I find myself needing to randomize for a lot of reports recently. Example: I have 400 shifts worked in the past 30 days. I dedupe to remove duplicates and am left with just the employees name once regardless of how many shifts were worked per person. I then need to randomize/shuffle the rows so that I can then slice and have 20 random names out of say, 115 names.
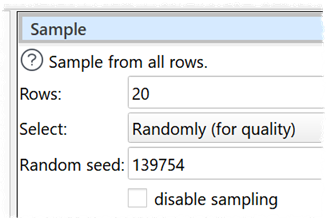
•The default Seed value is based on the system clock when the transform was first created.
This is good, but it would also be useful to have one of the following:
A button within Random to generate a new seed, or
A tick-box which when enabled generates new seeds for that Random transform*. The circumstances in which that generation occurs could be
whenever the transform is Run (including Auto-run), or alternatively
the first run only after the transform is opened, whether or not Auto.
I mean to suggest one of those sub-options, not have both, and prefer the latter one. Benefit is simply saving me randomly generating and entering my own seeds, while retaining existing behaviour as the default.
*edited to change “all Random transforms” to the more sensible and consistent “that Random transform”.
If the data is both similar in content and ordered then the same seed produces substantially the same result. Normal operation is often what is desired but too often for me I want sub-set selection to be more variable. The Sample transform with random selection works in the same fashion as Random.