We have created a new video to show you how to handle schema drift (changes to column structure over time):

Youtube ‘likes’ help us to be more prominent and are much appreciated.
Subscribe to our Youtube channel to be notified of future videos.
We have created a new video to show you how to handle schema drift (changes to column structure over time):
Youtube ‘likes’ help us to be more prominent and are much appreciated.
Subscribe to our Youtube channel to be notified of future videos.
Some considerations on the schema shifts and name column name changes.
The schema functionality in the input transformation saves additional stack transformations and it enables to read in only necessary columns in the first step. After checking the video, I got more aware that EDT internally the columns are treated based on the column number and not the name, even knowing it already. So not using the schema different column names don’t matter if the order is the same.
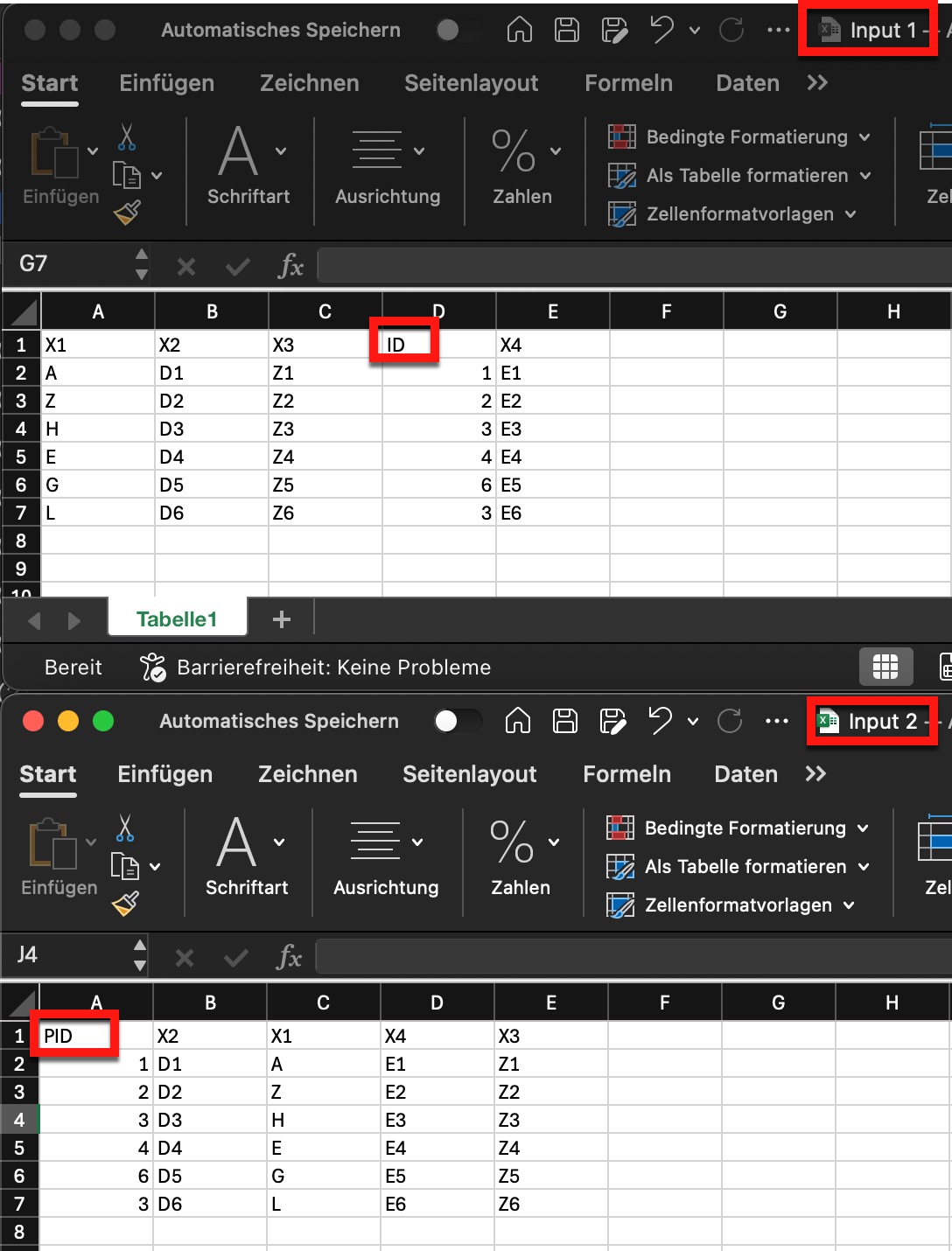
I had in the past the problem with different order, so no issue using the schema or stack (in V1 of EDT). But I had the problem in case of some input files delivered, that the order was not stable and for some field a different title was used. In my case luckily it was a stable (and after a while known) differences like “ID” and “PID”. In the past I had to open all input file and checked the headers. Know I tried to find a different approach.
