I am not sure it if is with all other transforms where you have this case sensitive option available or only in Count transform.
If I am choosing case insensitive, it should not change my original data as I am not changing it, I am just asking to count and don’t bother about the case of the text.
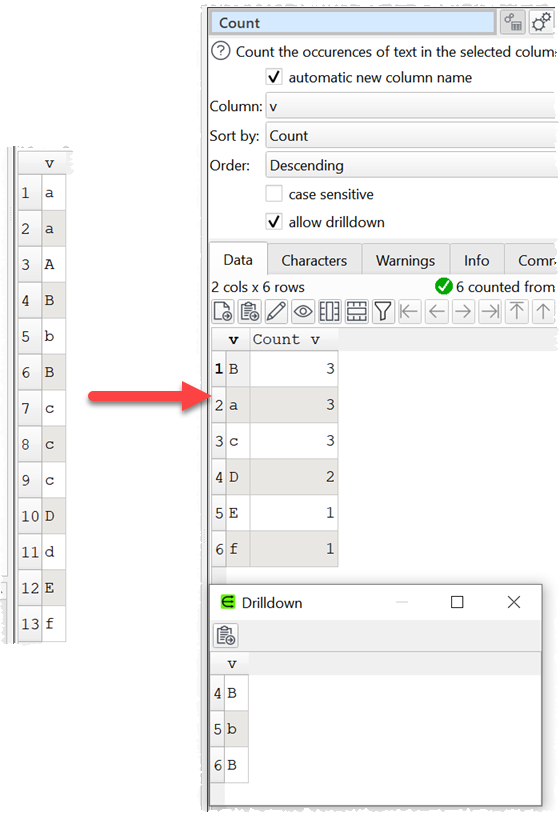
Yes that’s alright which ever case comes first, can be used to represent that set in case insensitive count. This will give clue that data has multiple cases in the data set, which is not easy to detect by eye balling when you have hundreds and thousands of rows.
At least with this case insensitive, I will get my correct count and if see different cases within my result set, will let me know, that data is not in consistent case.
I am not looking for sort, I was just adding on that when case sensitivity is unchecked, then as you said, it should just pick up the first data case whichever it might be and when it gives me the count, I will have single count for no matter whatever the case data might be in.
While not changing the case in the result set (as it is doing now), I was saying that if I see, multiple cases in my result set, will indicate that my data does not have consistent case (which let say I was assuming it will have or let say should have), so by seeing different cases, I can report back to concerned party and let them know about this, so that they can fix at their end.
But as I said, I am not expecting case change in the first place in whatever column I am interested in and if I see different cases, then I should raise a flag and get it corrected.
Let say if I was expecting only Capital or First letter Capital and not all values are in the same case, then that should be flagged and checked why and how this data got in.
Ofcourse, for example, in all capital data, there are few lines which has different case, but if first data that is encountered was all capital, it will not show up and might go unnoticed, so for now on after seeing this, I might do count in both cases, once with case sensitivity turned on and turned off to make sure data is in expected case.
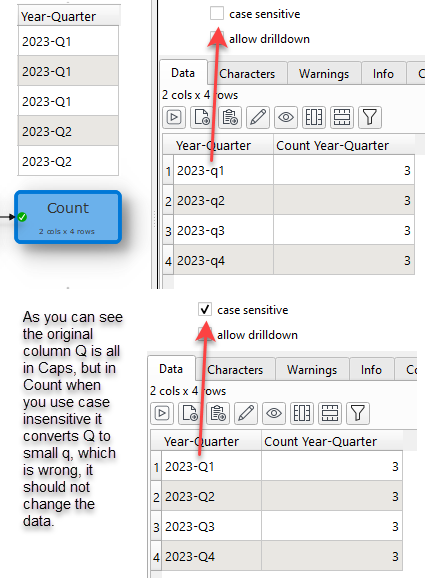
So have you fixed it already? because when I posted, if I set the case sensitivity to off, it turns all the data to small characters in the result set and not likes yours where it is showing Capital letters as well…
Is there something I can do for you to make the indexOf() to be consistent like Java, where it returns the position if string found and if not returns -1 whatever the case might be, first value empty, second value empty or both first and second value empty, I will take zero in place of -1 if you prefer zero.
I am just not able to understand, why you changed your initial position in which you said so yourself, that if string found it will return the position otherwise -1 and that otherwise included all scenario that is opposite to not found.
However it shouldn’t be hard to add to Calculate 2 extra operations:
indexOf - Returns the index position of the first occurrence of the string2 in string1. Returns -1 if string2 is not found.
lastIndexOf - Returns the index position of the last occurrence of the string2 in string1. Returns -1 if string2 is not found.
Which was simple.
And since you are already doing a change, I thought I try one more time and you make this change too (no harm in hoping right).