I am working with a 1.3 million rows dataset with birthweights from which I need to remove about 1.2 k of matching birthweight rows of subjects with a specific condition in another dataset, in order to do statistical analyses.
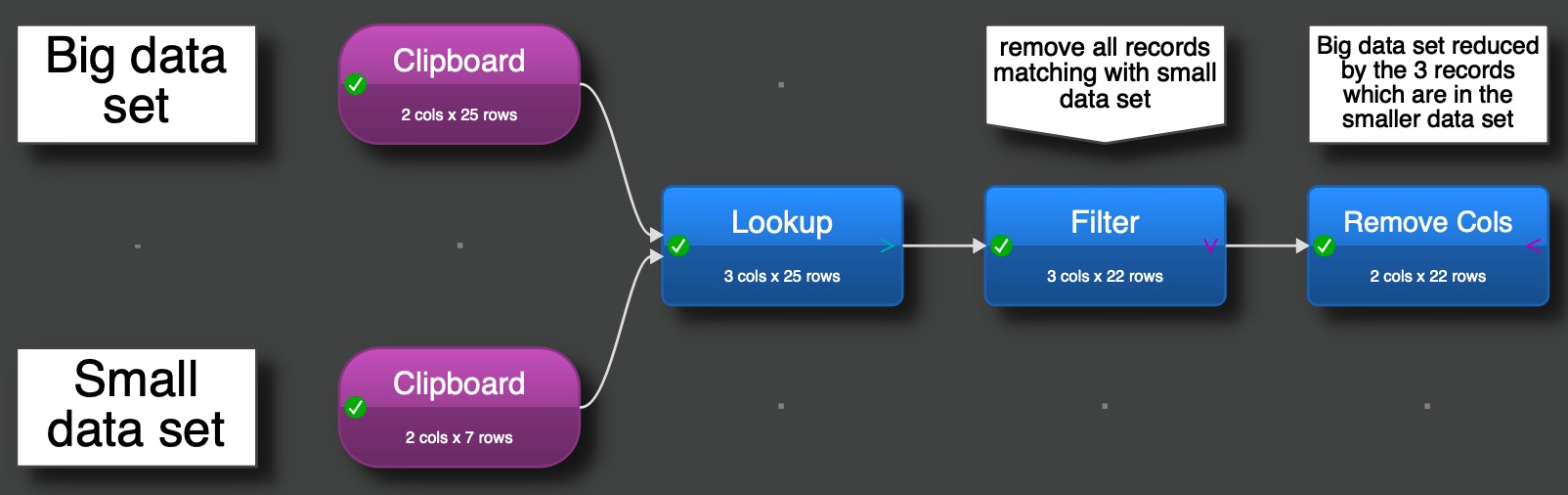
Do from the big dataset a lookup to the smaller one, you can use what ever filled field in that data set (or you create with NewCol a new field with text like „remove“).
The looked up value should now mark the records to be removed. With this you can use filter to keep only rows where the lookup value is empty. Afterwards you can remove the column with the lookup value.