So, I simulated in the first with the following 2 input files:
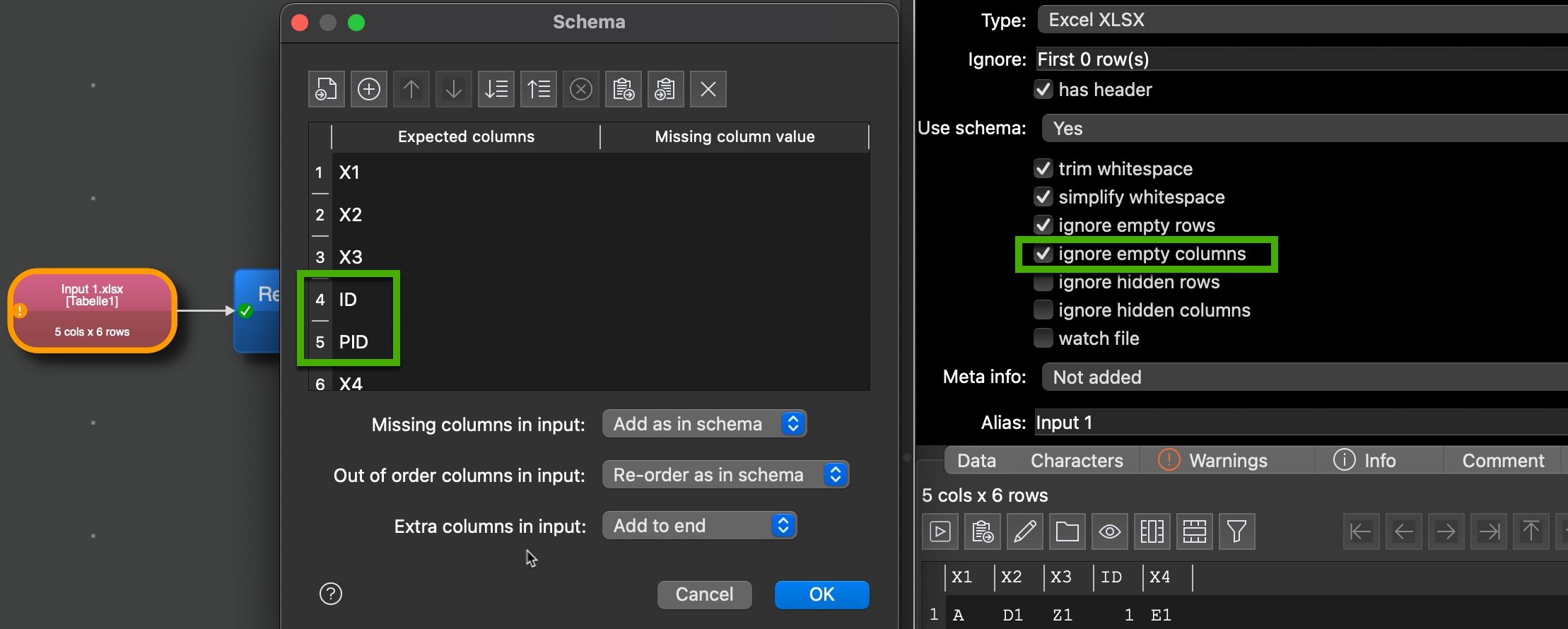
And used the following schema:
By using the “Ignore empty columns” I got a stable output with 5 columns in the correct order. One of the two coumns ID or PID is empty and therefore ignored. A following rename of PID to ID shows for both input files the same result as the rename is ignored in case of “Input 1” With columns name ID.
