i’m looking at a dataset that is an export from what looks like an old system. after much manipulation, i’ve got the end result that i want. and it was a fun puzzle getting there because i wanted to do it all here instead of going to a spreadsheet software for some parts of it.
this is what i’m working on. the contents of the [description] field originally appeared as separate line items. so this is what i did.
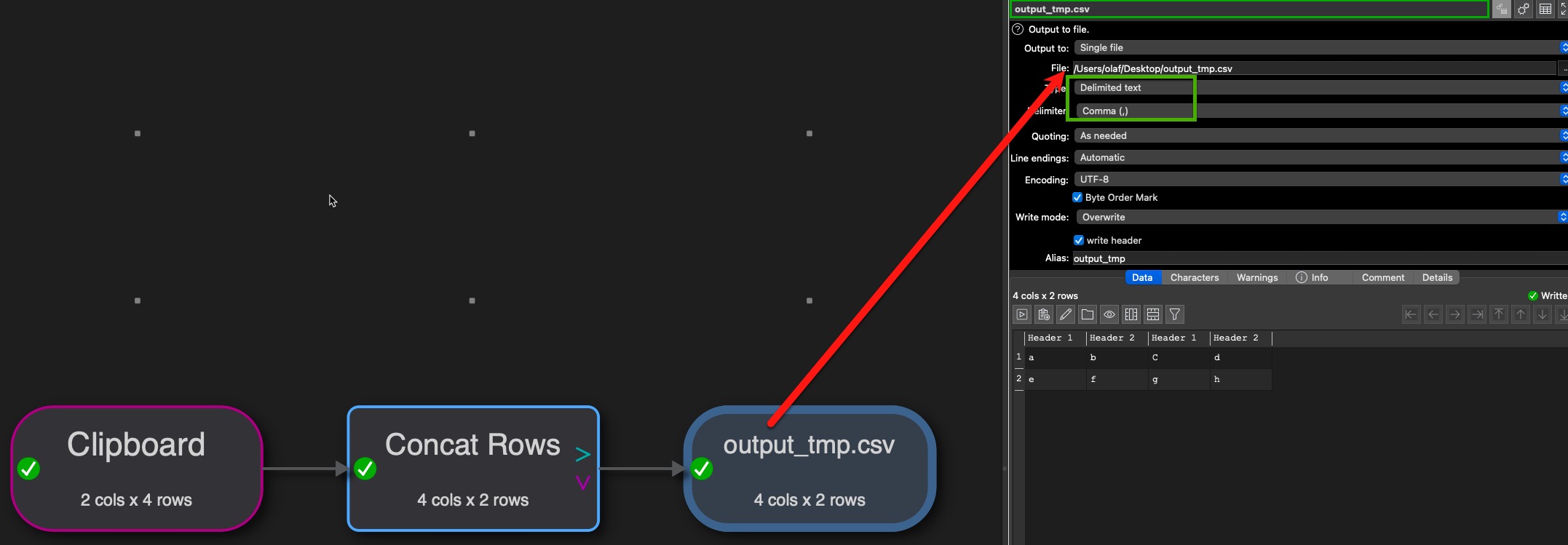
i used Concat Rows to convert them to separate columns.
i used Concat Cols to combine them add the result to a new field.
and finally, i used Filter to select just the key and the new concatenated field.
my question:
when i use Concat Col and use the “select all columns” button, is that button just a ui command, or in the code is it actually a “select all” command?
i’m guessing that it’s just ui. i’m asking because the number of rows that i have for the description will vary. and i don’t know the maximum number of rows that will make up the concatenated [description] field. i figure if i have to manually select the fields, then my setup won’t be as easy as just selecting the input file each time to come up with the desired end result.
in other words, it works now when i know the maximum number of rows so that i can manually select them when i concatenate the columns; and when i know that, in the filter step, i can choose to filter for the concatenated field that has the unique field name based on all of the fields that were concatenated.
my sample dataset has 23 rows. the prospective client’s dataset has 100,000+ rows. so that’s why i don’t know how many rows to expect for this description field.
i’m looking for a robust way that can dynamically take into account the varying row count (for the description field) without having to manually go back in and manually make changes (that seem like a hard-coded setup instead of a variable setup).
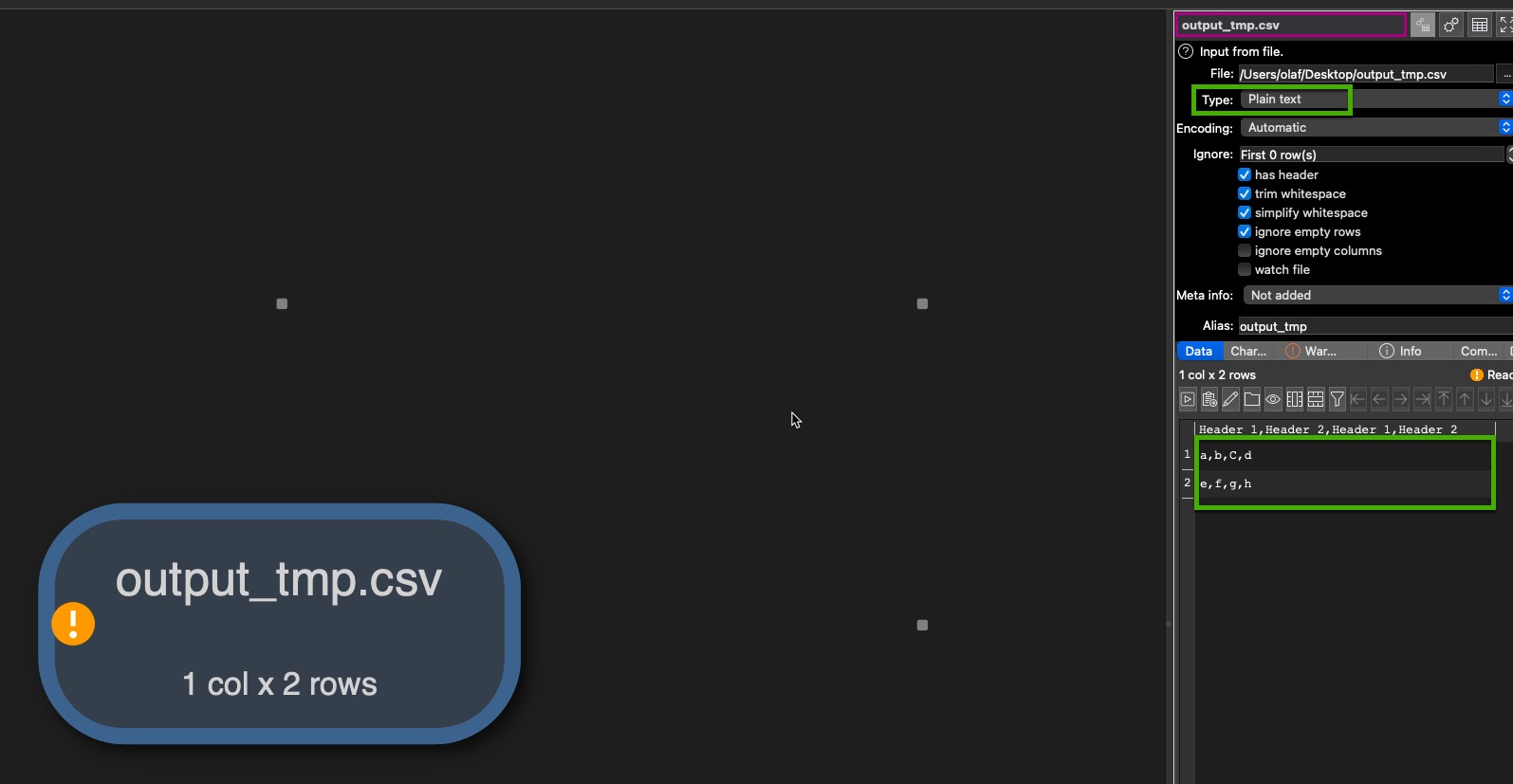
I’m not sure if I get your problem correctly. But I would suggest write the result of your Concat Rows into a csv file. This you read in in a second EDT transformation with type “plain text”. This results in one column dataset, independent of the number of columns.
When you ‘select all’ in Concat Cols it selects all the columns at that instant in time. If you then change the input dataset to one with more columns, those columns won’t be selected.
We are considering for v2 an option to say whether you want additional columns included or excluded for transforms such as Concat Cols.
100,000 rows isn’t that many rows for Easy Data Transform to deal with (it can handle millions). So you could just work with the whole dataset.
Your other option is to work with a sample dataset that is going to create at least as many columns as you expect from the full dataset.
When you ‘select all’ in Concat Cols it selects all the columns at that instant in time. If you then change the input dataset to one with more columns, those columns won’t be selected.
that’s what i suspected. thanks for the confirmation.
We are considering for v2 an option to say whether you want additional columns included or excluded for transforms such as Concat Cols.
it would be nice if there were an option to “select all” that actually selected all of the columns (or rows) without knowing how many there were and then created a new column that always had one unique label name (for easier referencing in future transforms) like “Concat Cols All.”
100,000 rows isn’t that many rows for Easy Data Transform to deal with (it can handle millions). So you could just work with the whole dataset.
based on everything that i have read on the web site and in many of the posts in this forum, i did not expect the 100k rows to be an issue. i mentioned it to note that i could not easily spot check (because of the size) and figure out what the maximum number of rows (that i need to concatenate) would be.
but based on your comment, i’m assuming/wondering if edt would automatically show me the max number of rows once i supplied the entire dataset. if so, i would understand that to still mean that if i had a different 100k dataset later, then i would have to go through the steps again so that i could manually select the columns to concatenate and select the resulting concatenated field.
doing this small part manually is not a big deal. i’m also doing this as a mental exercise and an edt exercise so that i know how to do something like this in edt in the future in a more complex setup.
i can’t visualize what your suggestion will do. not enough practice yet.
i’ll try it and see what i end up with. for some reason, it escaped me that i could easily and strategically export interim parts and then strategically import those parts where i needed them. on the surface, i’m not sure what i gain from that. for example, filtering out two datasets in two string of nodes and then joining them all in the canvas VS outputting one of those datasets and then importing it later before joining them.
maybe you can share with me an example when it is definitely advantageous (to my beginner’s eye) to export and then later import.
Possibly. But often people want to concat column N onward, rather than all columns, and it wouldn’t help with that. Also, whatever we we come up with has to be easy to understand for users.
It will. But a different dataset might end up creating more columns.
You would.
You other options is to create a synthetic dataset (maybe only 1 row) that is going to generate more columns than any real dataset ever will. Use that to create the .transform. Any real dataset that creates less columns will then not be a problem.
You other options is to create a synthetic dataset (maybe only 1 row) that is going to generate more columns than any real dataset ever will. Use that to create the .transform. Any real dataset that creates less columns will then not be a problem.
that’s where my mind was going next. in the canvas i was going to create a row for that purpose and then remove it after it served its purpose. i’m glad to see this suggestion also coming from you.
this is definitely advantageous to me for this project.
i’ll be thinking more about how i could make this even more robust (i.e. hands-off). i’ll next be looking at how i can create a checkpoint that will alert me (somehow) when the rows in the raw data (that will be converted to columns) is greater than the number columns in my fake row of N columns.
My idea was to do your first step like concat rows, afterwards I understood you want to have all rows in one column. To do so, as you don’t know the number of columns, write the result of the first step into a file:
The read data is now in one column independent of the original number of columns, based on this you can do your further actions. You can even join in the second transformation file the original data in columns if you export those into a different temporary file.
At least for me is is not unusual to have multiple graphs with intermediate out to get the intended results. Using such dependent graphs productive, you can put them in scripts so that the sequence is executed without intermediate action.
It is also on our wishlist for v2 to allow the user to verify data.
E.g.:
Data is 10 columns.
Column 2 is called ‘value’.
Values in column 3 are greater than the corresponding value in row 4.
In a future release we might look at making it easier to do this in one .transform file. For example there could be a special ‘before’ connection between an output and an input which means that it has to calculate the output before it reads the input.