I have a lot of times to evaluate sets of files and collect the results in a “collection” file, which needs to be evaluated further.
Currently it is required to build a transform script to evaluate the source files in a batch (or in an external script) and write the result in append mode to “collection” file. Before running this, it is necessary to delete the old file otherwise it would append to the already existing file. Then a second transform script needs to be built to process the “collection” file. I create such flows a lot and script the activities and the necessary file deletions, etc. and it works fine.
It would be good to have possibility to mark and run only a part of an EDT script as batch and collecting the outcome in an append table within the script. Further steps are done on this table (these steps should be executed when batch part is finished). This would avoid the interim file, the file deletion process and some handling would be more intuitive.
For sure this has major design impact if it would be possible.
At least you can do that currently, by connecting output of your various transforms to Stack Transform (I am assuming here that all output have the same structure), it will collect all your output in order you provide connection and then you can do further transformation as per your requirement on the output of Stack transform and finally save the result.
@Anonymous as I see it your suggestion would work only if it is a fixed number of input files and the EDT script would need a lot of multiplied branches. If you need something adapted it will be a nightmare. And in my case the number of input files can change every other day. Therefore it is better to run in batch mode with a joker for the input file names or in a terminal script using joker for the file names, too.
I will have to think about whether there is a simple way to do this. A lot of people already find the batch processing feature complicated.
Perhaps batch processing could have the option to run a selected .transform file one the batch processing was complete? This could then process the output file created by batch processing.
But probably the best way to handle the above it to write a batch processing script that calls the Easy Data Transform via the command line. You can loop over all files matching a wildcard in a script on Windows or Mac. So:
delete appended.csv
foreach file matching *.csv in folder
call .transform file which appends to appended.csv
call .transform file which processes appended.csv to final.csv
In v2 I would like to make this easier by optionally allowing wildcards (e.g. *.csv) to be supplied to an input instead of a fixed file name, it would then do the stack automatically.
as stated, I script it, I like the flexibility which is available with the batch processing and the scripting, but I have some of such scripts:
cd /_____/TMP_Reporting
rm Total_TC_Exec.xlsx
cd All
for f in *.xlsx; do /Applications/EasyDataTransform.app/Contents/
MacOS/EasyDataTransform '/_____/TMP_Reporting/
01_Combine_Execution_templates.transform' -file
'HeaderConcat_w_Meta=/_____/TMP_Reporting/HeaderConcat_w_Meta.xlsx[Tabelle1]'
-file 'HeaderConcat=/_____/TMP_Reporting/HeaderConcat.xlsx[Tabelle1]'
-file In=$f -file Out=/_____/TMP_Reporting/Total_TC_Exec.xlsx -cli -verbose;
done
cd ..
'/Applications/EasyDataTransform.app/Contents/MacOS/EasyDataTransform'
'/_____/TMP_Reporting/02_TC_execution_evaluation.transform' -file
'TC Execution=/_____/TMP_Reporting/Total_TC_Exec.xlsx[Easy Data Transform]'
-file 'Header=/_____/TMP_Reporting/Header.xlsx[Tabelle1]' -file
'Report=/_____/TMP_Reporting/Report.xlsx' -cli -verbose
And I like the power of it. The for f in *.xlsx loop process more than 250 files (and the number of files did change during time). One disadvantage of the scripting is that it starts and close now more than 200 times EDT, when the script runs you can take a short coffee break
I even put these scripts on my Mac into Keyboard Maestro flows which open afterwards the result file and do further activities.
So I was just suggesting if there is a possibility to get I done in one Transformation. By the way out of the other discussions about resource use I will try to change the interim file from Excel to another format
The command line starts the GUI program each time, which was a bit of a kludge to save development time. In v2 I hope to have a command line program separate from the GUI program.
I think supporting wilcards for the input file without having to use command line or batch would help here.
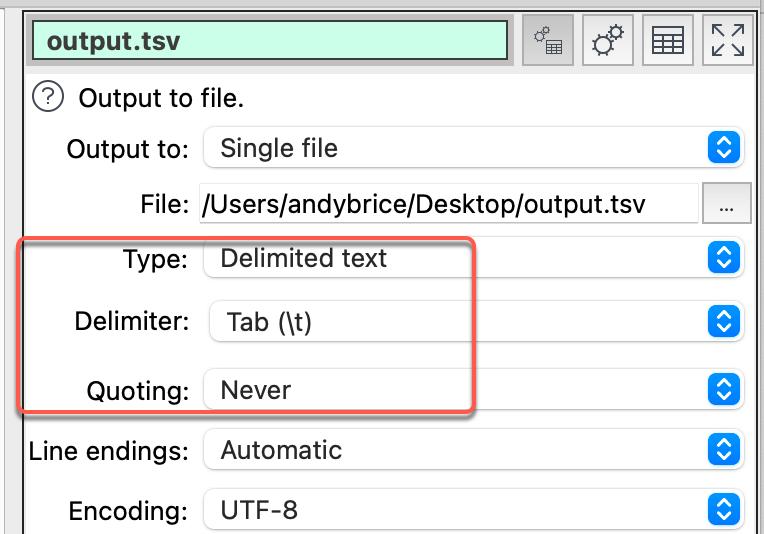
Reading and writing Excel files is slow. Probably the fastest format we support is delimited text without quoting, which is faster to parse. E.g. .tsv (tab separated values) where:
delimiters are tabs
no tabs allowed in data so there is no need for quoting
In batch I can run it for a defined sheet in the input Excel. If I use the terminal script in the loop I fail to use it if the sheet to process is not the first one. I didn’t found a way to get the [Sheet_X] into the “f” term. Do you have any idea?
Such ones I run individual in batch mode until now.
You can’t pass a wildcard here. And you can’t automatically loop over all the sheets in your script unless the operating system can somewhow work out the sheet names.
I took script as the transform file, and that is why suggested Stack for append table. That append table requirement could be solved by having stacked all the output before further work within transform.
I have not used the batch process capability of EDT, and to be honest, it is confusing for me, I tried one time, but just could not get handle on it, so I left it alone and so far all my needs were solved within the transform, so never invested much time in it.
The batch process feature uses your .transform as a template and applies to multiple files/Excel sheets. You use the input and output aliases to refer to the files in your ‘template’. It ended up a bit more complex than I would ideally like, but it has handle a lot of different scenarios.
If you are using a shell script and have a folder of csv-files you want to concatenate I have used another cli program called Miller - https://miller.readthedocs.io.
So if it is to cumbersome to make EDT do the concatenation, you could look in this direction.
EDT could then convert the concatenated csv to Excel or do other manipulation afterwards.
Here is a command I have used to concatenate a folder of csvs.
Fascinated that you pull out this three years old discussion
For sure I will check in the next days. I think it will make a lot of transformation files obsolete which I use in a first step to concat files and enrich them in batch mode or command line. And use a second transform file for the final analysis.
I think most of them can now be done in just one transformation file. I will inform any findings.