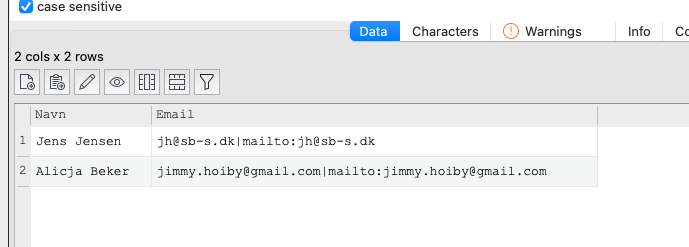
Is there an option to read an Excel-file without the links information?
I would like to disregard all information after the | character.
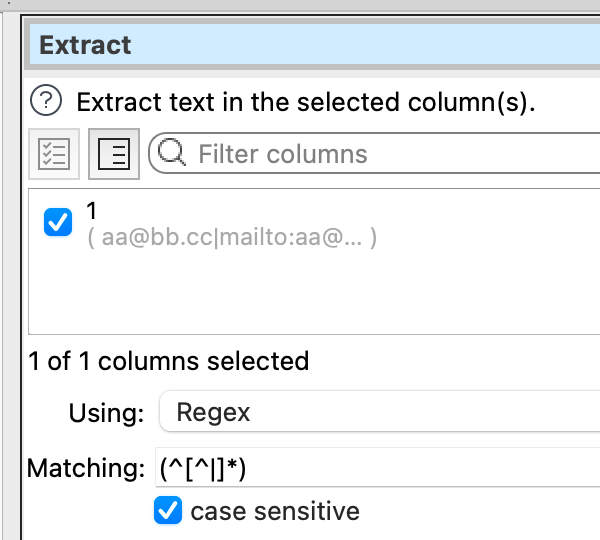
I know I can search and replace. But I am make a very simpel transformation to convert to csv. And I do not know how many columns or what they are called. So it would be better if I somehow could toggle this on the input element.
And as for not knowing the number of columns or what they are called, this is simple to over come by first selecting all the columns in the Replace transform and then uncheck columns that you don’t want to be part of replace.
Since I need to automate it with CLI, my solution has been to create a dummy file with 30 columns (I think this is the maximum input) and then run the replace on all columns.
It seems to work fine as long as there are 30 columns or less.
If it is possible, make changes in the If and similar transforms where column position change, replaces the column in the condition with the new column that happens to be in that position.
If in the condition, column name is mentioned then the transform should stick to it, no matter where that column appears in the position and if it does not appear then should stay gray indicating change is required.
As of now, if the position of the column change then If transforms silently take value of this new column and it won’t even notify user of this change.
For example if I have file with the following data
Col1,Col2
1,2
and I have If transform condition like this
if Col2 = 2
then= Two
ELSE=Changed to Col1
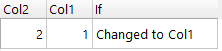
Now if in the file the column position is changed
Col2,Col1
2,1
then If transforms become like this
If Col1 = 2
Then= Two
ELSE= Changed to Col1
The If transform will change the column in the drop-down if the re-ordering is caused by a Reorder Cols transform upstream. It won’t change it if it is caused by a change in column order of the input file. You need a Stack transform to handle that. In v2 we are hoping to have better ways of handling ‘schema’ drift for inputs. Until then you need to use Stack.
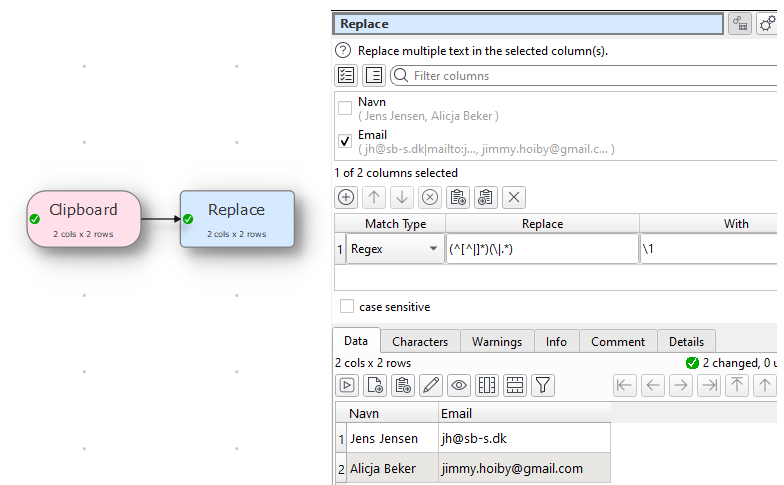
It does change, I am attaching a transform and test file which currently have data as
Col1,Col2
1,2
Run the transform and you will get as mentioned before result as Two
Now keep the transform open and behind the scene change the file and reorder the columns as
Col2,Col1
2,1
And now when you re run the transform by reloading the file you will end up with result Changed to Col1. And you are not even informed that the condition of the If transform is changed.
I meant that it won’t re-order the If for you if the input column order changes (it wasn’t very clear). So you would have to use a Stack transform to keep the correct column order:
But it did re-order the column in the condition from Col2 to Col1 values which is wrong.
For my understanding, why does the column shift happens in the condition, since the condition is based on column name and not the column position, I understand if one uses column position ($(2)) then it makes sense, but if one uses column name ($Col2) then it should take the data from the column name where it might end up in position of columns.
That is fine, you know better with this regard, but what I am suggesting and again you know better if it is doable or not, is that when you are loading up the file and the transforms in which column names are used, why not adjust the internal index accordingly in the start with their position where it might be as long as the name is the same and if multiple column with the same name, then again first come first serve index them as they appear in the file, but for the unique ones, they should be adjusted and since you already have the name and the position saved in the transform file, you can adjust their new position and continue using column position (index) as you are currently using.