I got a transformation for a file, containing around 450 fields. I had to use different lookup tables, renaming and removing columns, joining etc.
Then i got a updated file, with around 550 fields, where the original 450 were included. So my Renaming didnt work, because he inserted the new fields in like it seems randomly order, which rendered my renamings meaningless, i hade to rename 200+ fields, because it didnt keep the relationship.
Would it be possible a) to keep the relationship or b) to add new fields at the end of the table, so it doesn’t interfere with renamings etc? If we do a lookup, it also adds the new field at the end of the table, so this shouldn’t be a problem, right?
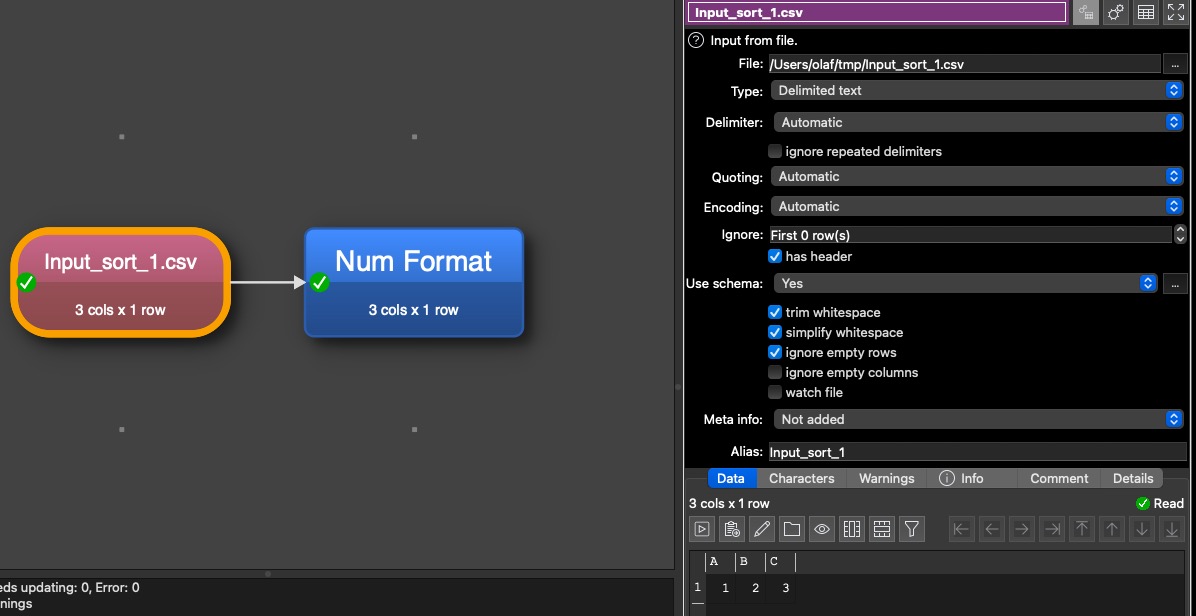
Have you looked into schemas, added in v2? They are intended to handle this sort of use case. If the original 450 fields still have the same names (regardless of the order) it should handle everything for you.
I just recommend to use schema in case of input files from foreign source when there is a risk that the field order or number of fields are changed. It will not help in case somebody change the writing of column headers.
I’ll give Schema a try. The export is a csv of a mysql database, and therefore the field names stay the same, we just get new fields added, and interestingly, the sort order of the fields in the new export were different compared to the old one.