I have a .txt file with paths (NTFS on Windows). They are all at least 250 characters long, most of them have over 260 characters.
I want to shorten them so the all fit into a 259 char limit.
Lines (about 16.000) look like e.g.:
\\home.local\shares\01 Leadership\01 Geschäftsleitung\03 AF-Projekte\GA001 Organisationsüberprüfung 2025\10 Arbeitsdokumente\4 Organisationshandbuch\02 Stellenbeschreibungen\2012 Arbeitsdokumente Leiter Bereich Immobilien Landwirtschafts- und Forstliegenschaften.docx
I can import this file with the custom delimiter “\” and get ~24 columns out of it.
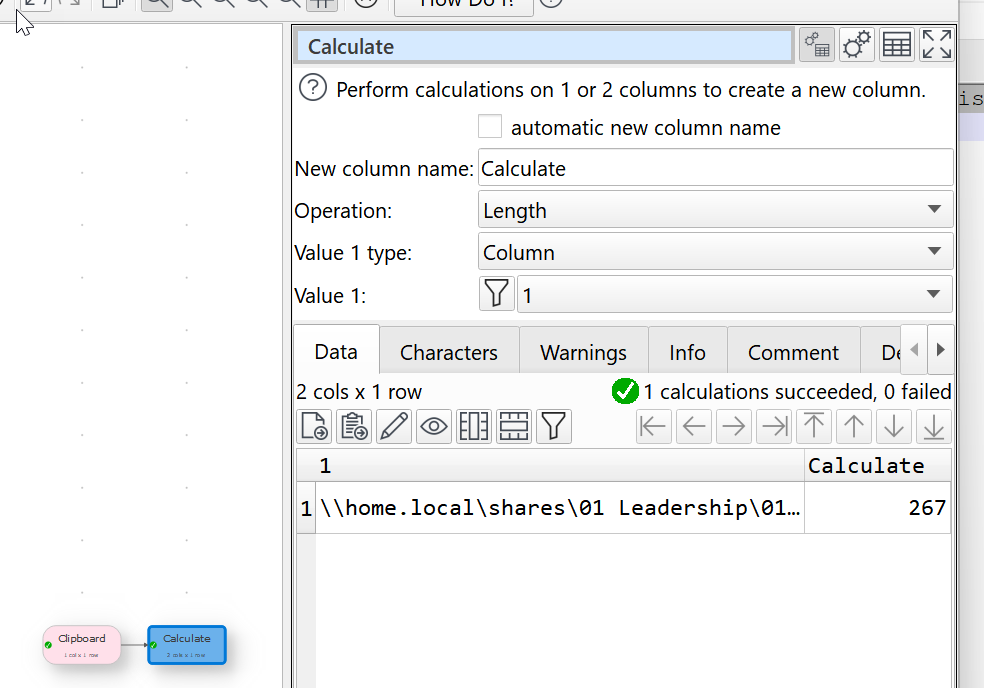
My question is: Can EDT be used to set up rules that would help to shorten paths and add a column that counts the number of characters over each row ?
Rule 1: The last column which contains data in each row should be checked if its content contains a word that was used in a higher hierarchy level and if found the word is removed in the last column with data.
E.g. the filename here contains “Arbeitsdokumente” and 3 levels higher the cell contains this word as well which should lead to a changed cell entry of this name:
2012 Leiter Bereich Immobilien Landwirtschafts- und Forstliegenschaften.docx
If this rule doesn’t lead to a row with a maximum number of chars <= 259, the filename should be truncated by removing a middle part like:
2012 Leiter Berei ... liegenschaften.docx
Just as an example…
Is such “advanced” stuff possible with EDT and if yes, can someone give me a hint how something like this can be set up?
You could then use that with Filter to remove rows <= 259 chars. Or use Verify to trigger a warning or error.
Implemented your shortening rules is a lot more challenging. I’m not sure if any of the existing transforms will help you. You might have to use the Javascript transform and write some Javascript.
$(i) is substituted once at the start with a simple string substitution (with the value of the column named ‘i’). So it isn’t going to do what you want.
There are other simpler ways you can count the total non delimiters characters though. Read it in as plain text. Replace the \ characters with nothing using Replace and then use Calculate to calculate the length.
My understanding was that @highend needs to remove parts of strings based on other parts of strings, which is something the native transforms don’t really handle. Hence the suggestion of Javascript. It might be useful to see a simple an example with several rows of input and the corresponding output desired.
01.
Current filename: Beilage 2_Vernehmlassung Parkierungskonzept.docx
First level above: 2041 - Vernehmlassungen Masterplan Veloinfrastruktur_Parkierungskonzept
Expected output: Beilage 2.docx
This could only be done if a regex is built with singular / plural options, in this case for the german language.
Because "Vernehmlassung" != "Vernehmlassungen"
02.
Current filename: mdl. Nr. 90 Kaufangebot Korbgasse 99-102 Turi.pdf
First level above: 90 Kaufangebot
Second level above: Grundlagen für Vortrag
Third level above: 2161 Turi, Kauf Korbgasse 99-102
Expected output: mdl. Nr..pdf
"90 Kaufangebot" is present in the first level above, "Korbgasse 99-102" and "Turi" in the third level above
The final file name isn't pretty, I know, but I'm posting "easy" things here and we'll have to die a few deaths to trim down the total length on more complicated paths
03.
Current filename: 3515_Kostenbeteiligung und Erlass Umsatzmiete Vierzetteli.docx
First level above: 3515 Kostenbeteiligung und Erlass Umsatzmiete
Expected output: Doc.docx
Everything from the file name is present in the first level above. Partially with different separators ("_" instead of only spaces).
This would lead to a completely empty file name!
The common sense for such cases is to set it to e.g. just "Doc" (for "Document")
This is text processing with complex rules and requiring quite a lot of domain knowledge. Which is not what Easy Data Transform is really designed for. You can probably do a lot of what you want in a Javascript transform, but it isn’t something we can really help with. Sorry.