Hi All,
I am new here so please be gentle with me!
I am hoping that someone can help me figure out how to a somewhat complex transformation that I am trying to resolve.
Here is the scenario:
I have a number of Json files which have been exported from numerous Slack conversations. Each file corresponds to a conversation on a particular day between 2 or more people, hence each filename is along the lines of 2021-11-03.json. In total have about 500 of these files.
Each one of these files has a slightly different number of columns and column names. Some files may only have 37 columns, but others may have over 100. However, I am only interested in getting information from 2 of the columns which are present in all the files. I then need to out put the information into separate files which correspond to the original e.g. Input file name 2021-11-03.json going to output file name 2021-11-03.json_Processed (this will only have the 2 columns that I need)
I have run a batch process on the files to remove columns, which works very well however, the columns are not in the same position in every file which means a lot of the output files end up with the wrong information in them.
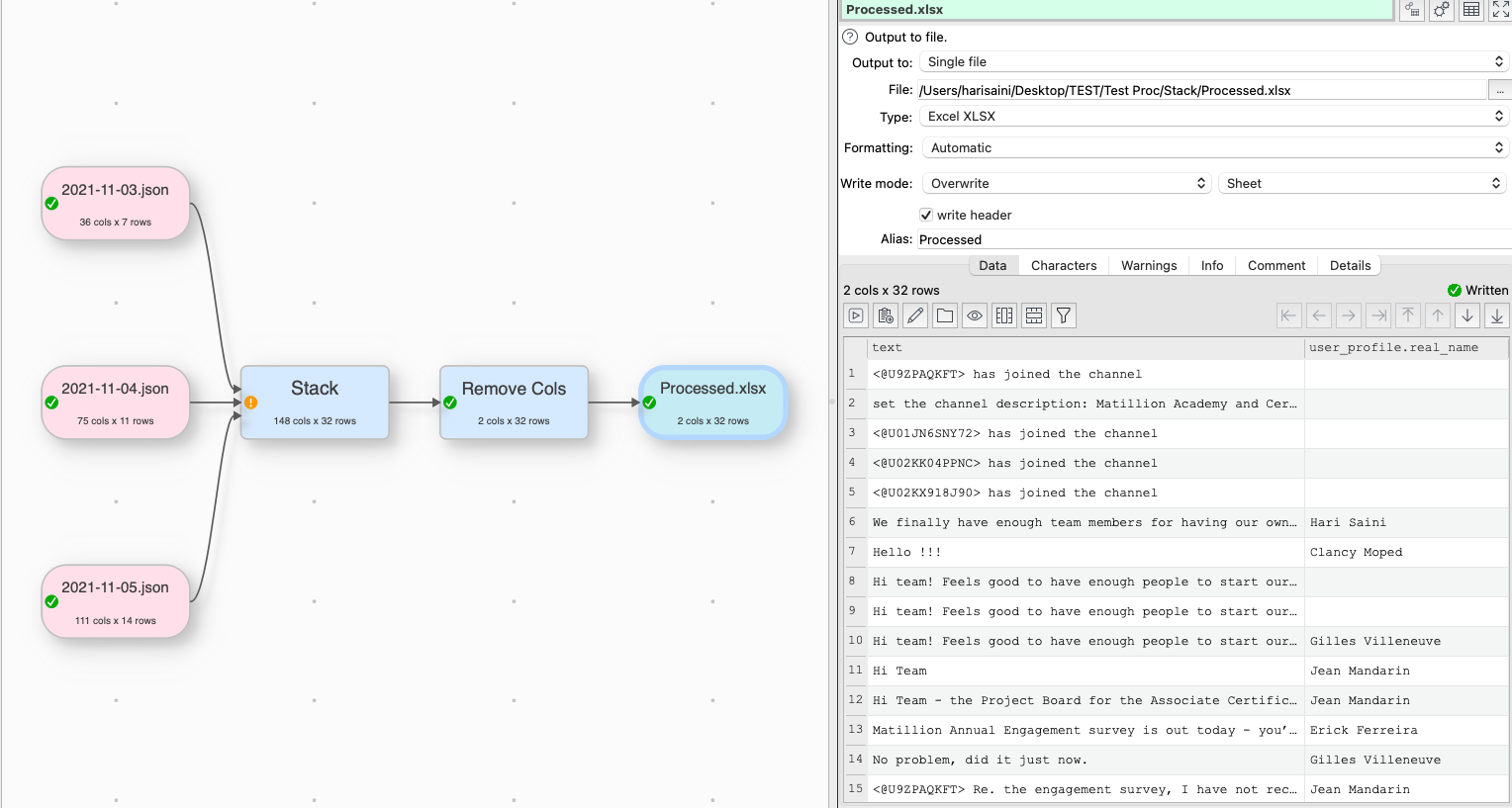
I have tried to use Stack which allows me to align all the columns in all the files, along with remove columns to get down to just the 2 columns I need. I can output this to an Excel file, but all in information is merged into 1 file.
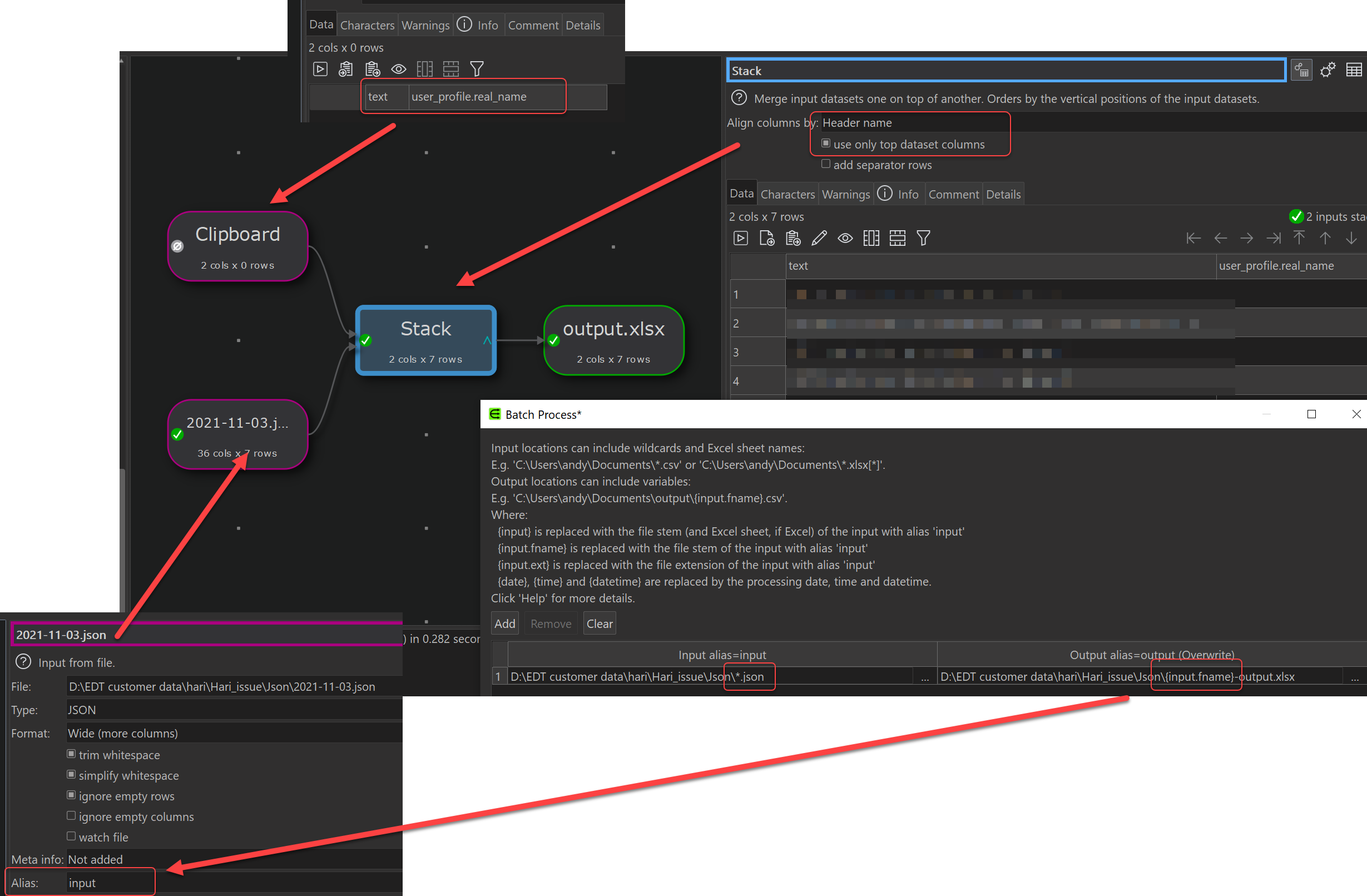
I then tried to run a batch process with the input being …/*.Json and the out being …/{input.fname}_processed.xlsx, but I the end up with the same problem with the initial batch process i.e. some of the files have the wrong columns written to them.
Below are some screen shots of what I have put together.
Is there a way of achieving what I want to do here? Any input would be of great help.