Hello,
I have a csv with 300 columns and 150+ rows.
It contains repeated measures in multiple columns (22 datasets) for an experiment.
The header of the columns is “some text (differs between series, contains spaces)” & “number in digit” & “other text”.
Most of the time there are 15 columns sharing the “some text (differs between series, contains spaces)”, and would already be happy to able to split every 15 columns into subtables, ideally maintaining the first column from the original table.
At some point the columns change to sets of 7 repetitions, with the same form of header.
I can choose the remove columns transform and go through the 22 datasets, but I was wondering if there was a more elegant solution.
By transposing the dataset, using the “Split by size” solution that you propose (file:///Applications/EasyDataTransform.app/Contents/Resources/Help/index.html?ngram.html)
I can separate into individual files the data, but I did not find a way to transpose the rows back to column before outputting the new files.
I assume I can batch transpose all the files…
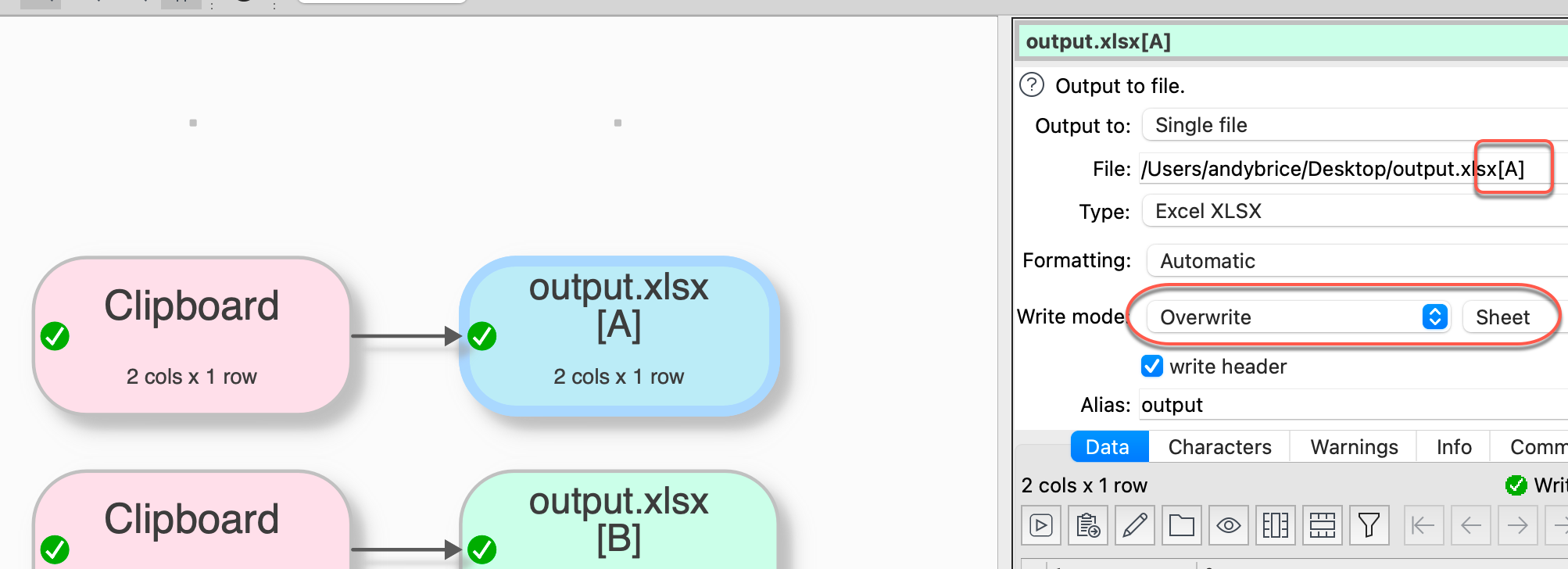
By the way, is there a way to output this to different sheets of an Excel file?
If it were possible to output the data instead as files on the computer as tables within EDT, then it would be easy to transpose. I understand that the EDT transform file would ba a kind of “one trick pony” or “identical dataset structure pony”, since it would rely on the existence of tables created on the fly.
Alternatively a “split columns every X” transformation #feature-request could do that in one go, with the option to output within EDT the new tables for further manipulation (and same limitations indicated above).
Is there another way?
Attached is a subset of the data.
TM output.csv (2.2 KB)
Thank you for your advice!