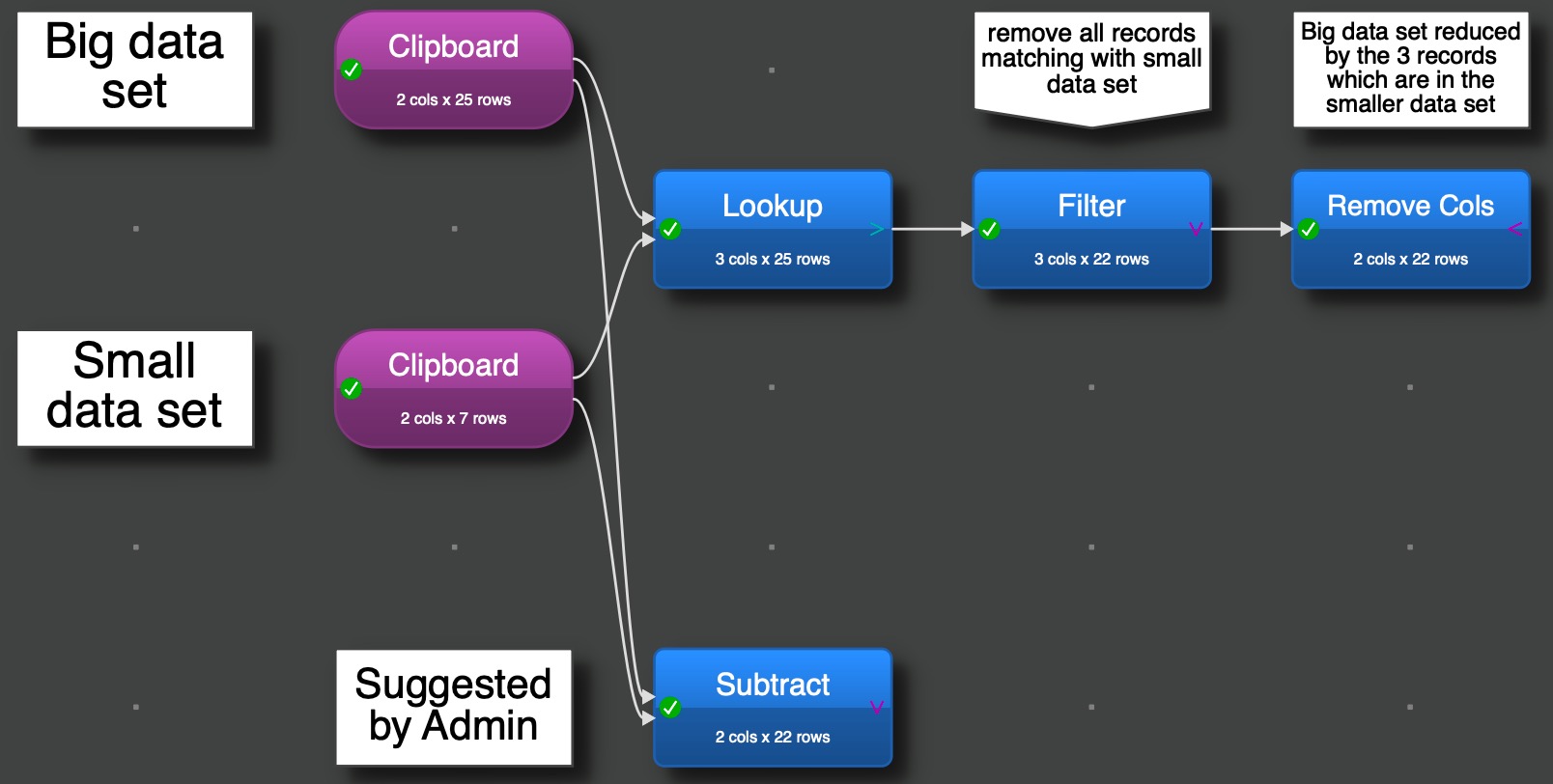
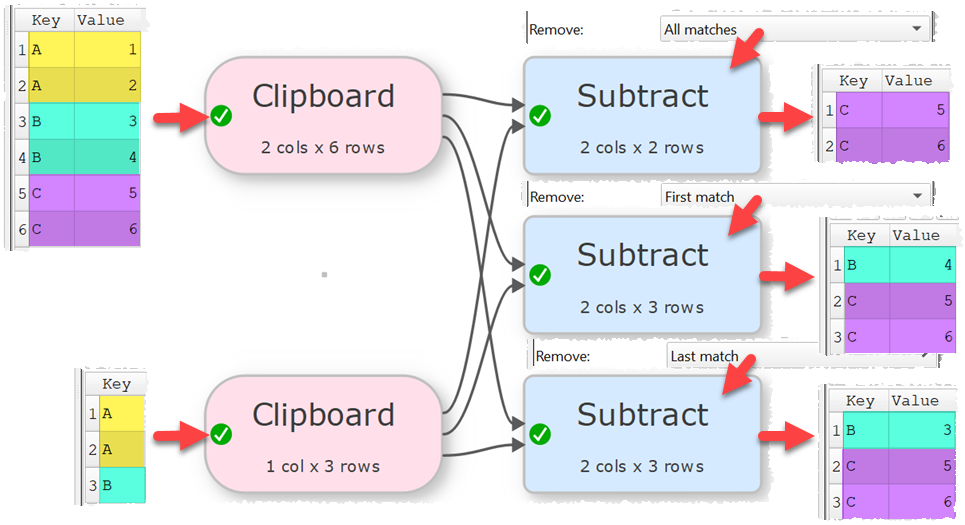
And you want to remove all rows with jaundice or premature in the Condition column. Then just use the Subtract transform with a second data with all the values you want to remove:
And now with the subtract, which is even more simple, but a form of brute force. If it is based on additional criteria in the second set, the lookup might be the best choice as you can lookup for the criteria value.
