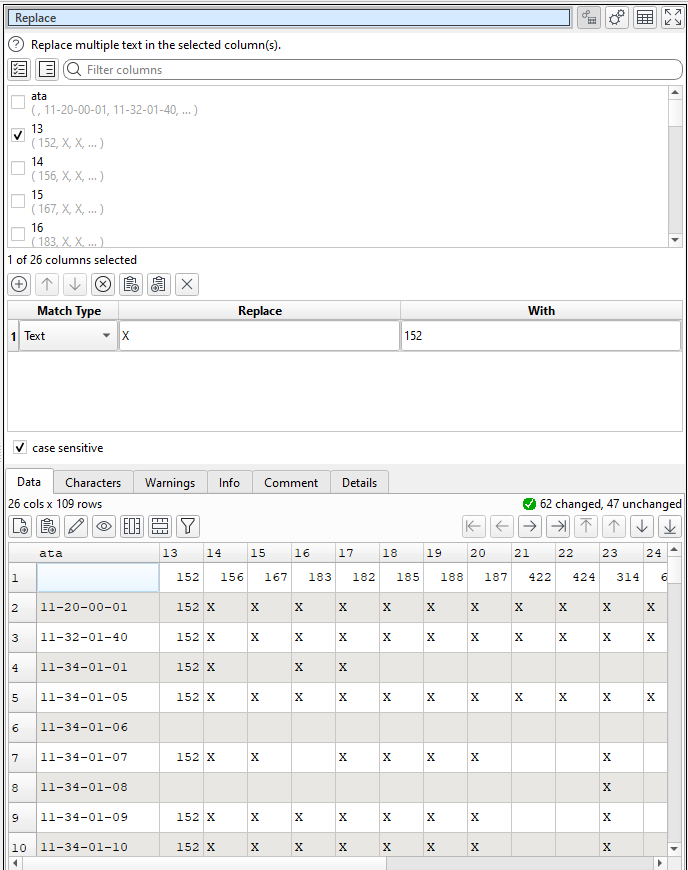
Happy New Year everyone. My first row has a series of numbers. I want to use these numbers to replace values in each column. Hopefully the screenshot will illustrate what I am doing. I want to replace the X in each column with the number in the first row. I did column 13 with a Replace. Do I need to do a Replace for each column or is there a more efficient way to do this?
One enhancement request might be the ability to specify a column for each row of the Replace. That way you could do what I want with a single Replace function. Thank you!
Thank you Andy. Adding multiple Replace functions was not much of a problem. And I agree about the complication of my enhancement request. Thanks for the quick response!
One thing I was messing with: it looks like you use XML for the transform files. Editing the XML file might be a good way to add a bunch of Replace (or other) operations. One thing I notice when I open a .transform file in an XML editor: there are a bunch of Unicode 0x1f characters, which are not legal in XML.
However, I was able to add a Replace in the XML file and connect it between two other ones. When I reopened the transform in EDT, it worked fine. It would be great if you could substitute the 0x1f character for a valid XML character. I am not sure what the purpose of the 0x1f character is. I am googling around to find out.
Yes the .transform file is XML. You can modify it by hand (or using Easy Data Transform!). But make sure you keep a copy of the original, in case you mess it up.
The 0x1F character is the ASCII ‘unit separator’ character (US). As it is almost never used in data it is a very convenient way to separate multiple values stored in a single value (the purpose it was intended for).
However we later realized it isn’t a legal XML character. Oops. We will be looking into getting rid of it for v2, while still maintaining backward compatibility.
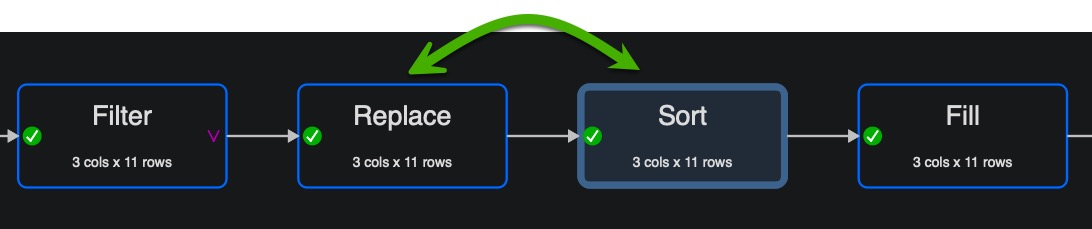
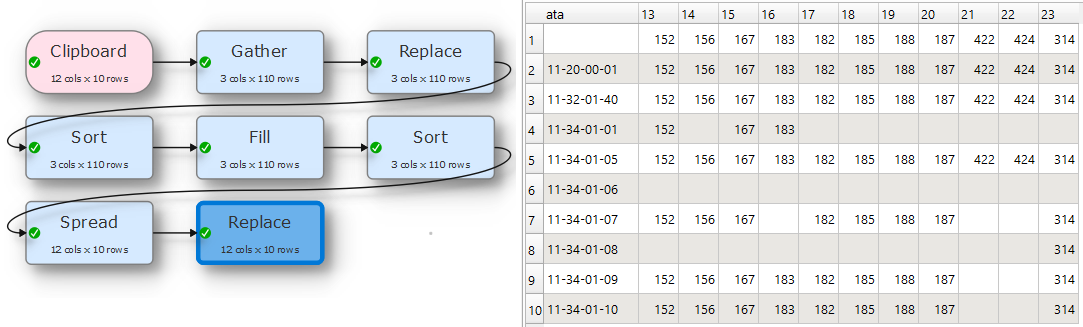
I had a look to the proposed solution. It didn’t work 100% correctly. From my perspective the sort and the replace should be changed in the sequence and the sort needs a second condition to get the value to be filled on the top of the list
@Olaf Thank you for reworking it. @Anonymous I ran my entire data set through yours and it worked perfectly. I have to step through it so I can really understand how it works. Thank you Andy as well. EDT is amazing!