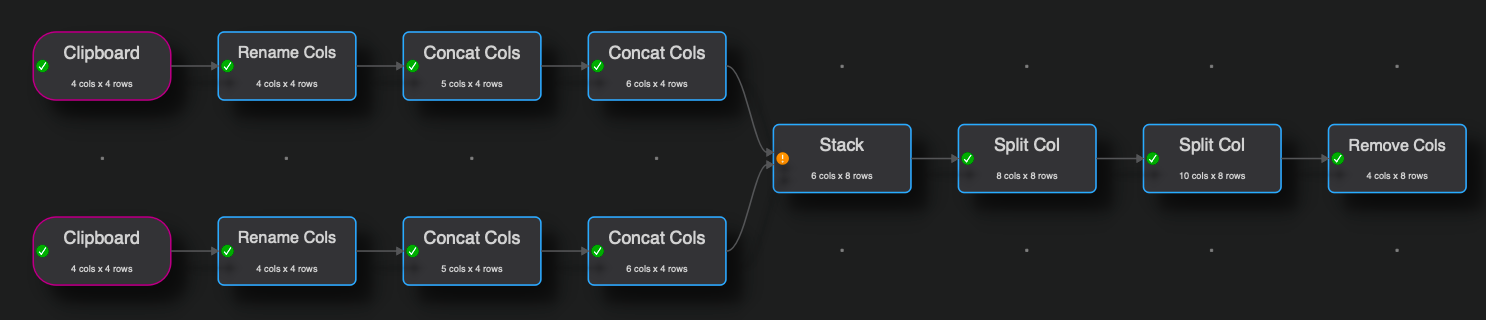
Hello, I have a problem matching unnamed columns (using “Stack”) and I can’t use “Rename” because I want to run this with a batch file without knowing the order of the columns in the input files. However, each unnamed column is preceded by a named column that it is matched with. If I were to run a “Stack” based on column name, the unnamed data from set A and set B would be mixed because they are both in column “2”.
Is there a way to programmatically rename columns based on the preceding column? Or are there any other ideas on how to resolve this?
Sample Input Data 1:
| CA | CB | ||
|---|---|---|---|
| 05:43.0 | 1 | 05:43.0 | 10 |
| 05:43.1 | 2 | 05:43.1 | 20 |
| 05:43.2 | 3 | 05:43.2 | 30 |
| 05:43.3 | 4 | 05:43.3 | 40 |
Sample Input Data 2:
| CB | CA | ||
|---|---|---|---|
| 05:43.4 | 50 | 05:43.4 | 5 |
| 05:43.5 | 60 | 05:43.5 | 6 |
| 05:43.6 | 70 | 05:43.6 | 7 |
| 05:43.7 | 80 | 05:43.7 | 8 |
Desired output after stack:
| CA | CB | ||
|---|---|---|---|
| 05:43.0 | 1 | 05:43.0 | 10 |
| 05:43.1 | 2 | 05:43.1 | 20 |
| 05:43.2 | 3 | 05:43.2 | 30 |
| 05:43.3 | 4 | 05:43.3 | 40 |
| 05:43.4 | 5 | 05:43.4 | 50 |
| 05:43.5 | 6 | 05:43.5 | 60 |
| 05:43.6 | 7 | 05:43.6 | 70 |
| 05:43.7 | 8 | 05:43.7 | 80 |