The smaller data set has no an additional column with a criteria and the lookup select this criteria. The filter is now changed to a remove one, remove all records with the criteria match.
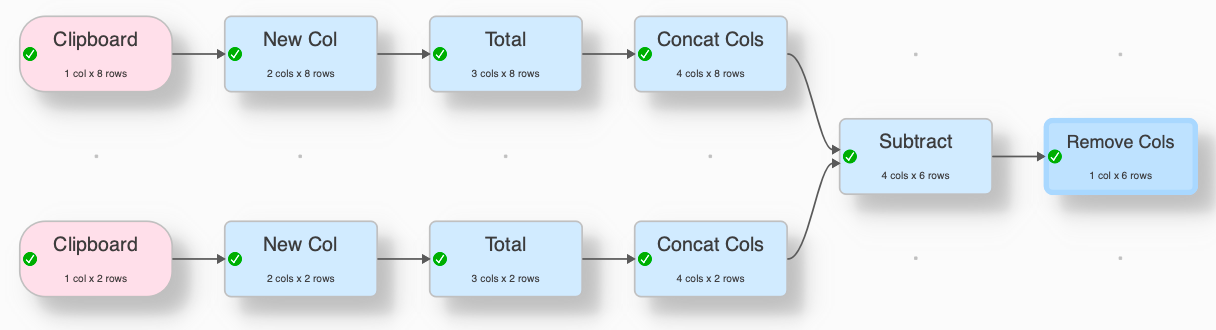
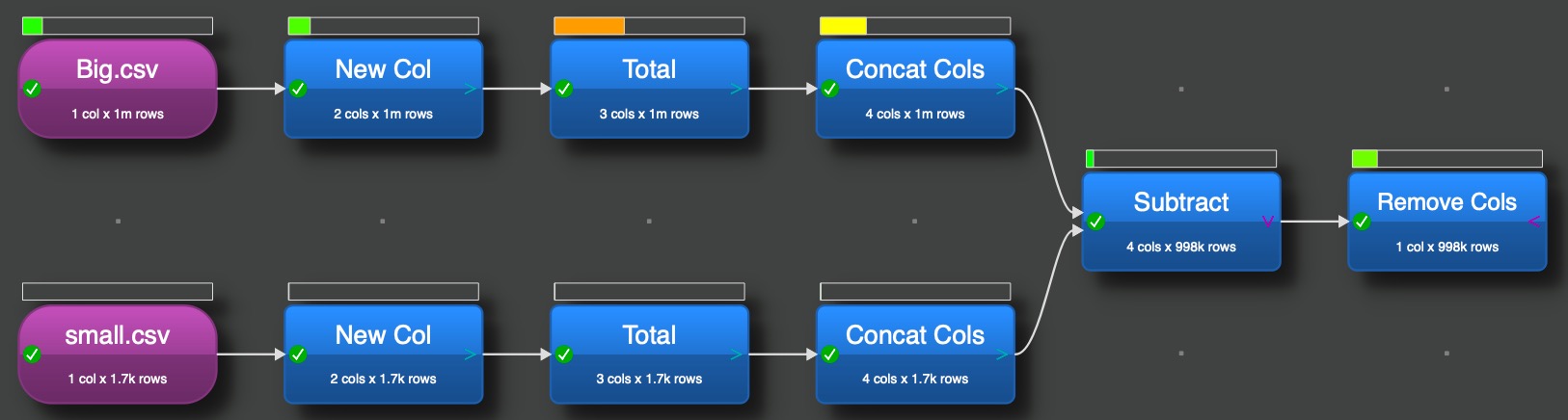
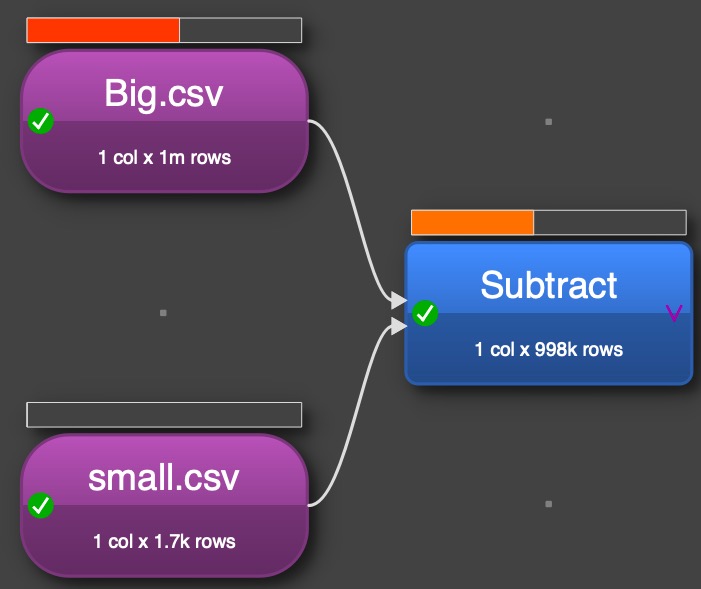
I was curious about the execution time differences between the two different solution, I thought lookup and filter might be expensive (even when the solution has less transformations). I build a big data set of 1 million records, each value was there 40 times, the sequence of the values was random (added after generation an second column with random function and sorted them by the random value). Second I generated a small data set by unique about 1.800 values out of the big set. Both were written in csv files.
Then I used both solution with the csv file input. EDT is unbelievable fast handling this 1 mio records. I repeated the execution multiple time. In average execution time for the subtract solution is about 2.0 sec and for the lookup 2.1 sec, so 5% difference (on a Mac with with M2 processor). For sure the user doesn’t recognize the difference.
Thank you Admin and Olaf!
The latest transform from Admin works perfectly - and honestly I am not looking at shaving fractions of seconds for transforms that anyhow are very fast, but I see Olaf’s point for larger datasets.
As for the wish list for the Remove transform (remove from X content in Y) :
Given X:
A 1
B 1
C 2
D 4
E 2
F 3
G 2
H 1
and Y:
A 2
B 1
C 2
D 5
My preferred options would be:
Remove all matching (would leave in X rows D & F)
Remove single match(es) (starting from the top would leave in X rows B, D, F, G, H)
Remove first match(es) (would leave in X rows B, D, F, G, H)
Remove last match(es) (would leave in X rows A, B, C, D, F)
I think important to remove single matches as you may need have datasets coming from different sources, and for analysis matching rows may need to be removed from the larger dataset.
And in the Remove transform Warning pane it may help to indicate unmatched rows in Y (D 5)
I am not clear on the different between Remove single match(es) and Remove first match(es). Perhaps you could include an example where they give different results.
Also it might not be worth adding extra options that are equivalent to adding a single Sort or Dedupe transform before.