/* ───────────────────────────────────────────────────────────────
formatAndValidateAddress1 –
Will try to see if an address1 field contains a valid street and possibly
correct formatting if its wrong. Will return a null if its invalid.
Paste into a “JavaScript” node and end the script with:
return formatAndValidateAddress1($(Address));
(replace Address with your column name)
─────────────────────────────────────────────────────────────── */
function formatAndValidateAddress1(input) {
if (typeof input !== 'string' || !input.trim()) return null;
/* 0. LIGHT PRE‑CLEAN ------------------------------------------- */
var s = input.replace(/^[\s"']+|[\s"']+$/g, '') // outer quotes
.replace(/^[#!]+/, '') // leading !/# noise
.replace(/[.]/g, '') // drop dots
.replace(/\s*,\s*/g, ' , ') // mark commas with spaces
.replace(/\s+/g, ' ') // collapse spaces
.trim();
/* turn every “,” into a space *except* inside “PO Box …” patterns */
s = s.replace(/\s*,\s*/g, ' ');
/* 1. INSERT MISSING SPACES ------------------------------------- */
s = s.replace(/(\d)([A-Za-z])/g, '$1 $2') // 1229East → 1229 East
.replace(/([A-Za-z])(\d)/g, '$1 $2') // AptG4 → Apt G4
.replace(/\b([nesw](?:e|w)?)(\d)/gi, // nw9th → NW 9th
function(_,dir,num){ return dir.toUpperCase()+' '+num; })
.trim();
if (s.length < 6) return null;
/* 2. NORMALISATION DICTS --------------------------------------- */
var suffixMap = {
STREET:'St', ST:'St', AVENUE:'Ave', AV:'Ave',
ROAD:'Rd', RD:'Rd', BOULEVARD:'Blvd', BLVD:'Blvd',
LANE:'Ln', LN:'Ln', DRIVE:'Dr', DR:'Dr',
COURT:'Ct', CT:'Ct', TRAIL:'Trl', TRL:'Trl',
PARKWAY:'Pkwy', PKWY:'Pkwy', CIRCLE:'Cir', CIR:'Cir',
PLACE:'Pl', PL:'Pl', SQUARE:'Sq', SQ:'Sq',
LOOP:'Loop', TERRACE:'Ter', TER:'Ter',
WAY:'Way', HWY:'Hwy', HIGHWAY:'Hwy',
CR:'Cr' /* County Road */
};
var directionalMap = {
NORTH:'N', SOUTH:'S', EAST:'E', WEST:'W',
NORTHEAST:'NE', NORTHWEST:'NW', SOUTHEAST:'SE', SOUTHWEST:'SW',
N:'N', S:'S', E:'E', W:'W', NE:'NE', NW:'NW', SE:'SE', SW:'SW'
};
var unitMap = { APARTMENT:'Apt', APT:'Apt', SUITE:'Ste', STE:'Ste',
UNIT:'Unit', FLOOR:'Fl', LOT:'Lot', BLDG:'Bldg' };
var tokens = s.split(' ');
var out = [], suffixSeen=false;
function splitSuffixGlue(tok){
var up = tok.toUpperCase();
for(var i=2;i<=6;i++){
var tail = up.slice(-i);
if(suffixMap[tail]){
out.push(tok.slice(0,-i));
out.push(suffixMap[tail]);
suffixSeen = true;
return;
}
}
out.push(tok);
}
for(var i=0;i<tokens.length;i++){
var w=tokens[i], up=w.toUpperCase();
if(suffixMap[up]) { out.push(suffixMap[up]); suffixSeen=true; continue; }
if(directionalMap[up]) { out.push(directionalMap[up]); continue; }
if(unitMap[up]) { out.push(unitMap[up]); continue; }
splitSuffixGlue(w.replace(/^([A-Za-z])/, function(m){return m.toUpperCase();}));
}
/* add “#” before digit‑only token that follows a unit word */
var unitKeys=['Apt','Ste','Unit','Fl','Lot','Bldg'];
for(var u=0;u<out.length-1;u++){
if(unitKeys.indexOf(out[u])!==-1 && /^\d/.test(out[u+1]) && out[u+1].charAt(0)!=='#'){
out[u+1] = '#'+out[u+1];
}
}
var cleaned = out.join(' ');
/* 3. VALIDATION (lenient) -------------------------------------- */
var startsNum = /^\d/.test(cleaned) || /^\b[nesw]\b \d/i.test(cleaned);
var looksLikeBox = /^\s*(po|p\.?o\.?)?\s*box\b/i.test(cleaned);
if(!startsNum && !looksLikeBox) return null; // must start with # or “Box”
/* reject obvious non‑addresses */
if(/@|\.(com|net|org|gov|edu)$/i.test(cleaned)) return null;
return cleaned;
}
/* ---- Easy Data Transform call (only this line goes last) ---- */
return formatAndValidateAddress1($(Address));
Looks useful, thanks.
