Sometimes I do filter data under different criteria and write it later on into different files by criteria. in production processing it might come up that there is no data for one criteria. Currently a file with just the headers is written, which is generally good, as it shows there is no error.
Nevertheless I would like to have switch to disable writing a file if no rows are available to be written.
Actual - specially when it runs in batch mode - I have to go through all files written and check if some of them are empty. Maybe logging can show too, that N files are not created as there was no data.
If we added a ‘don’t write file if 0 rows’ option to output:
-
You might still have the output file left over from a previous run (where there were >0 rows). Which could be rather confusing.
-
It would complicate the output UI a bit more. And it is already quite busy.
We could add something like the number of rows written during batch processing. Currently this is shown in the main window log:
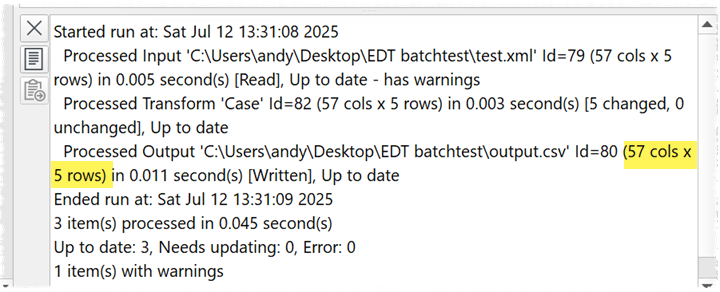
But not in batch processing:
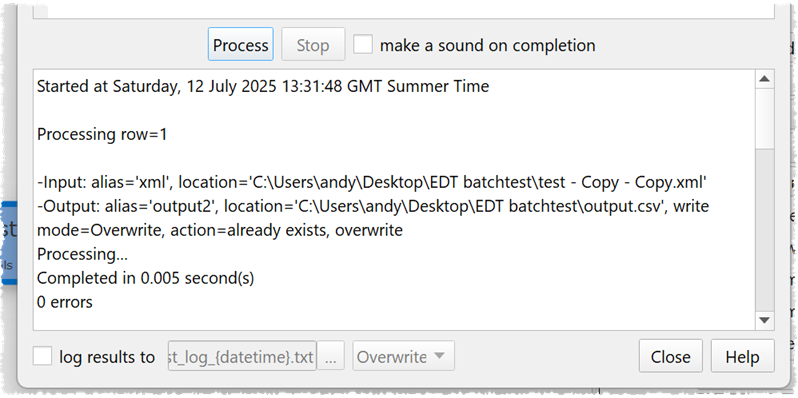
I don’t get this point … why should this happen?
Meanwhile I build something based on MetaInfo and multiple file output, but it adds 8 additional transactions for two selection criteria. Each further criteria will add two transactions. It works for me, but it is hard, as we share the transformation in a team of three persons, necessary path adaptations between the computers (Windows and Mac) is harder than only the adaptation in the batch menu. But I think what I have might be a rare use case. It works now as intended.
I can understand that you don’t want to add to much complexity to the output transactions.
Lets say you output A.csv and B.csv from your .transform.
You run things on Monday and both A.csv and B.csv have > 0 rows and are output.
Then you change the inputs and run again on Tuesday. A.csv has >0 rows is output. If B.csv isn’t output because it has 0 rows, then you still have B.csv, but it is from Monday’s run. Which could be very confusing.
Or perhaps I misunderstand what you want to do?
o.k. I think I get it, you think it the output from day still exists. I’m used to such effects, so in case I expect files with same names as in the run before I start them in a script e.g. KeyboardMaestro and delete the “old” files before.
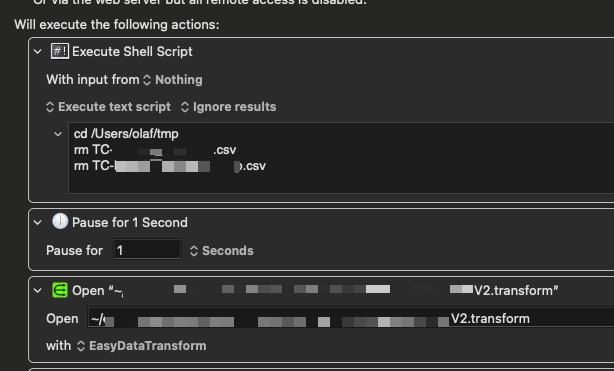
The files removed in the figure are output of the following EDT transformation.
But there is a risk and you are right, didn’t recognized it in the first thought. Speciall as I get fro my problem I intended to cover different filenames all the time which are processed with “*”.
1 Like
I’m just anticipating the support emails from confused people. ;0)
2 Likes
+++++1
If it’s a non default switch , I think chances of people using it goes down drastically.