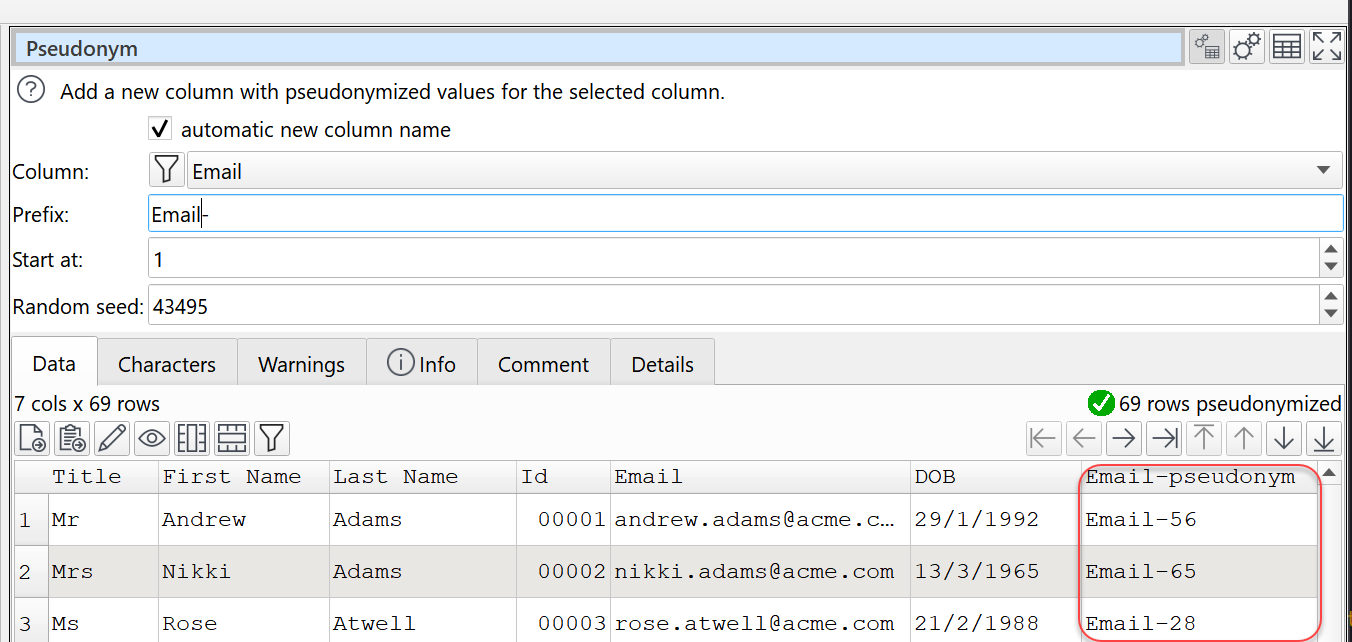
In case the pseudonym has to be build on more then one column the columns can be concatenated before.
My personal preference would be, in case the maximum number generated for pseudonym has n digits that the out has in every case has this number of digits. I.e. for 4 digits, that the first one starts with “Email-0001”, so that the pseudonym values have the same length.
@all: Please beware, that pseudonym values are not allowed when it comes to personal data under GDPR.
Please, I don’t want to discuss if that’s nuts or useless or else… it’s not my idea… but that’s the reason why an IP address is considered personal data although next to noone has a real chance to get to know the person behind the IP. As long as it’s POSSIBLE it is considered personal data under GDPR
Not an expert either, but pseudonymous data are not forbidden, just regulated in Europe.
And then it all depends on what data you want to pseudoanonymize (your own, non confidential data required for tracking, but still not relevant to share with others)
No, exactly that is the problem. Data that can be traced back to the data subject in any way (pseudonym data) is considered personal data by the GDPR. I think IP-addresses are a good example. Although it is technicaly not very complicated to get the user using an IP at a given time. The group of people really beeing able to get this information is very limited. Some people working at the access provider. And you and me have next to no possibility to get those people to tell us the identity. You need the police or a court to get this information. But it is theoretically possible and therefor it is considered personal data governed by GDPR
mhmm… I know what you mean, but in reality, GDPR forbids processing of personal data UNLESS you can prove a legal basis for processing.
So Pseudonymous data is still personal data under gdpr and thus needs the legal basis.
I just wanted to stress, that pseudonymisation of personal data is not a way out of the problem…
That’s another problem with pseudomised data. It depends on you what you can get out of it.
But in the end, the ip as a personal data item is the reason for all the issues we see with privacy on the Internet all those cookie banners and so on. Regarding GDPR, I think the lawyers and courts treat the ip as pseudomised personal data, because you can get the person using the ip from the access provider.
btw: the presence of the lookup table does not change anything in this respect unfortunately.