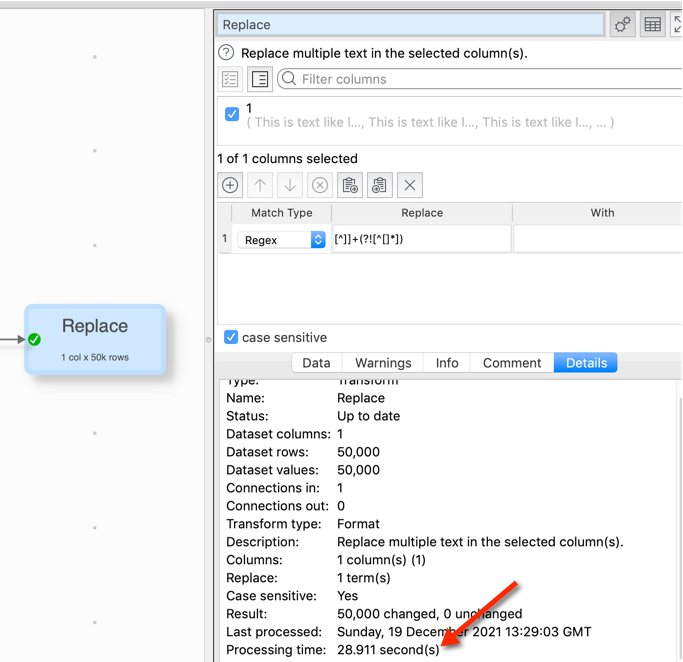
I have a csv file contains 46k rows. In one of the columns I have to extract all characters that are between the characters [ ]. I achieve this by regex [^]]+(?![^[]*])
Data example:
This is text like lorem ipmsum [this text I like to extract] and everything else can be ignored [except this part]. Thank you
The replace-transformation works, however it takes 20 minutes to proceed and during this time I can’t use EDT. RAM allocations already set to 16GB.
Any possibility to speed this up? Any better transformation approach?
@zappatero Obviously regex replace is going to be significantly slower than plain text replace. However 20 minutes for 46k rows sounds very slow. Can you email us your input dataset and .transform so we can investigate? If the data is too sensitive to email us then please just send the first ~10 rows with any sensitive information modified or removed.
Thx for your support!
I’m neither an regex export. But after quite long time, this was the only solution I found.
Yes, the inverse selection \[(.*)\] is very fast, but not what I’m need
Here is a alternative solution using the Javascript transform on column 3 to create a new column. I believe it does exactly what you want. It takes 0.985 second(s) seconds on your 46k dataset on my development PC.
var s = $(3);
var inBrackets = false;
var out = "";
for (var i = 0; i < s.length - 1; i++ )
{
if ( inBrackets && s[i] == ']' )
{
out += ']';
inBrackets = false;
}
else if ( !inBrackets && s[i] == '[' )
{
out += '[';
inBrackets = true;
}
else if ( inBrackets )
{
out += s[i];
}
}
if ( inBrackets )
{
out += ']';
}
return out;
it should work with unlimited [] pairs, as long as they aren’t nested (one inside the other).
No doubt it is also possible to do it in regex much faster. But I’m not expert enough with regex to know how.
I have tackled the regex again and the best solution I found was: [^\]](?![^\[]*\])
Maybe there is still even a better pattern, but this reduced the processing time from ~23min to 19seconds
But nothing works like charme as the javascript transformation which does the job in ~2 seconds!
Thanks for your great support. Hope other can profit from this insights as well.