Ran a quick test. Took a md file with a properly formatted md-table. 4 consecutive slices isolate the table. The problem being that my data disappears when i start filling in the slice fields. So i have to open the file in BBedit to see on what data the slice should trigger. That’s cumbersome. The last slice is to remove the md formatting line, the one with| --: | :------ etc…
The first line of the table starts with \n\n|space and the last line ends with |space space\n\n. But the delimiters disappear in the dataview. If you take one of my files and filter on those \n\n|space for start and |space space\n\n for last line you have all my tables. I have 2 blank lines before and 2 blank lines after every table.
1 Like
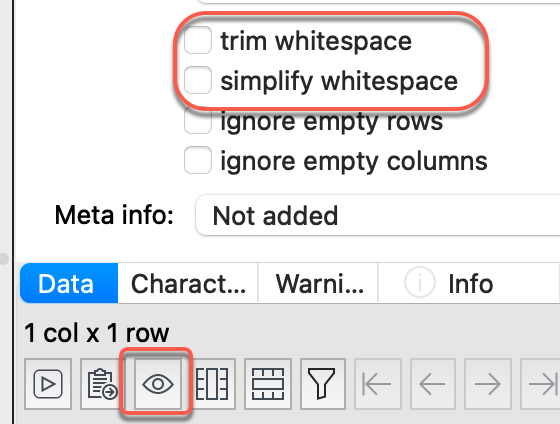
Have you tried disabling trim whitespace and simplify whitespace during input?
You can also click on the eye icon to see invisble characters, such as Line Feed.
Just thinking out loud here. But possibly you could do something like this in the Filter:
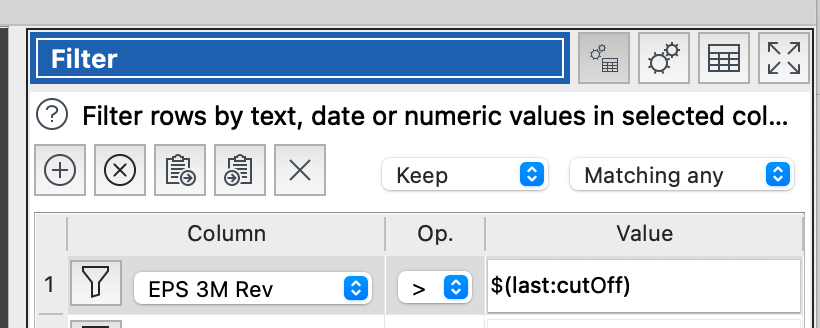
Where $(last:cutOff) means take the last value in the cutOff column rather than the value of the cutOff column for that row.
Yes, that is an improvement on previous options for filtering.
1 Like
More ways to add note or comment
- Being able to use DateTimeFormat regardless of locale. Right now I need to use JavaScript to modify the format of a date where I can clearly see how it looks and give EDT the format, but EDT refuses to change it because of locale. In this case I run Canada, but do get the odd US formatted data to process… Maybe locale per input file?
- Being able to set a singular output file name anywhere in a transform path that carries through to the end based on a (specific) row or JavaScript that can access the whole dataset. Kind of like an “Output variable” that can be set. Maybe even a project-wide ability so I can run one or more branches to pull specific datapoints out of the data and then being able to use them in multiple file outputs as output variables.
I have data with multi-month dates, but the filename should indicate the oldest date only (“Data to yyyy-MM.xlsx”) and have that in the output filename but contain all data. - Being able to copy one or more transforms in a branch and paste them in the same file into a different branch.
2 Likes
Feature Request: Wildcard Support with Newest/Oldest File Selection
I’d love to see a feature that allows wildcard usage for file names in the input data. Additionally, it would be incredibly useful to combine this with a “Newest” or “Oldest” checkbox to specify which file to process—such as the most recently added file in a folder.
Example Use Case:
I have a folder where files are regularly dropped by a scheduled job, and each file includes a date suffix. It would be great if I could:
- Use a wildcard to ignore the date in the file name during ingestion.
- Utilize a checkbox to ensure only the newest file (based on file name or modified date) is selected.
Suggested Workflow:
When paired with the “Monitor Folder” feature for detecting new files, this setup could provide an excellent automation workflow.
While I currently manage this process using Python, I appreciate the simplicity of EDT for quick edits and adjustments to data wrangling flows. Adding this functionality would make it an even more powerful tool!
1 Like
Can you elaborate a bit more?
You can do it already in the batch processing with which you can process multiple files in one rush, very powerful.
1 Like
It is on the wishlist to look into this. I think probably the best way to handle this would be to allow the overriding of the locale in preferences in some transforms, e.g. DateTime format or Num Format. Can you give an explicit example of why you need this, to help us understand. E.g. The output DateTime format currently gives you for a particular input vs what you actually need. Perhaps start a new forum post.
We have some ideas about being able to extract a value from a dataset and then use it as an option value in transforms or outputs. Again, it would be helpful if you could outline a real world example of why you need this. Perhaps start a new forum post.
Copy and paste of items in the center pane is high enough in the wishlist that we didn’t include it here. Note that you can right click Duplicate branch and then disconnect the branch and connect it elsewhere.
As @Olaf says, this already exists in the batch processing feature.
Also high on the wishlist (but not in the survey) is the ability to input multiple files as a single dataset using a wildcard in filename. This would be equivalent to inputting N files and applying Stack, but it would all be done in a single input.
Isn’t that going to be problematic if more than one file is updated at the same time?
We currently have watch file. I can see it would be useful to have watch folder in conjunction with inputting files that match a wildcard.
Vote done.
“Something else:” pivot table with as many row/col we want <3
3 Likes
Noted. It is already somewhere on the wishlist. It would be helpful if you could give 1 or 2 real world examples, to make sure we understand what you are trying to do. Maybe do it in this existing post:
DateTime format currently gives you for a particular input vs what you actually need. Perhaps start a new forum post.
I searched and added my particular issue to an already existing Feature Request:
being able to extract a value from a dataset and then use it as an option value in transforms or outputs
I have opened a new feature request here
Thank you
1 Like
Hopefully SQL database also means Microsoft SQL
Hazel / Keyboard Maestro to rescue ![]()
1 Like
Probably anything we can talk to through ODBC.
1 Like
Having an input option that can accept text/data without it being automatically copied from the clipboard. So like a module for manual data input, as the clipboard is limited in how much it can hold and sometimes creating a file of the data isn’t feasible or able to be done.
How would you add the data to it, if it is too big for the clipbard and it isn’t in a file?
We have considered a ‘scratch’ input where you create an empty dataset with a given number of rows and columns and then type/paste values into the empty cells. But this would only be useable for very small datasets and I’m not sure how useful it would be.
1 Like
variables to be used as a parameter. By example: a logical variable that can be accesible in an IF transform or a date