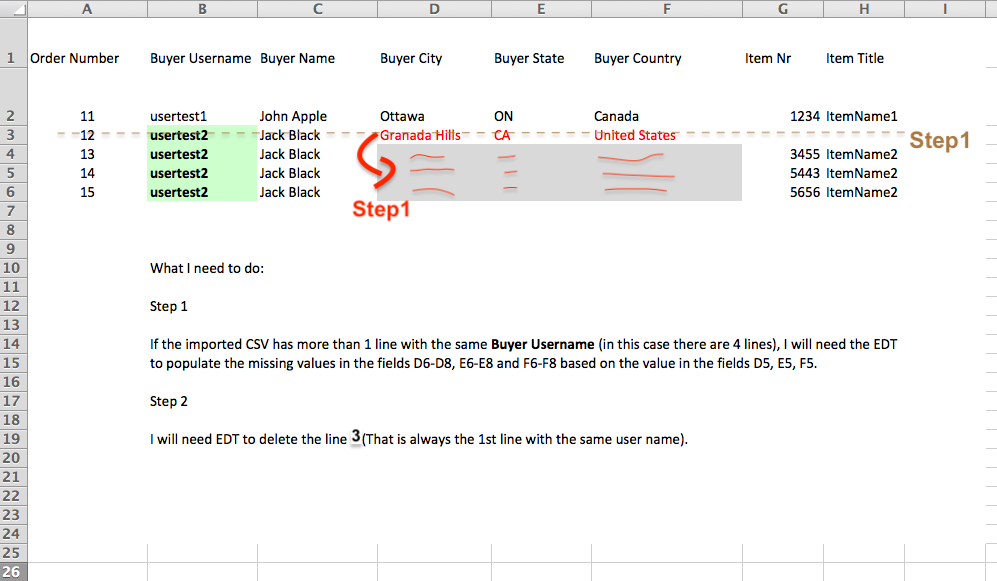
For group of records that have the same value in a specific field, I need to 1) populate empty (missing) fields based on an non-empty field and 2) then I need to delete the first line of the group.
This is complicated and I am wondering if this is even achievable in EDT.
Step 1
If the imported CSV has more than 1 line with the same Buyer Username (in this case there are 4 lines), I will need the EDTto populate the missing values in the fields D6-D8, E6-E8 and F6-F8 based on the value in the fields D5, E5, F5.
Step 2
I will need EDT to delete the line 3 (That is always the 1st line with the same user name).
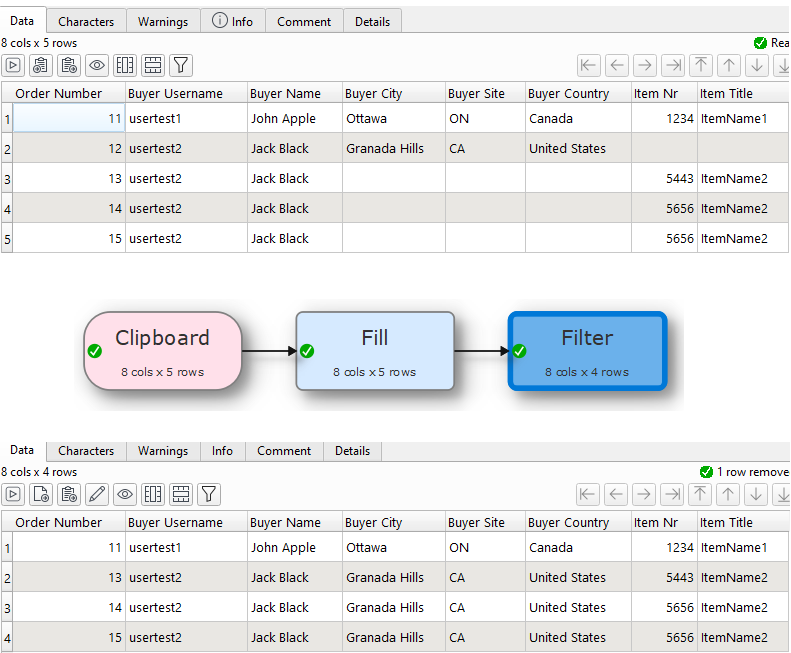
I suspect it may be doable with a bit of cunning and judicious use of Dedupe, Fill, Offset and/or Unique transforms. Can you please add (or email to support) a simple example CSV/Excel file and the corresponding CSV/Excel file you want, so I can be sure I understand correctly and have some data to work with.
If I understood it correctly and take it that the records will always be sorted on Order Number and Buyer Username and the first record in multiple records for the same Buyer Username has data for all the fields except Item Nr and Item Title and you want the remaining records for the same Buyer Username which don’t have values for fields Buyer City, Buyer Site and Buyer Country be updated from the first record and then remove the first record which don’t have values for Item Nr and Item Title