I just created a mini example, maybe it helps to get a feeling for it.
Created 2 csv Input files:
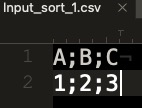
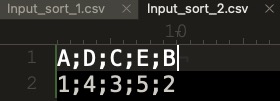
Values for A, B and C are identical.
just a small transform file:
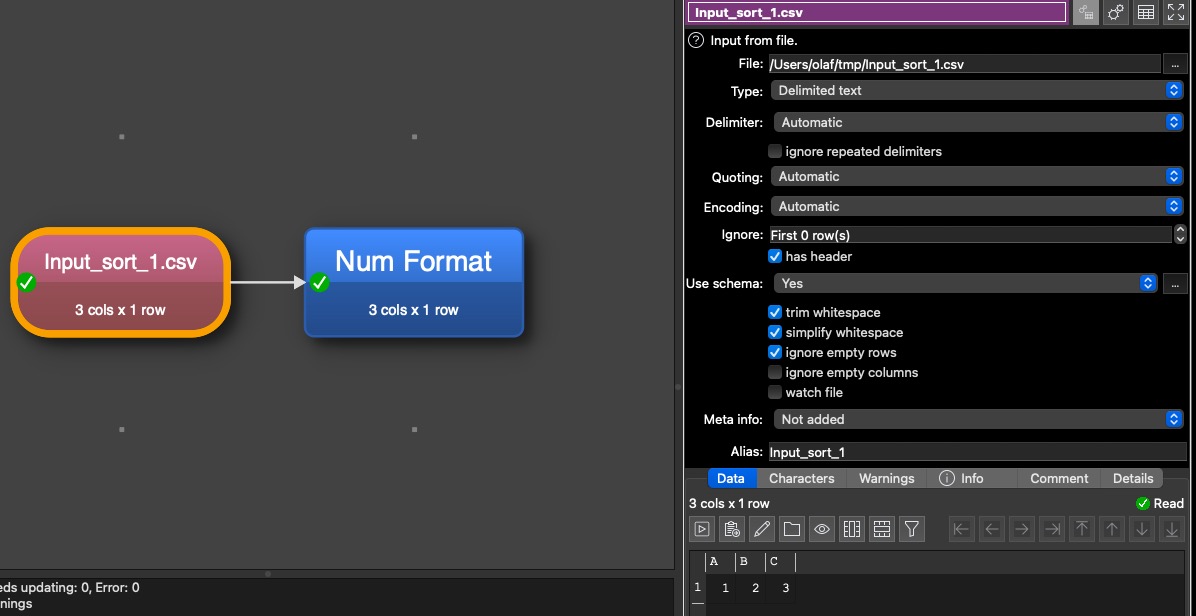
in the schema I marked to ignore additional columns which are not in the schema

If you change the input file to the input file2 result will be the same. Within the schema you can change the order of fields as you like.
Input_sort.transform (2.1 KB)
Input_sort_2.csv (19 Bytes)
Input_sort_1.csv (11 Bytes)