I Stacked about 200 files to make one CSV file that is about 75MB in size (130,000 rows X 15 or so columns) . When I try to load the output (the 75MB CSV file) I get an out of memory error/close My preferences has 2GB of memory allocated. Is there some way I can load this file? It seems to me people are loading much bigger files than this. Could there be some other reason it is crashing?
75MB is not a large CSV by Easy Data Transform standards.
Which OS and version of Easy Data Transform is this?
Are you doing any additional transforms? Or just reading in the .csv?
Does it make any difference if you increase the memory in Preferences?
It it possible you can send me the input file (and .transform, if you have one)? You will need to upload it somewhere.
Im using Win 10 and V 1.21.1
I changed the memory allocation to 5.5GB and it loaded (much faster too, about 5 seconds vs 20 seconds to crash out before) I think perhaps the problem is that there is something wrong with the CSV There are dozens of warnings like this:
7095 input rows have 21 values: E.g. input row 48
3404 input rows have 22 values: E.g. input row 90
105 input rows have 23 values: E.g. input row 200
The source was a “Stack” of 93 csvs, exported from a Wordpress Woocommerce database (sales) I used two nodes, removed columns and Stack to make it.
They contain emails so I can’t share it but I may not need to as its loading now so I can continue on.
Thanks for your quick help!
Ok, I think I’ve found the problem. When I Stacked them in the initial transform, the 14 columns end up as 2,800 columns. I will go back to my original transform and try to debug it there,
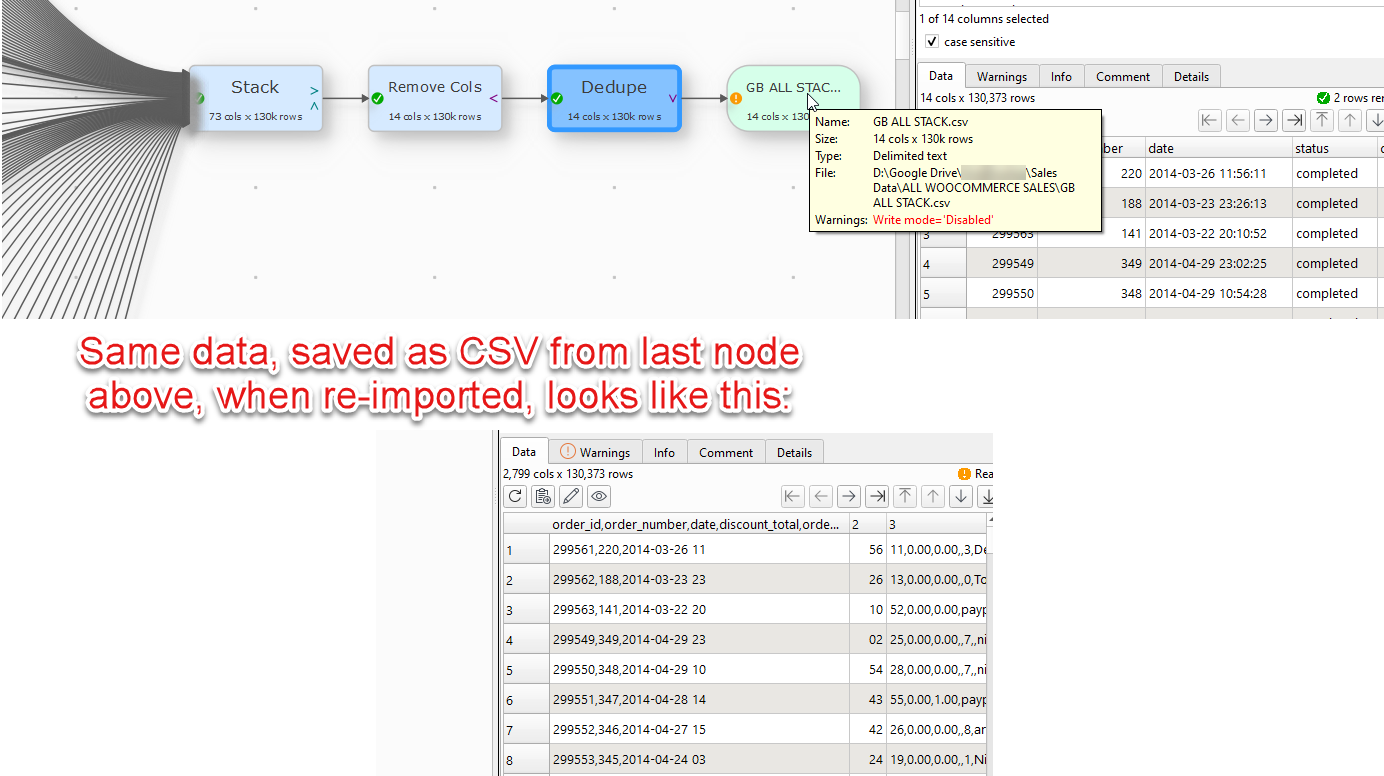
Ok, the mystery continues. Im not sure what the issue is but when I save out my data and re-import the CSV the columns and rows are mixed up (see screenshot)
@Nicolai
2,800 columns x 130,000 rows is a 364 million data points. That could easily use up 2GB of memory!
