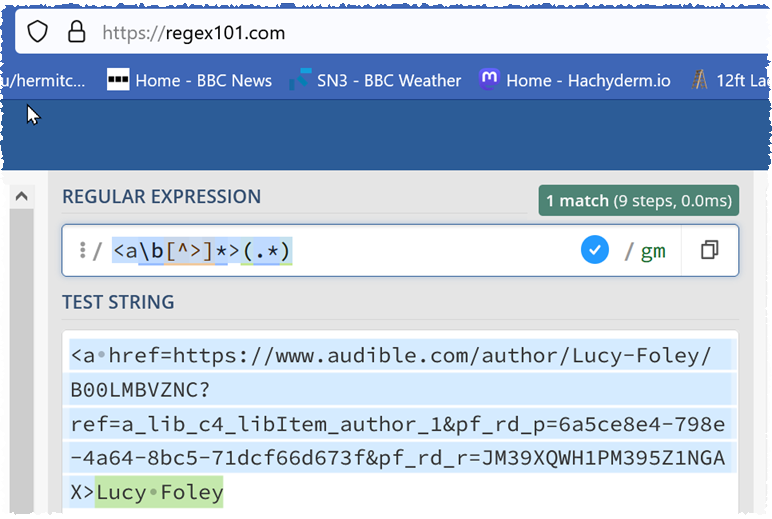
Both only captures a single character. I don’t see how it work in any regex implementation. Perhaps the regex got mangled by this forum (try using ‘preformatted text’)? Presumably you want:
Looks like the difference was in the capture, mine was a “lazy” and yours was “greedy”. Looks like your implementation doesn’t support lazy. I’m trying to find the right setting to RegexBuddy that matches your implementation.