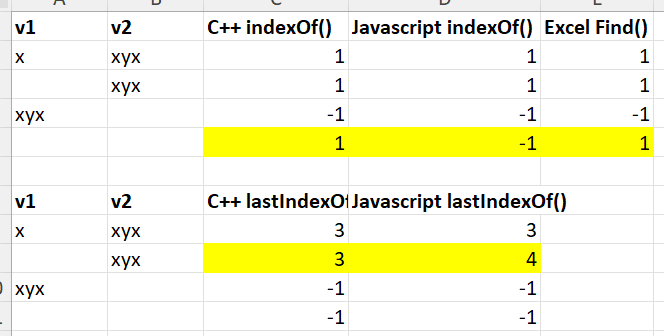
I looked at how C++/Qt, Javascript and Excel Find handle this. It is a bit of a mess!
The C++ and Javascript functions are 0-based and the Excel function is 1-based. I have decided to use 1-based indexing as it is more friendly to non-programmers. There is no built in Excel equivalent of lastIndexOf(). If I modify the table to make all the indexes 1-based and return no value as -1, for easier comparison, I get:
Discrepancies are shown in yellow. I think you can make a philosophical/practical argument that all of them are incorrect or inconsistent.
Does “xyx” contain the empty string? I guess. At what index? 0, 1, all, none? 1 seems reasonable, except that “x” is at 1.
If “xyx” returns 1 for the first index of empty, what does it return for the last index of empty? If it returns 3 that seems wrong, because “x” is at 3. If it returns 4 that seems wrong because the text is only 3 long. If it returns -1 that seems wrong as it isn’t consistent with returning 1 for the first index.
Does the empty string contain the empty string? I guess. At what index? Can’t be 1, because there is nothing at index 1. Also that might not be a useful result to pass to other transforms.
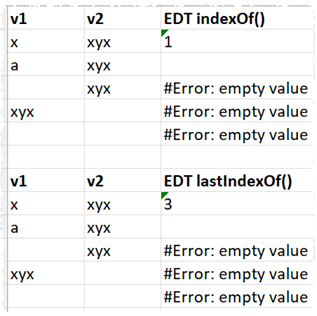
So I am currently planning:
If either string is empty, return an error.
If there is a match, return the 1-based index
If there is no match, return an empty value.
Now is your chance to persuade me otherwise.
I want to get this right before the production release, as changing it later on can break user’s .transform files.
Additional question on the result of such calculation. Sometime I need to extract something from a string in dependency of a calculated value, like IndexOf. The extract transformation excepts in Length and Offset only fixed numbers but no values from other columns. Is it possible to extend this? Or do I overlook something?
with 0, we will know that no match found either genuine or because of empty string, either way the searched value is not found.
This will help in If or JavaScript transform, if we compare it with 0 we will know for sure no match found whatever the case might be either it was empty string or really not found.
Also if that Index value is used in some calculation, then in addition or minus zero will have no effect, only the multiplication will make the value zero, again this will help in the comparison logic to take appropriate action.
So my vote is for Zero in case of empty string or not found, since this column will always have numeric value, so zero will fit right in.
Currently Extract can only use fixed values. In the future we may allow it to use a value read from a column. Until then you might have to use the Javascript transform.
I’m not convinced it is a great idea to return the same thing for invalid values (either string empty) as no match. That sounds like a recipe for hard to find bugs.
But you can always use an If to turn the error code into a 0 if that makes sense in a particualr context.
Currently Extract can only use fixed values. In the future we may allow it to use a value read from a column. Until then you might have to use the Javascript transform.
How it is different from -1 if nothing is found? if value is more than zero that means string found and if not that mean it is not found, so either it be a zero or error or -1, it means string not found and beside, the value will be in the same column of Calculate, so how it is hard to find bug?
If it is zero I have to use only one condition to know string is not found and it will make processing faster, instead of checking for different values to know if it did not match because of error (due to empty string).