I am guessing that you are missing a closing quote in your CSV somewhere. Which means that you have a massive row.
The latest snapshot release has much more detailed feedback on stacking. I strongly recommend you install that and look at the output in the ‘info’ and ‘warning’ tabs. See:
Thank you. I am sure you are correct. I don’t know how to find it though.
I have updated now to 1.22
Its odd because I can scroll through all 130,000 rows in the final node of the transform and everything looks perfect but when I re-import the output csv, the columns are all messed up.
There are no errors or notes when I output, but still plenty when I input the exported CSV. This is the beginning (and then it continues like that for about 20 lines)
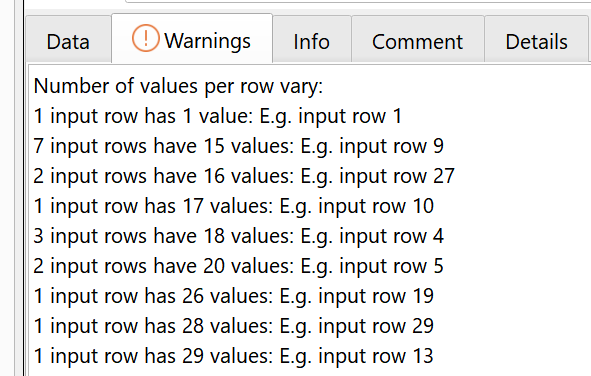
Number of values per row vary:
1578 input rows have 1 value: E.g. input row 1
1 input row has 4 values: E.g. input row 121573…
I’ve opened the file in NotePad++ to see if I can figure out where the quotes might be going wrong but I don’t understand CSV syntax well enough to spot anything egregious. The quotes seem to be in the right places.
There are 164 double quotes in the document, so at least they are even.
Any tips on debugging it? I could try to remove the email addresses column in the previous transform and see if the problem remains and then send you that file but I still couldn’t post the link publicly here.
Thanks in advance for your thoughts
In the original .transform where to stack the CSVs it should show that one of the inputs has a lot more columns than the others. That should give you a clue as to where the problem is.
You need the snapshot release v1.22.1, rather than the latest production release (v1.22.0) to get the additional information:
Windows: https://www.easydatatransform.com/downloads/EasyDataTransform_1_22_1_snapshot_1.exe
Mac: https://www.easydatatransform.com/downloads/EasyDataTransform_1_22_1_snapshot_1.dmg
When you stack your inputs look at the ‘info’ and ‘warning’ tabs of the Stack transform.
