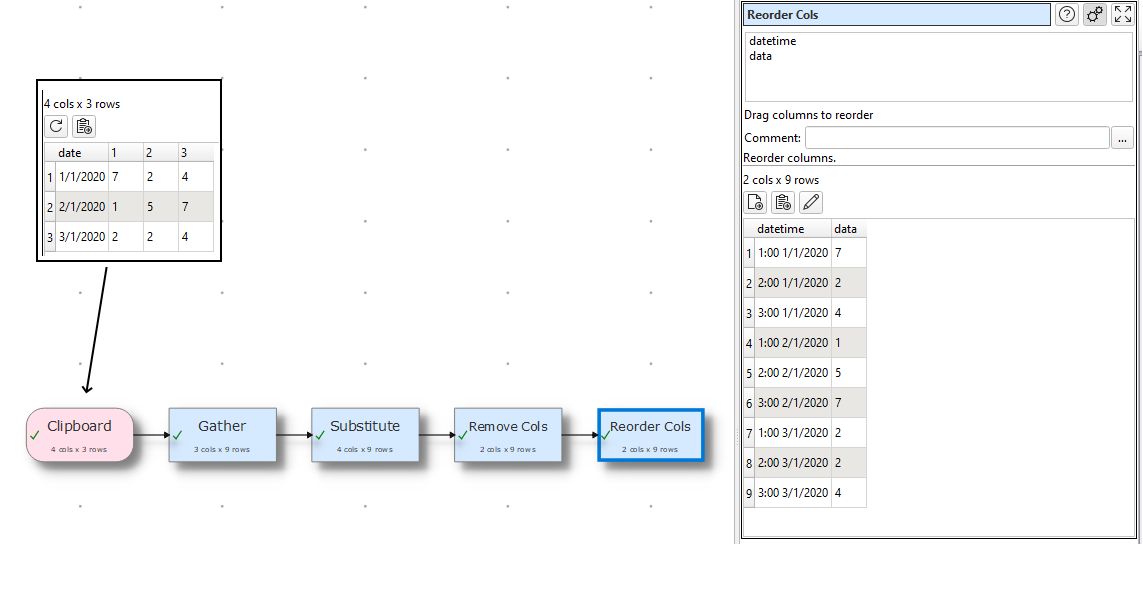
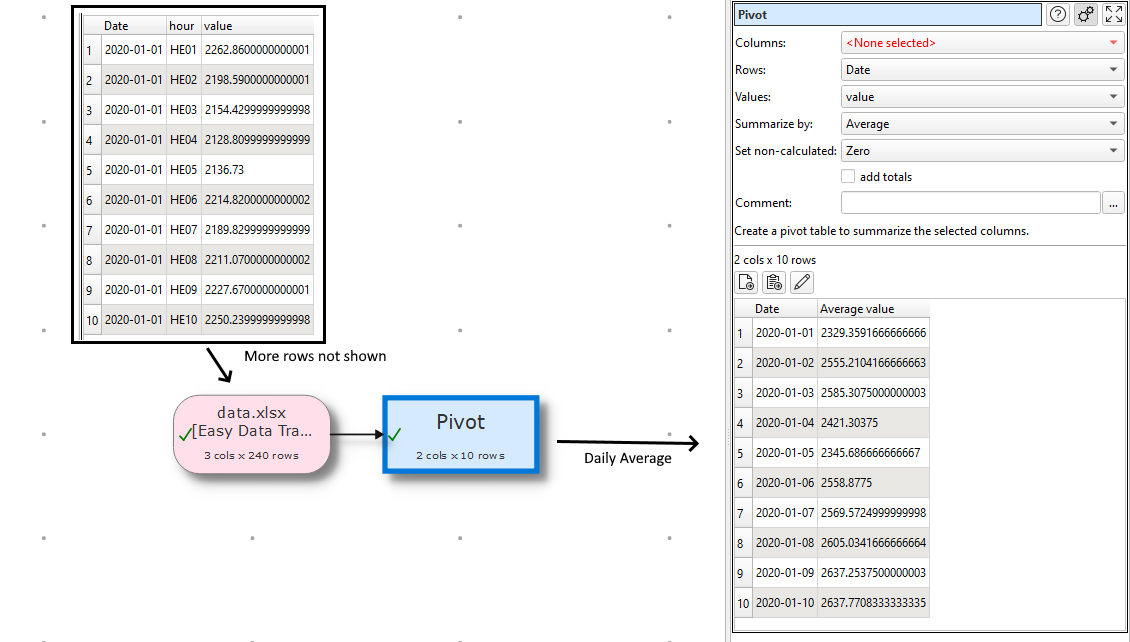
Some dataloggers provide hourly averaged data presented in columns, with each row representing a day and each hour being represented as a value in a column (24 columns for hourly representation). Processing this data using analysis tools or importing into time-sequenced DBs is tricky in this format. It is MUCH easier to have each individual datapoint timestamped.

A great way to do this is with a routine based on the EDT unpivot function with some extra steps. A nice example of that is shown here: