Sorry if this has been covered in answers to other questions, but I saved a series of transforms on one file that I wanted to reuse on a different input file having the exact same format, but different data.
Unfortunately, when I disconnect the original input file and try to connect the new one to the transforms, all the transforms that require column selections now have them unchecked. I have to re-check each one. Is there a way for it to remember which columns were selected for each transform, or to save column selections?
@Titus
If you disconnect the input it will reset all the column related parameters downstream, for consistency. So we don’t recommend that. Instead just change the file that the input is pointing to. E.g. by clicking on the ‘…’ browse button in the Right pane with the input item selected.
I see. It is a one time mistake anyway. (Or hopefully so.)
But it is somehow an understandable reflex due to the design. When you see the transformations, there comes immediately the idea to ones mind to just quickly copy the branch and stick it to another input.
So I need to think about a naming strategy for the inputs then. Maybe a folder that renames the inputs accordingly. Is there a best practice or do people regularly do this go via the batch function? (have not come to the moment to use that one, i.e. learn about it.)
I completely understand. But we have to maintain internal consistency, which regretably can lead to nuking of column related parameters downstream. But we may find a cleverer way to deal with this issue in future.
Note that you can click the ‘…’ browse button next to the location of a file and choose a different file. if this file has the same (or more) columns then no column information will be lost.
The batch feature is useful when you want to apply the same .transform to lots of files.
I have a slightly different scenario. I’d like to take a fairly large number of files (different data but same columns) and reuse the transforms by attaching them to the initial stack. I understand that I have to leave one dataset there from the previous or opened transform so that it doesn’t reset down the line. How can I easily attach files (let’s say 20 of them) to the original stack without going one by one and clicking the plus button and attaching each one to the stack? When I bring in that many files, the entire tree gets very small. Is there a way to select all the new files and connect them to the stack? Thanks…
Have you checked the batch functionality, which is great for identically structured files (it support * in the file names, too). In case you can not use it in the existing flow. Create a batch job merging all files into one and use the result for the exiting flow.
As Olaf says, you could use the batch feature to perform the transforms on each input file. If you want you can append the batch results to a single file. See example 2 here:
Well, that’s the problem; I assume the new file will be the same format. I have redundant steps and make transformations to encompass possible changes.
Matching 20 column headers to run a transformation takes as much time as manually formatting the spreadsheet. Even so, the differences are so small that they’re not caught, like a white space or an abbreviation.
If the columns are in different orders with different names, I’m not how we can fully automate that.
Perhaps you could supply a real world example of the differences between 2 inputs. Only the first few rows are needed and you can change any sensitive data.
If problem is having column name different or in wrong order or both different and in wrong order, but the data is the same in the column to process, then hope the following steps help you out.
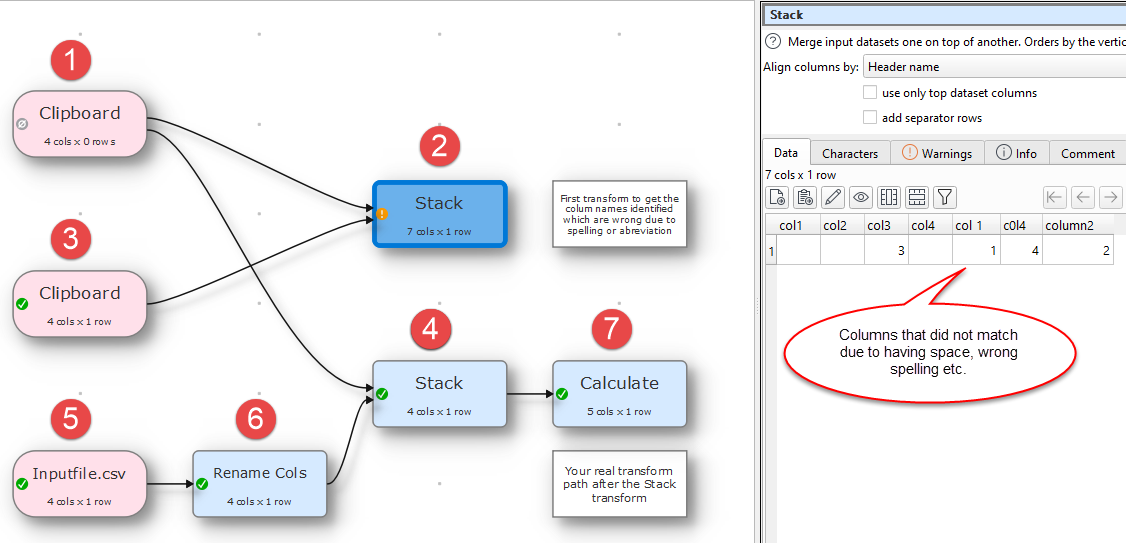
Step 1:
Create your column name the way it suppose to be and copy paste them as input from Clipboard
col1,col2,col3,col4
Step 2:
Add Stack transform and set align columns by: Header name
Step 3:
Now take only the column header from your input file and add only one row, with the column numbers the column heading is representing
inputfile
col 1,c0l4,Col3,column2
1,4,3,2
copy and paste them as input from Clipboard and attach it to the Stack, and you will see which column matched and which did not by having the row value under the columns and on right side you will see all columns that did not match. This will solve your issue of locating the differences in column names due to white space, spelling, abreviation and such.
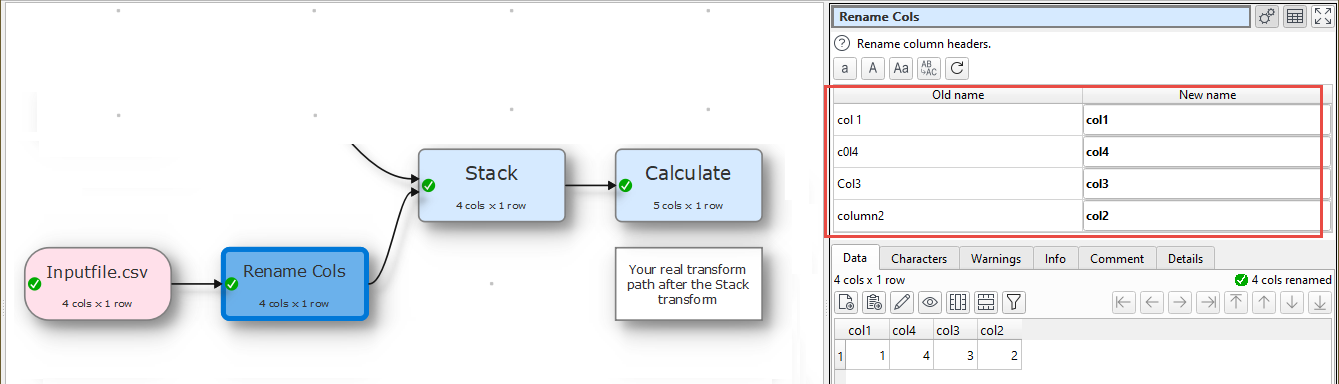
Step 4:
Add another Stack transform and have it’s first input from the Step 1 right column name input from Clipboard
Step 5:
Add your input file
Step 6:
Add Rename Column transform and rename the columns that did not match