msmelo
April 16, 2025, 4:35pm
1
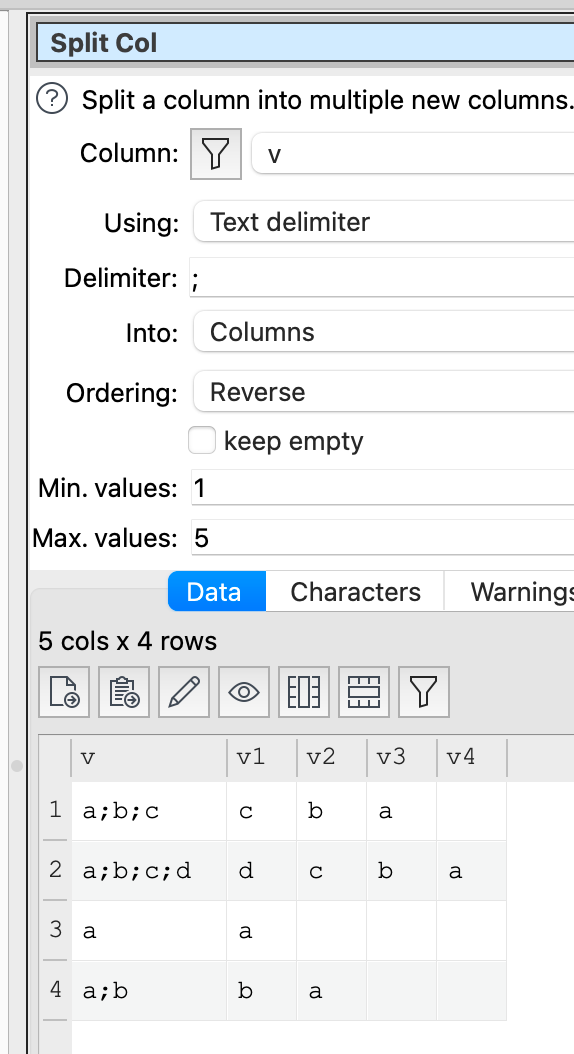
When specifying a Delimiter, EDT splits at the first match (or up to Max. Values). The problem is I do not know how many occurrences of the delimiter there are in the source.
I can set Max. Values to a safely high number, but then I get a tooth-shaped result set, where the last slice from the split is at different columns.
One workaround could be having a way to get this cell, wherever column it ended up). Or maybe have a way to specify left-to-right RegExp?
Admin
April 16, 2025, 9:45pm
2
Do ypu want just the last value in the column? If not, can you give a simple example with the input you have and the corresponding output you want?
Have you tried Split Col into Rows rather than Columns ? Then you can Filter out the rows you don’t want.
Admin
April 16, 2025, 10:00pm
3
I looked at this again. Assuming I understand correctly, just use reverse ordering and take the first column (v1 in the example).
1 Like
msmelo
April 17, 2025, 3:03pm
4
Reverse absolutely accomplishes grabbing the last section, many thanks!
Followup question, I’d then like to create a column with all the sections that are NOT this last one, to accompany that one.
Visually, what I am trying to do is
Input:
Line 1: “[section_1]:[section_2]:[section_3]”
Line 2: “[section_1]:[section_2]:[section_3]:[section_4]”
(SplitCol with “:” Delimiter as suggested)
Output:
Column 1
Column 2
Column 3
Column 4
[section_1]:[section_2]
[section_3]
[section_1]:[section_2]:[section_3]
[section_4]
I could ConcatCols (col index >=3), but they are now in the reverse order.
Admin
April 17, 2025, 8:20pm
5
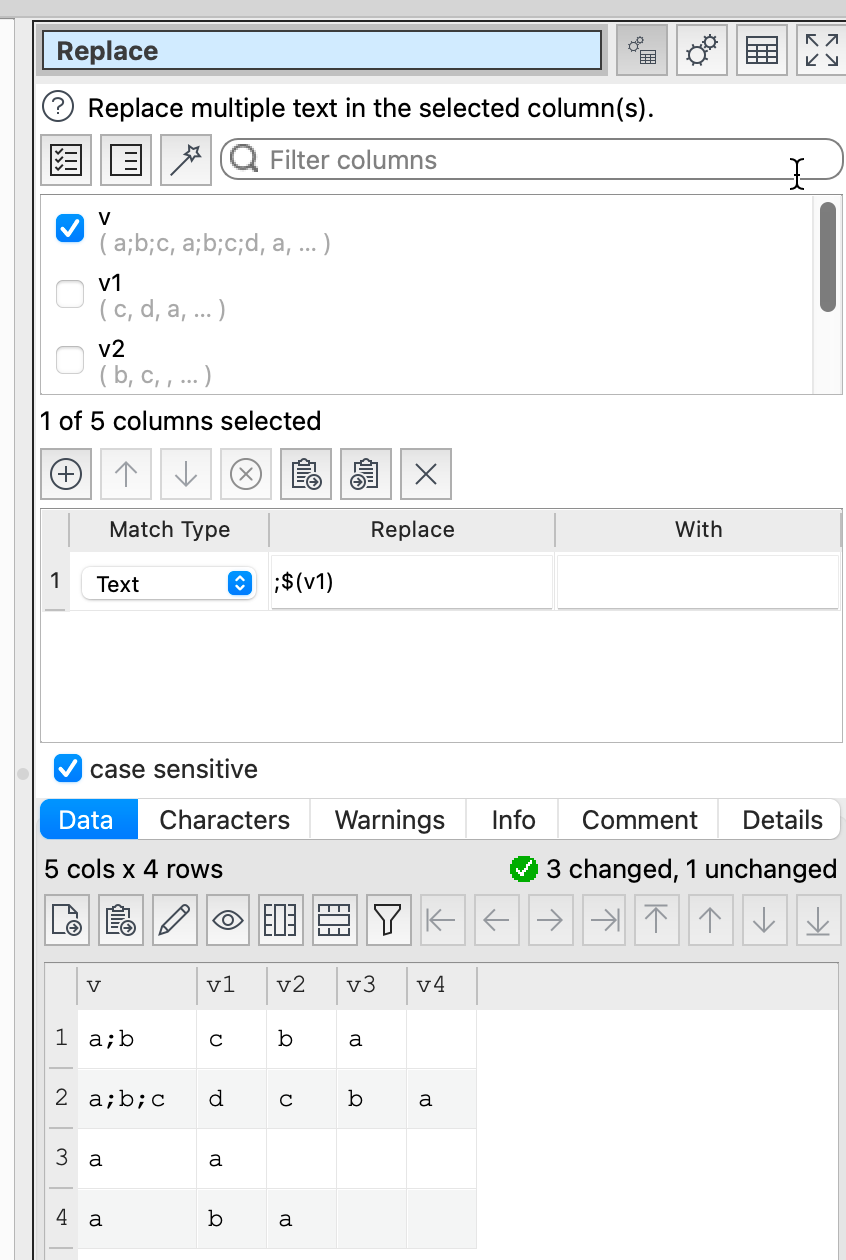
You can use Replace and a column variable.
replace.transform (2.4 KB)
1 Like
msmelo
April 18, 2025, 4:42pm
6
That did it - many thanks!
1 Like
Here is one way to get the last element.
Transform file.SplitColumnAtLast.transform (2.1 KB)
2 Likes
That’s a pretty cool & tight solution. Thanks for sharing!