I tried it for List of real addresses · GitHub plus a few extra bogus rows.
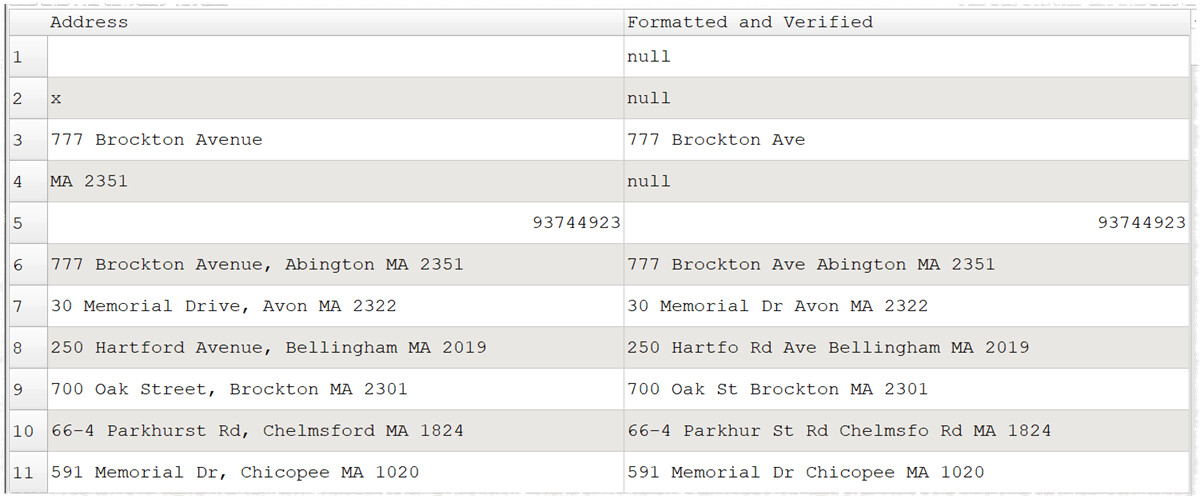
addresses.transform (25.4 KB)
It looks like it is mostly written for US addresses.
In some cases I would think you probably want to keep the comma between street, town, state etc.
Hi,
Most of my jobs require USPS addresses to be formatted correctly and accurately parsed (according to USPS standards). The US Post Office has (as does Canada, the UK, Australia and several European countries) a database of all their currently deliverable addresses, and how they should be written. Thie US information is available from ZIP Info (www.zipinfo.com). They can supply a current copy of the US postal database (updates every month).
They also offer a .dll in their SDK package, so, with a little coding (they offer samples in various languages) to identify matches between your file and theirs. You can easily use it to correct and replace any faulty data. If a US address ZIP+4s correctly then it is golden. (You may have to run it against the NCOA database to see if the recipients on your list still receive mail at the addresses you have for them, or if they have moved. It will also provide a new address if that’s the case.)
I found all this very useful for my work. The mailing industry uses these standards extensively to make sure the mailer won’t pay out a lot of postage for mail that will never be delivered or was missed by their deduping processes and will be delivered too many times.
Cheers…
1 Like
I think it might be better to do this sort of address verification by calling an online API, when Easy Data Transform supports that. However, zipinfo.com doesn’t seem to offer that as a service.
You’re absolutely right. Most services offering address validation typically perform CASS (Coding Accuracy Support System) coding. The catch is that these services usually require a paid annual subscription. The underlying database is maintained by USPS and is used to validate mailing lists before presorting—making it a costly option, especially for large datasets.
ZipInfo uses the same USPS database but omits some of the detailed outputs provided by full CASS-certified software. The advantage of ZipInfo is that once it’s installed locally, you can run repeated address checks without incurring additional fees. CASS services, by contrast, charge annually and include monthly database updates—essential for minimizing mailing costs but potentially expensive over time.
With ZipInfo, you still get address correction, standardization, and confirmation that each record corresponds to a valid USPS-recognized address. It formats addresses to meet USPS standards, which is crucial for data hygiene. The matching code I wrote processes about 2.5 million records per hour. Standardizing your data this way helps identify duplicates and, since you’re not bound by USPS mailing requirements (like monthly updates), you can save significantly by updating your database quarterly instead of monthly—without sacrificing accuracy.
1 Like