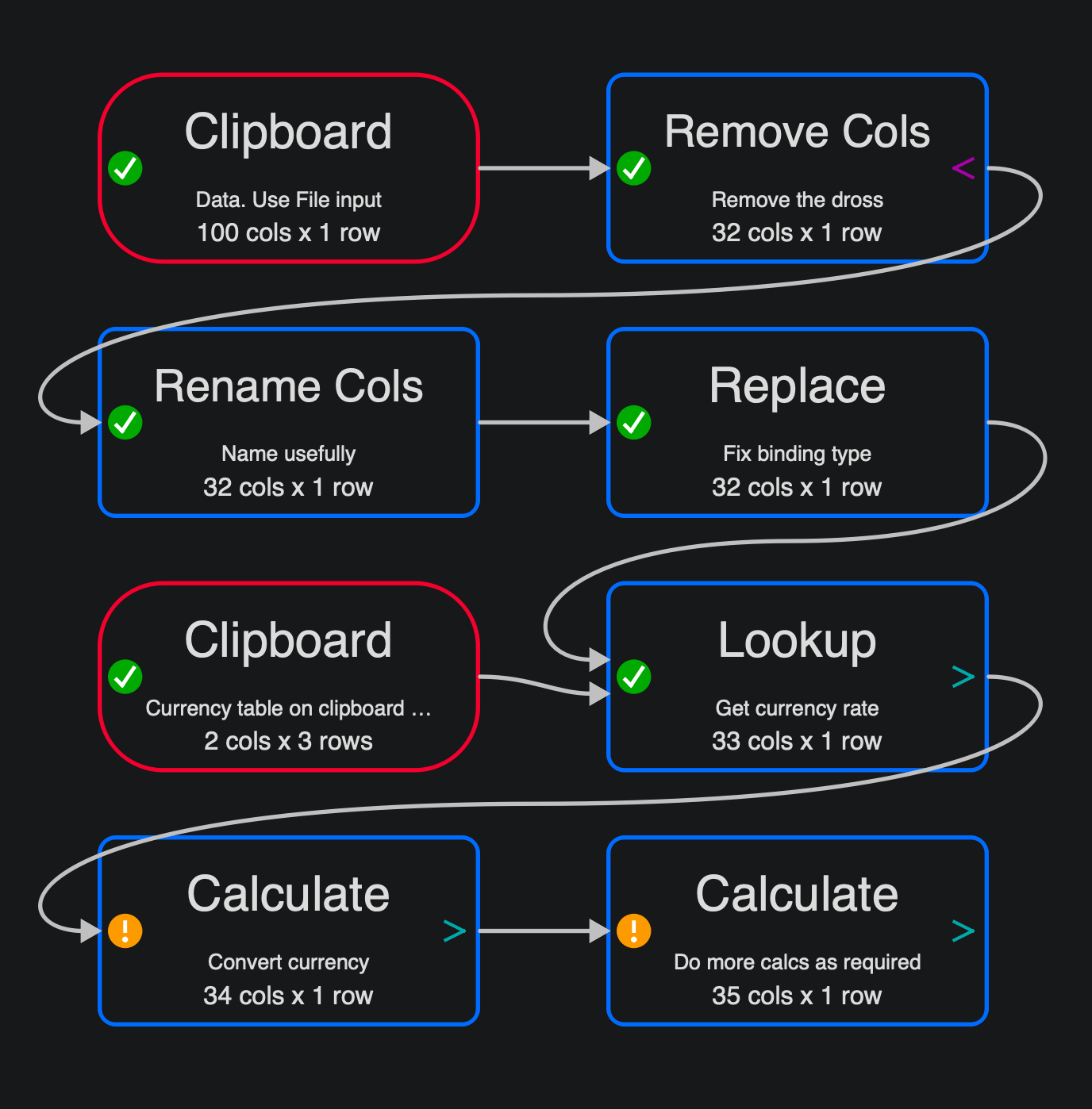
I have drafted a framework of basic operations which should guide additional transformations you will need. Look at the transforms step by step. I have not tried to be comprehensive about renaming columns or doing calculations etc. You will get the gist and can ask here again if there is more you need. An example of actual output desired is always helpful.