Or you can use Zero for actual non matching for value1 and value2 strings and -1 for value1 empty string and -2 for value2 empty string and -3 for both value1 and value2 empty string.
This way by looking at the values in the column, one can know where it matched, where it did not and which value had empty string.
A match, a non-match and invalid parameters are qualitively different things and I think they should be treated as such. Returning 0 in two of the cases means that they look the same. Also it would be easy to not think about invalid parameters or non-matches and get an incorrect result, which might be hard to spot.
If you really want a non-match or invalid parameters to return 0, you can do it with an extra If.
I’ve probably already spent way too much time down this rabbit hole. I will make a decision soon.
Fine as I stated before, for non match use zero and for invalid parameter (regardless in value1 or value2 or both) use -1
My thinking process was, that no match or no value eventually means the same that searched string is not found, so having single value zero will remedy both, as I am not interested here to know if the parameter had error or not, I am interested where the string I am searching is found or not.
Getting error serves no purpose and since EDT is visual, I should make sure that the values in the column that I am searching and the values in which I am searching have proper values before hand by inspecting the transform just before the Calculate (indexOf) and I am expecting value of the position of string found or zero if not found even it was due to missing value or any other error.
But if still see that it is must to provide error for empty values, then use value -1 for any error. This way it fulfills, match (> 0 value), no match (0 value) and error (-1 value).
However it shouldn’t be hard to add to Calculate 2 extra operations:
indexOf - Returns the index position of the first occurrence of the string2 in string1. Returns -1 if string2 is not found.
lastIndexOf - Returns the index position of the last occurrence of the string2 in string1. Returns -1 if string2 is not found.
This what you said and I agree with that, if string found return position and if not whatever the case might be return -1
Exactly my point. EDT is not a programming language and it is visual (which is great) and it should make it simple as much as possible, because most of the users want things done fast and in simple way.
So having positioned returned in case of success and zero or whatever value in case of failure for whatever reason, is most straight forward and simple.
Just for my understanding, can you give example where it is beneficial of having error returned? in a column which suppose to show the position of the string found or not.
This is the same as Excel FIND() and differs from Javascript indexOf() (ignoring difference in indexing) only for “”.indexOf(“”) which returns -1.
LastIndexOf() v1 in v2:
v1
v2
LastIndexOf(v1,v2)
1
aba
aba
4
a
a
1
a
aba
3
x
y
world
hello world
7
This differs from Javascript lastIndexOf() (ignoring difference in indexing) only for “”.indexOf(“”) which returns -1.
Conceptually the index is the 1-based index of the first (IndexOf) or last (LastIndexOf) position where, if the V1 is removed from the found position, it would have to be re-inserted in order to revert to V2. Thanks to layer8 on Hacker News for clarifying this.
None of the above combinations of V1 and V2 are errors, so I have just left it blank where there is no result.
Now I’ve spent enough time down this rabbit hole and need to get on with something else! If you don’t like it you can always add an If with Calcuate or use Javascript to get the result you prefer.
I am just not able to understand, why make it hard for a transformation whose job is to report the index present or not that is all to it.
If it is present, get the position (1 based) and if not return blank or zero or -1 or whatever you decide, but don’t bring 1 for empty string searched in a string or empty string searched in empty string, just because C++ or this or that does it, if they got it wrong, does not mean you have to follow their wrong.
And each new extra transform adds on extra time and memory consumption when number of records are in millions.
It’s not about me liking or not liking, I just don’t understand why make a simple thing, complicated and have to address that complication by adding extra transform in the solution to cater or handle it.
Then please be consistent with Excel one million row limitation as well, because many people are used to it also.
The reason EDT is better because it breaks away from the limitation, you don’t have to bring what is wrong in other software’s, just because people are used to it, they are already suffering in those software’s, why one must continue to suffer in EDT as well.
That is my point, EDT is better and I don’t like it to bring the same wrong in here just because it is norm or people are used to it, people learned EDT did they not and find joy (at least I do) working with it.