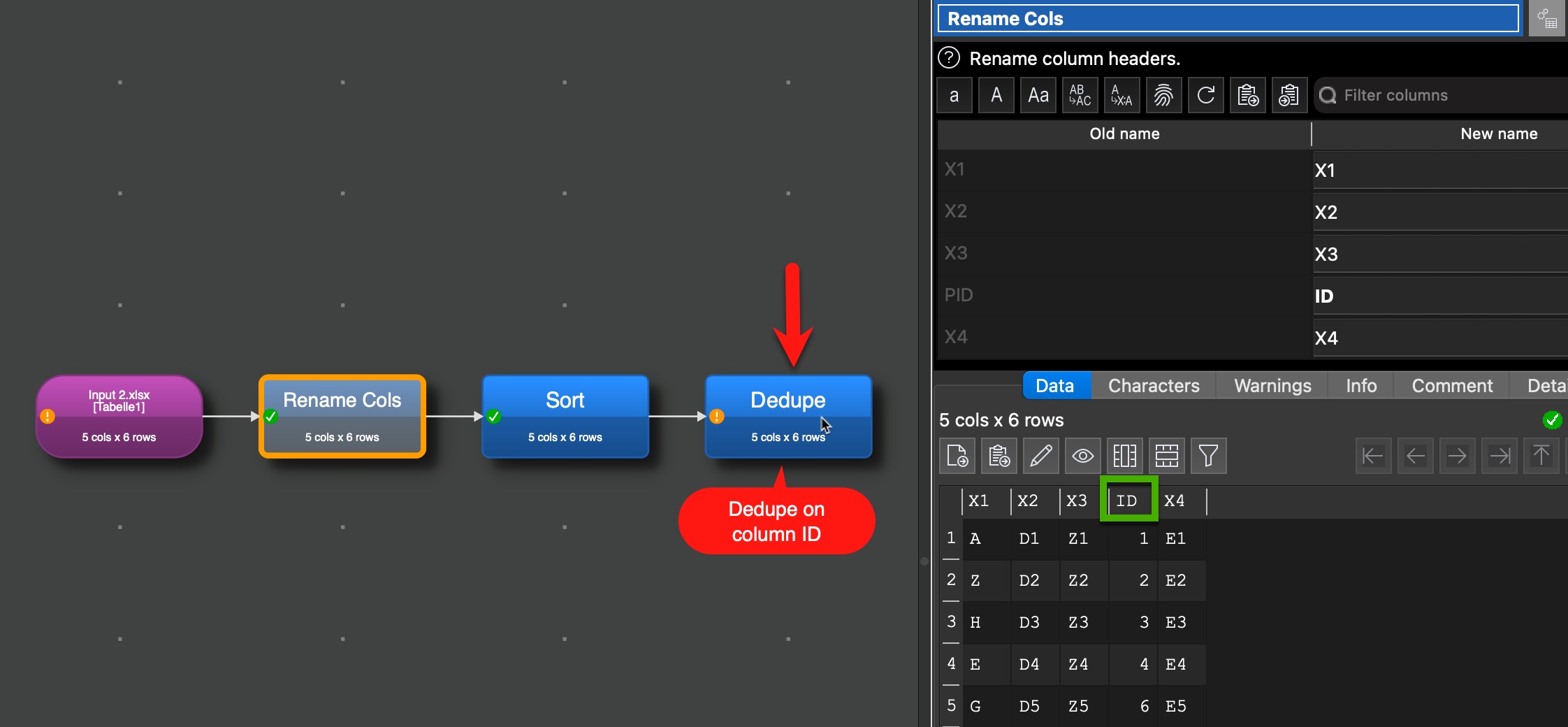
The following Sort works as it sorts the first columns “X1” which is before the treated columns 4 with the ID fileds. But the Dedupe on the ID column fails as EDT internally a column number for ID and PID exists (@Andy, I assume that is the reason) and therefore the reference to the column is lost.
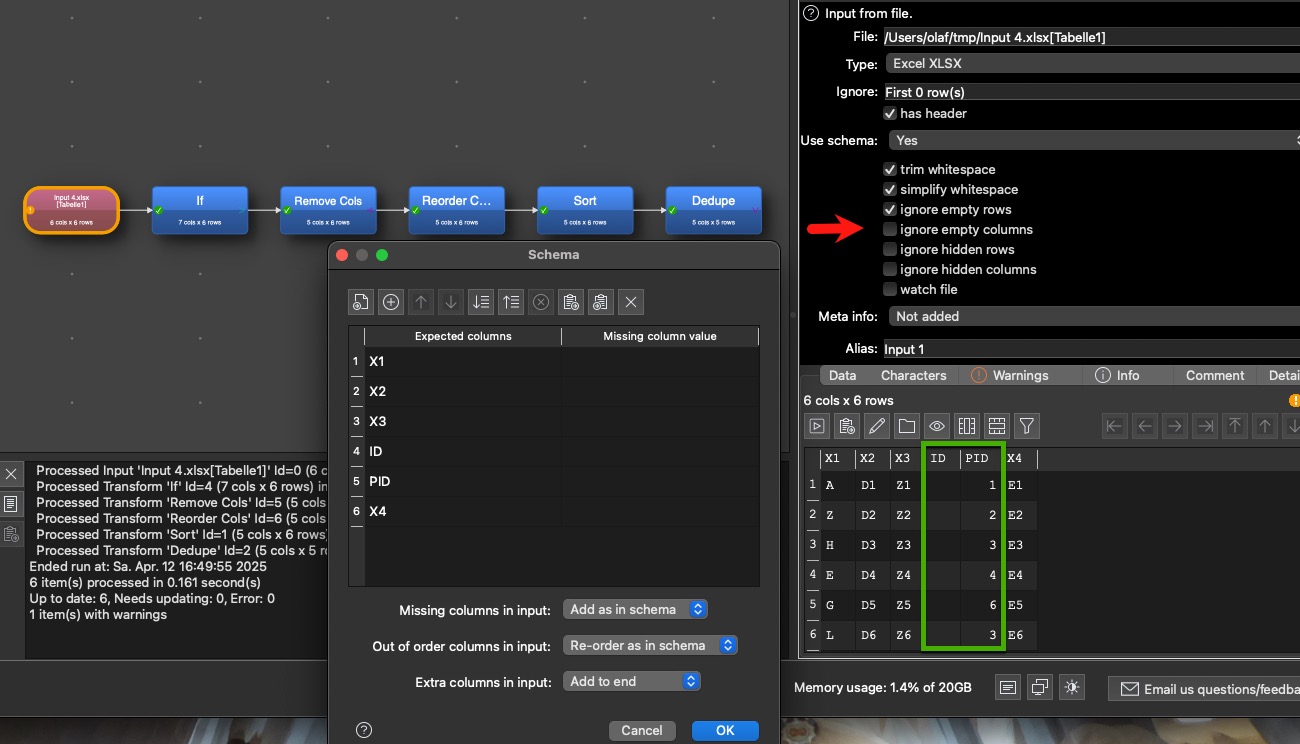
I had to think about a different solution. I changed the approach and read in both columns and removed the “ignore empty column” selection:
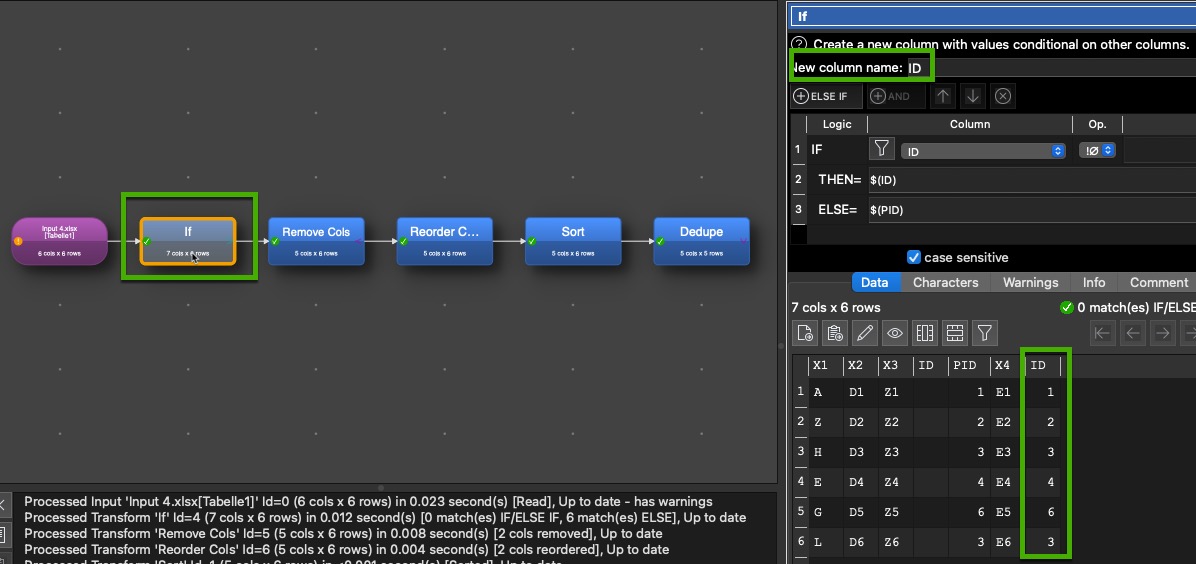
Know I create with an If transaction a new ID field:
Remove afterwards the first read in ID and PID columns and reorder the fields. Now the following transformations do work stable for different input files. With changes of order and both different column names (ID and PID). I attach the 4 different small input files I used and the first try of transformation “Field_mismatches.transform” leading to problem and the final stable version “Field_mismatches_stable.transform”. Maybe this helps others in case similar issues come up.
@Andy, is there any other solution I don’t see avoiding the “If”? I’m clear that in case of unknown changed column names and changed order there is nearly no chance.
Field_mismatches.transform (3.1 KB)
Field_mismatches_stable.transform (3.7 KB)
Input 2.csv (99 Bytes)
Input 4.csv (99 Bytes)
Input 3.csv (98 Bytes)
Input 1.csv (98 Bytes)
I had to change the Excel format of the input files to CSV to get them loaded, even the transform files expect Excel format.
that EDT internally the columns are treated based on the column number and not the name
It’s a bit more complicated than that. ;0)
I don’t recommend using ‘ignore empty columns’ here. Because that might delete the column you are trying to reference.
In the situation where you might have a column called ID or PID and you don’t know what order they might be, I recommend you do this:
Does that help?
That‘s what I did in the „stable“ version. Thanks for the confirmation.
I tried to load the examples. But it was a bit fiddly due to the CSV/Excel issue.