I’m a long time owner but first time user of EDT. (mostly solved problems with SPSS or files not complicated / large enough to feel I needed to put it into practice)
No I think I should have learned earlier as now I really need it. I have a research file that has cases labeled i.e. case 1 / case 2 in the identifier column. file is in “long format” as each case has multiple rows that correspond with timepoints column. I.e. time point 1 / 2 / and so forth.
There are multiple files that have different measurements information. and even though one file has 3 time points for a case others might have 4, some have only one. Therefore you can’t just sort the files and paste them together.
i.e. data looks like
case ID. timepoints. variable A
case 1 time 1 45
case 1 time 2 39
case 2 time 1 45
and in file two
case ID. timepoints. variable B
case 1 time 2 X
case 1 time 3 Y
case 2 time 1 C
What I would like to do is merge the info in file two to file one if the case and timepoints match. That means here that Case one time 3 from file two would remain unmatched (or ideally I would create a new tow in file one including that date and the “new” timepoints.) and that case 1, timepoint 2 would have a new variable column introduced containing variable B.
is this possible, that is matching information on two conditions (case ID and timepoint)?
Hi and thanks for the swift reply.
The spaces imply column breaks i.e. each of those in separate columns. Hope I’m expressing myself correctly. Each entry starting with a case is a row.
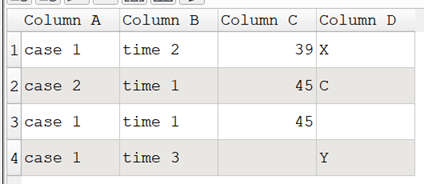
This is what it should end up as output.
Column A Column B Column C Column D
case ID timepoints variable A variable B
case 1 time 1 45 no value
case 1 time 2 39 X
case 1 time 3 no value Y
case 2 time 1 45 C
So I would need a logic routine somewhat like: check if case ID and timepoint column matches, if yes, then insert value for variable B. If no match for case ID and timepoints insert new row with variable B anyways leaving variable A blank (as there is no matching case in the original file there wouldn’t be a value for A).
Cool. I’ll try this out.
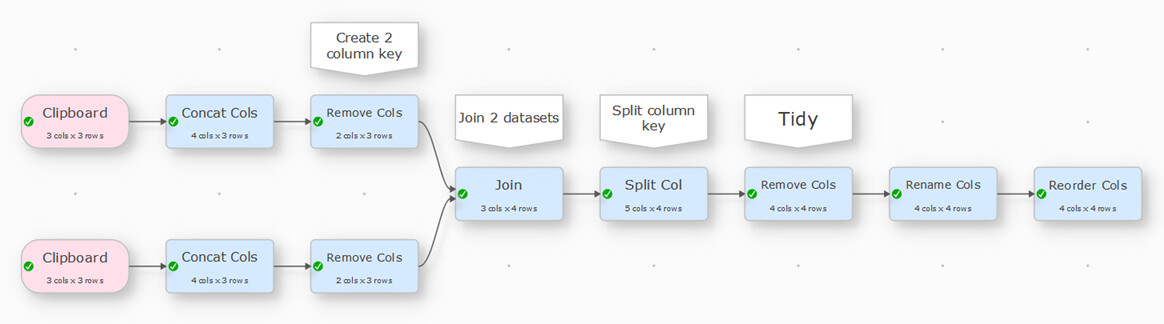
for my educational benefit, why is there a remove cols? can I just import the workflow and adjust the terms to match the actual names in the files? can I reverse engineer what you have to learn how to do this myself? sorry for being a complete noob. I’ve started to watch the videos and normally I’d tinker myself for a while but have some timescale this needs to be done by unfortunately. Your help in this is much appreciated!
if you don’t do it, you need to do it later and you have unnecessary data in the further transaction, If you try it without the remove you need to do the split anyhow otherwise you have other problem:
I think I understood this while going over the file you send. You merge the case ID and timepoints to create one single column that you can then easily merge and then split the unified column to get back to the original format. Do I get this? You can then expand this to any amount of variables you want to include in the merger, right? Genius. Thank you so much.
The original columns are surplus to requirements once you have done the Concat Cols. You could get rid of them later on to reduce the number of transforms.
last question, can I use your template and just plunge my files into it and adapt the sample process to the current names or should I start from scratch?
Currently you can’t replace Clipboard input with file input without loosing the downstream column settings (something we hope to fix in future). So you will need to:
-delete the clipboard inputs
-drag on your files
-reconnect the connections ( Reference > Connections )
-reset the column related parameters
-probably add an output