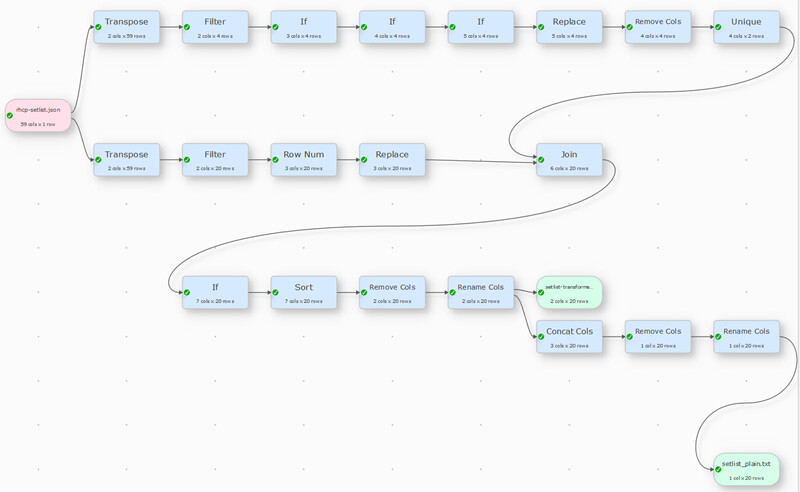
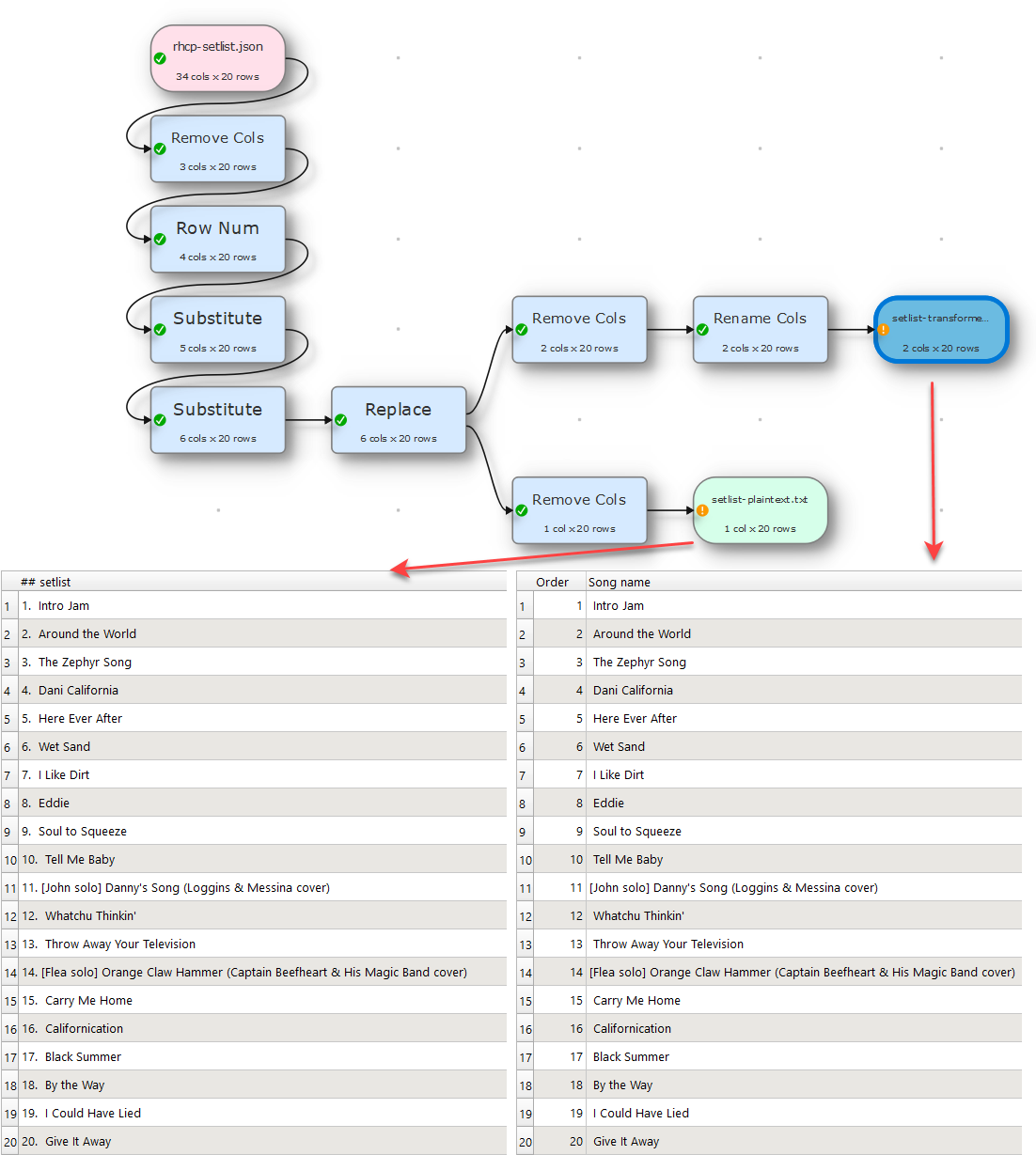
I wonder if an experienced user might be interested in taking a look at this flow to see if / where it could be optimised. I am on day 3 of my trial and although i can get the desired end result it feels like i am taking a more convoluted route than necessary. Has been a really good example though to learning about EDT and what it can do (other new users may find it useful to dig into).
Basically i have a test file which is the json response of an API query to setlist.fm. From that i want to extract all the song names to create an ordered markdown list. This on its own is straightforward. In addition to this though (and the bit in the flow that i think is a bit clunky) is that i also want to extract any notes about a song (contained in a node ending with .info) and the band covered (contained in a node called ending cover.name) for songs that were a cover version. Obviously not all songs have these components.
The end result i want is a single column with: [Song info] Song name (Cover band) for each song in the setlist. And obviously the notes and cover band info should only appear for songs that have that have either / or those components in the original json.
Have attached the json file and my test flow. Look forward to hearing where i might be able to improve this.
Edit: as a new user i can’t attach the relevant files. Oh well…