is there a way to bind a specific column to a function regardless of the number of columns added in a changing dataset?
I want to rename “column 1” but in the updated dataset it always shifts to the column “set 3”. I assume it sets the column position as absolute (Table column 3).
internal EDT doesn’t handle column names, it uses just column numbers.
In case you have changing or changing order of columns in input files, create a help file (csv or Excel) which just includes the headers. The first thing you should do before any other action merge the file with the headers (on top of the data file) with the data file using the Stack transaction (align on “Header name”). This will bring the columns every time in an identical order and the following actions should work correctly.
If the column that you want to change in the changing dataset will have the same column name regardless of the position, then you can follow these steps.
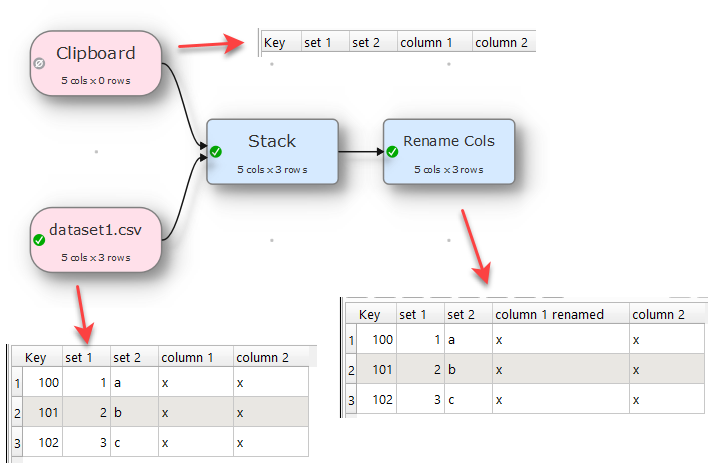
Create your column headers the way you like to have as example,
Key,set 1,set 2,column 1,column2,column3
Now have that paste from clipboard or create a csv file, which ever you prefer and use Stack transform to have these column set.
Now add the data set file and attach it to Stack transform and do all your transforms after the stack.
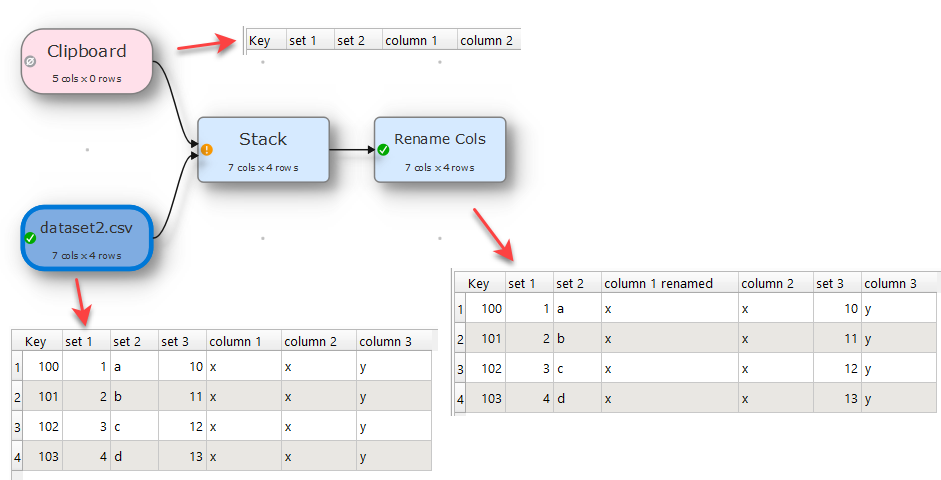
Even if you remove the link from the dataset file to the stack, your transformation that are done on the columns that you have set, will stay intact and any new columns will get added at the end, you then simply rearrange them as you need by using other transforms like Reorder Cols.
Just keep this in mind, that any transform that you do on columns that are not in your header list will lose their settings in the transforms, when you change file or break the link and attach it again to the Stack transform. That is why I said, that make the column header first that you will have or need in your transformation.
Problem seems to be, that there are spreaded columns, which means that there are additional columns created in the process, which lead to pushing the one in question to a different location.
Would it be feasible to have a feature, where i can select, whether EDT should reference to the internal number of the column or the column name, which would do the trick for @borntobedae i suppose?
And any news on v2? Can we expect it within 2023? I know, development is agile, but if it’s on the roadmap, i’d like to hear it:slight_smile:
Sry for my late answer, I just finished setting up everything for the renaming part. @Olaf, @Anonymous and @Admin thank you very much for the tips, the Stack transformation and the use of clipboard is working like a charm. You guys are the best!!!
@xeokydo Regarding the referencing for the internal number or column header, it would be an interesting and useful feature that changes and expands the use of EDT. The function could fully automate my process and there would be no need for manual changes.