A thing that I think might be a worthwile addition. Right now, unless of course I am missing something (likely), you can only combine all or 1 value from crossreferencing two files, using either lookup or some variant like join.
However, I find that I often need to get a csv file combined with 2-3 fields from another csv source, with both containing a whole lot of fields. I can of course do this is multi-steps, like removing columns and then joining them, but it would be nice to be able to do a lookup and just select multiple fields to join in - doing a similar check of fields like you do with eg Remove Cols.
You are right - didn’t think of it that way, I was just focused on it being more rational to add 2 fields from a huge file of 50 columns, but the amount of data is probably negligable in the grand scheme of things, so Join then Remove is doing the same. Strike that request!
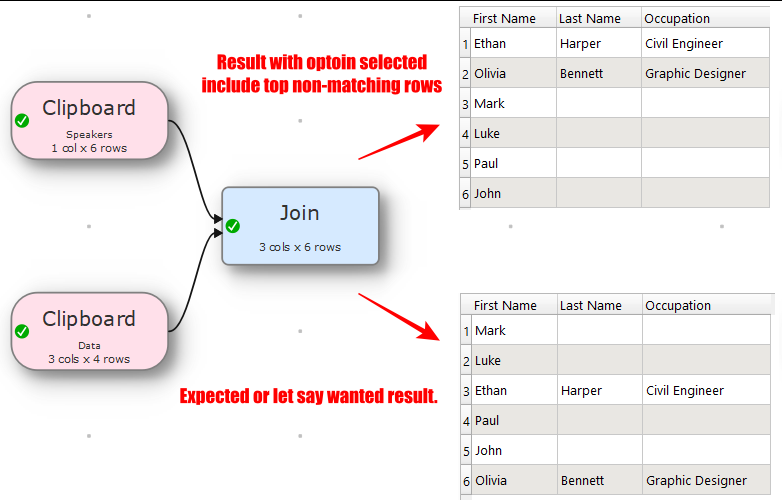
No it would not, if you like to keep your data set in order, because after join the order of records does not stay the same, specially if you want to keep data that had no matches.
In this scenario, you need to add Row Num transform to add row numbers, that are used by another transform Sort to get back the data in same order before join, so there is Two transform extra.
Now after join, you need to remove the columns you don’t want, so that is another transform Remove Col and that makes it Three extra transform and if you have large number of rows, so data in those three extra transforms is memory wastage plus extra processing steps.
In my opinion not optimized way of going about it, but that’s me, I don’t like any wastage in any sort let it be computer related or any other work.
But if Join transform keep the order of the data set same and leave joined columns empty for the data which it could not join, when one wants to keep the data intact, then only One extra step is needed to remove the unwanted columns from the join operation.
Or if capability is provided within Join transform that only bring selected columns, instead of the whole column set, then that extra step of removing columns is not required either.
OR
As @egilDOTnet has suggested, that provide a choice of columns to be returned from the Lookup transform and with that change, in one transform you have your data order maintained in addition to new columns that was needed from another data set.
Join can join 2 datasets by row number. Set By to Row number. This was added a few releases ago.
It might be useful to allow Lookup to take more than one column from the bottom dataset. I think that would be cleaner than excluding certain columns from the Join. I don’t think it is a priority, but I will make a note of it.
As you can see, the order of the data is changed and to keep the order, you have to add row number then do the join then sort back on row number to get the original order and then remove unwanted columns
But if the order is maintained, then no need for row number and sort transform and if choice is given to select which columns are needed then no need to remove columns as well.
Speaker
First Name
Mark
Luke
Ethan
Paul
John
Olivia
Data
First Name
Last Name
Occupation
Olivia
Bennett
Graphic Designer
Marcus
Caldwell
Software Engineer
Sophia
Ramirez
Marketing Manager
Ethan
Harper
Civil Engineer
If Lookup have option to select multiple columns then no need to change in the join transform.
Currently we are forced to do a concat in TOP and Bottom to generate a unique column , if bottoms are allowed or take multi , then top will benefit too (or I misunderstood)
SQL lingo means
Year=Year &
SalesID=SalesID &
QuarterID=QuarterID
Currently I have to do a concat and join all there Year+Sales+QuarterID in top , then same in bottom , then do relevant join /lookup
I was referring to taking multiple value columns from the bottom dataset.
Multiple key columns for Join , Lookup etc might also be a possibility at some point. However, if we spend all our time tweaking the existing transforms, we will never get around to doing the other things that people are asking for, such as: