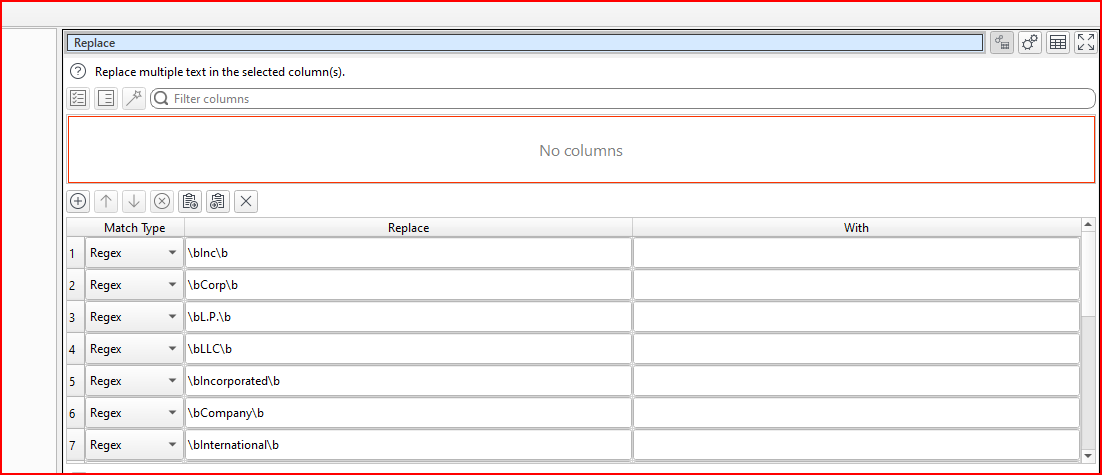
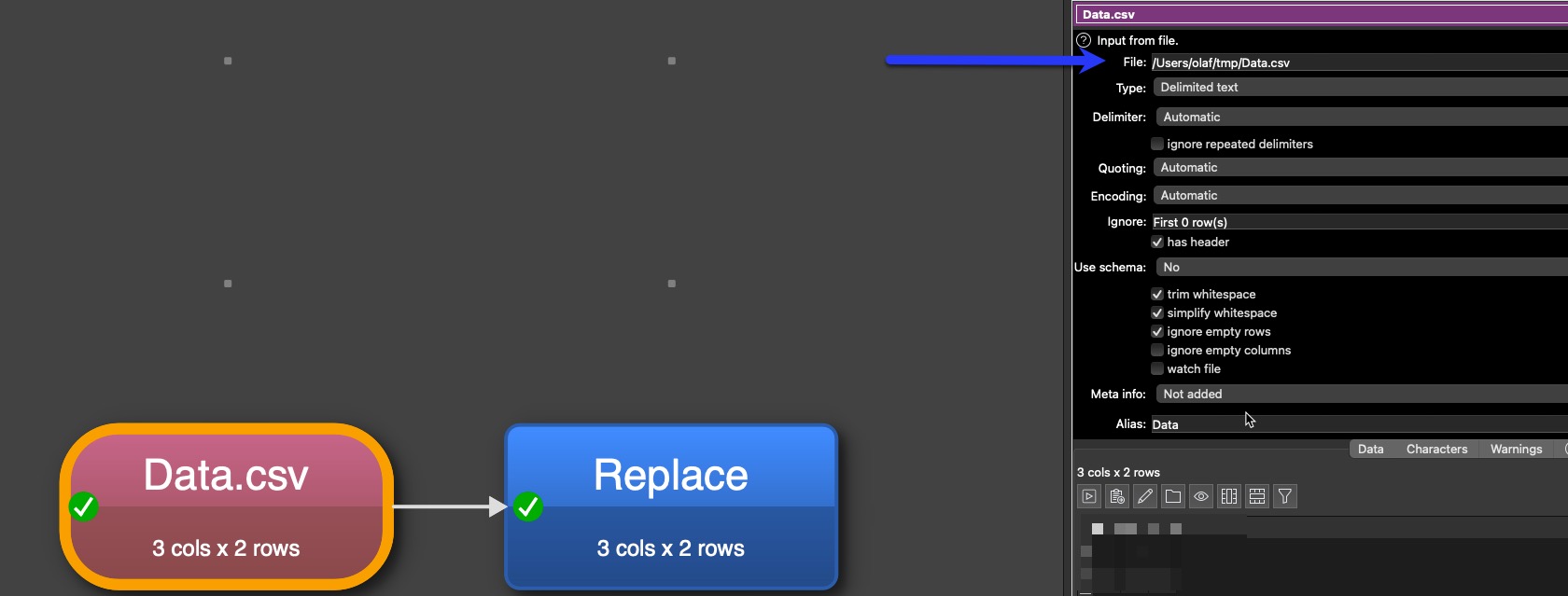
Are you able to show the transforms, for context, rather than just the content of that Replace please? I do not yet know how your data is supposed to arrive there.
And when you have a different input file you can not take the transformation to the new input, it loose the information to the columns in which the transformation should execute something. You need just to change in the “Read” transformation the file name, don’t add a new input file, it will not have a link to the next transformations. Change of the input file in the first transformation will only work in the following transformations if you have identical column names (or columns order).
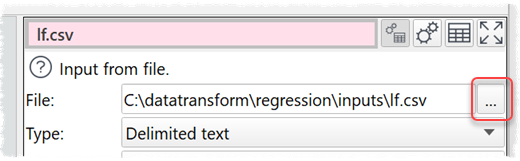
If you have a .transform file and you want to re-use it with a new input file, you should:
-select the input item
-in the Right pane click on the browse button to choose the new input file