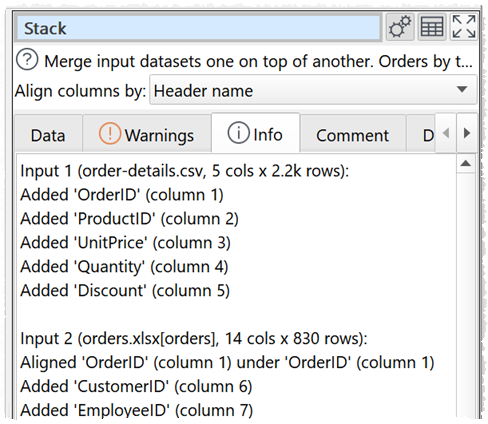
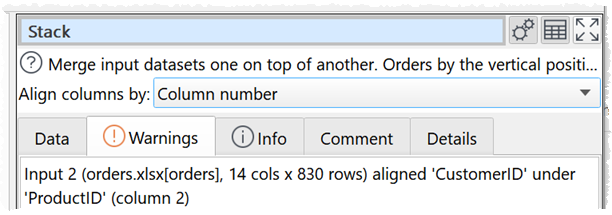
If you get stuck you can email us the rogue CSV file (if confidentiality allows).
Ah yes, sorry! Ok, I installed that one now. One of the inputs has way too many columns; 128!
That could be it. Very useful. Thank you. I will try to fix it in Notepad if I can.
In case it is useful for you, I have deleted the emails from the problem file and uploaded it here. I had to import into Sheets to delete them, and re-export it, so it is no longer the ‘pure’ original CSV, but it still incorrectly shows up as 128 columns instead of the 45 or so it actually is.
Interesting to note: Sheets and other CSV viewers show the correct amount of columns, not 128
128 columns- 128 is an interesting even number 1,2,4,8,…
Yes, I had the same thought when I wrote that
