Hello all, is there a method to merge 3 data sheets in 1 output in a batch process?
Ex.
(Input)
A1.xlsx
A2.xlsx
A3.xlsx
B1.xlsx
B2.xlsx
B3.xlsx
…
(output)
A.xlsx
B.xlsx
…
thank you in advance!
Hello all, is there a method to merge 3 data sheets in 1 output in a batch process?
Ex.
(Input)
A1.xlsx
A2.xlsx
A3.xlsx
B1.xlsx
B2.xlsx
B3.xlsx
…
(output)
A.xlsx
B.xlsx
…
thank you in advance!
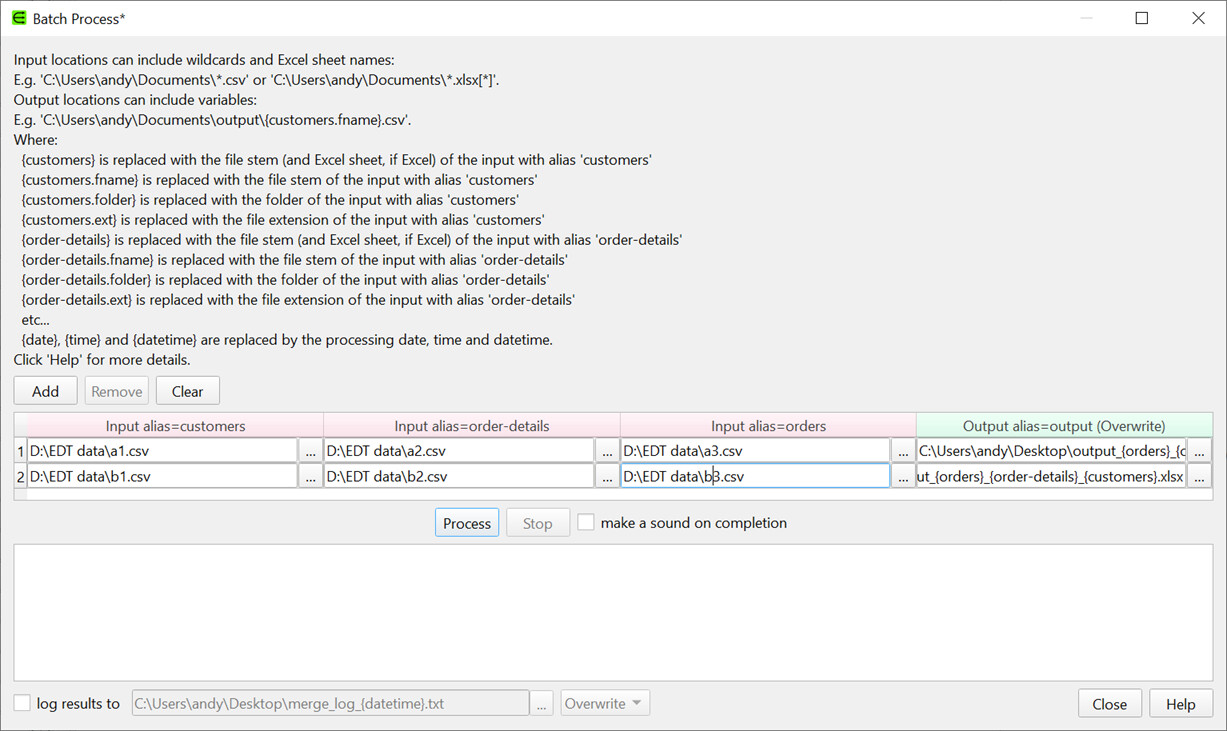
Yes. Create a .transform file that merges 3 example files into 1 output (e.g. using Join or Stack).
Then run File>Batch process add Add a row for each output you want, setting the inputs accordingly.
You can also run Easy Data Transform from a script using the command line:
Windows: Reference > Command line arguments
Mac: Reference > Command line arguments
Thank you very much for your quick answer. But do I need to do each batch process individually for 3n inputs and n outputs if n=50?
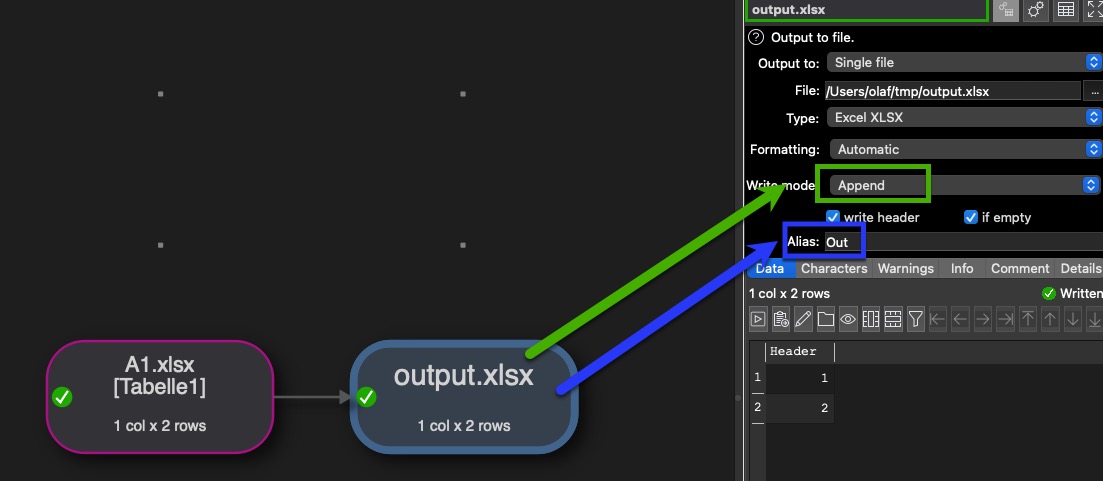
Would choose a little different way to Admin’s suggestion. Build a graph just reading in and write the file in “append” mode
This I would put into a command line script, which uses the batch mechanism. Here the Mac OS example (the blue marked Aliases are used in the command line loops):
cd /Users/olaf/tmp
rm *_output.xlsx
for f in A*.xlsx; do /Applications/EasyDataTransform.app/Contents/MacOS/EasyDataTransform ‘/Users/olaf/tmp/Merge_example.transform’ -file In=$f -file Out=/Users/olaf/tmp/A_output.xlsx -cli -verbose; done
for f in B*.xlsx; do /Applications/EasyDataTransform.app/Contents/MacOS/EasyDataTransform ‘/Users/olaf/tmp/Merge_example.transform’ -file In=$f -file Out=/Users/olaf/tmp/B_output.xlsx -cli -verbose; done
In the command line script you can add now one for loop for each File name pattern wit a given output file name. The rm (deletion) commanding the script is important as the out put would be appended to existing files.
It depending on the details of how the input files are setup. Do all 3 files have a common naming convention? Are they in a separate folder from other input files?
The approach suggested by @Olaf should work fine if you are appending the files ‘vertically’ and they all have the same column structure.
Yes, the files have a common naming convention “type_subtype_yyyymmdd_package_{1,2,3}”, where the date is the indicator for a data merge. All data have the same column structure as well.
The single packages can be separated into folders, but only splitting by package number. To split in date is not really feasible. Splitting in type/subtype is not an option.
Okay I will see if the approach from @Olaf will be an option.
if you use it long term productive, it is strongly recommended to add some safety nets, like the “stack” function to ensure that the rows are in the same order before you write out the result. But then you might one EDT “graph” per file structure.
Subfolders shouldn’t be any issue you can change the folder in the command line script for each execution.