Edit: Originally I said tabs, when I should have said pipes
I checked the file. I think what is happening is:
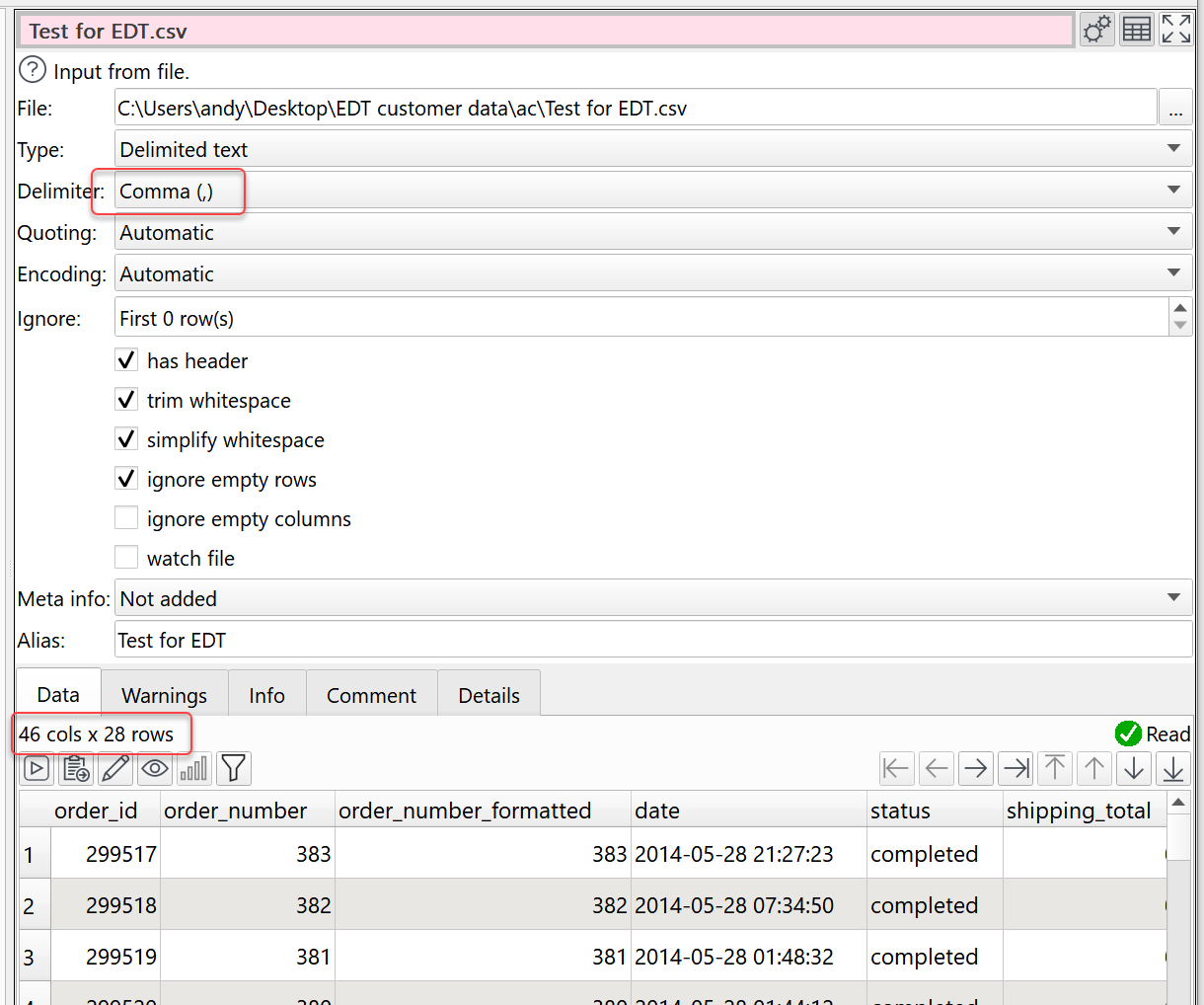
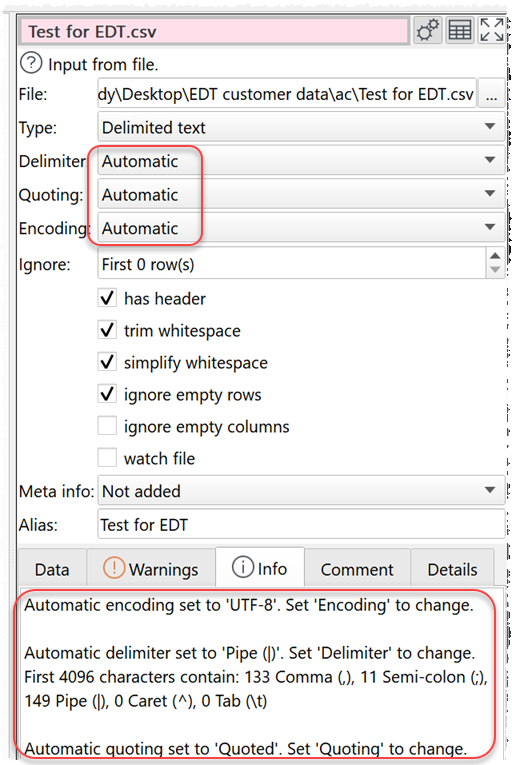
- You have the Delimiter set to Automatic
- Easy Data Transform scans the file and finds 133 commas and 149 pipes (|), and guess it is a pipe separated file, rather than a comma separated file
You can see that the headers look wrong:
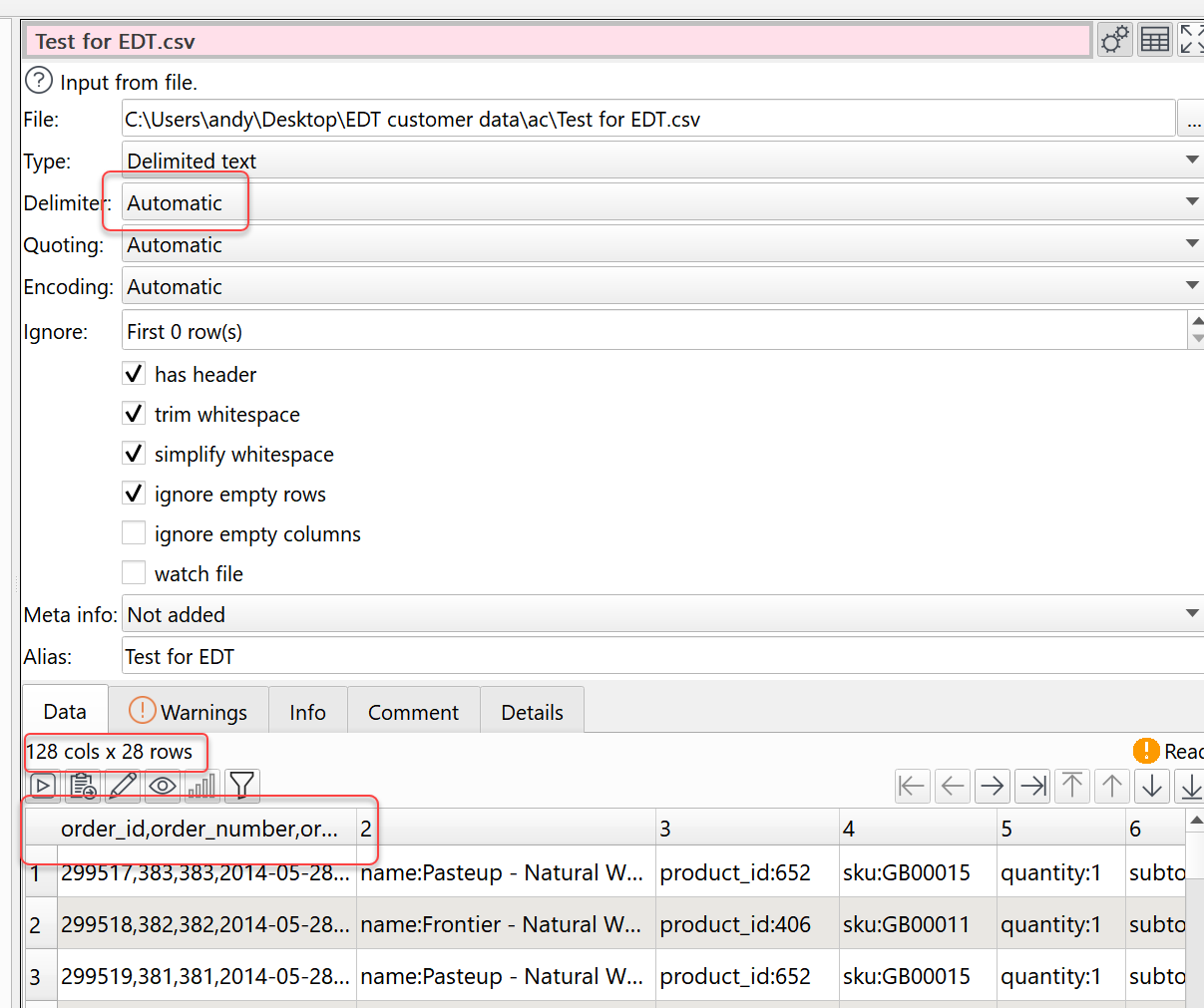
Also the columns are very ‘ragged’ (vary a lot in length):
If you change the Delimiter explicitly to Comma the warnings go away:
Pipe separated files are a thing.
It is impossible to 100% reliably guess the delimiter of a delimited file. Currently Automatic just counts likely delimiters and chooses the one that occurs most often. Usually this works. But occasionally not (as in this case). We could be smarter, for example by trying different delimiters to see which creates the least ragged input. But this would be a lot slower as it means parsing the file several times.
In the short term I will look at adding something in info to say which delimiter Automatic picked. In the longer term I will have a think about taking a more intelligent approach than just counting possible delimiters.
1 Like
I have put some more information in the Info tab, so you can see what is being guessed for each Automatic option:
1 Like
Thank you for this incredibly thorough explanation.
That makes sense and is all very clear. Very useful too.
1 Like
The latest snapshot now has better feedback on what Easy Data Transform guesses when options are set to Automatic: