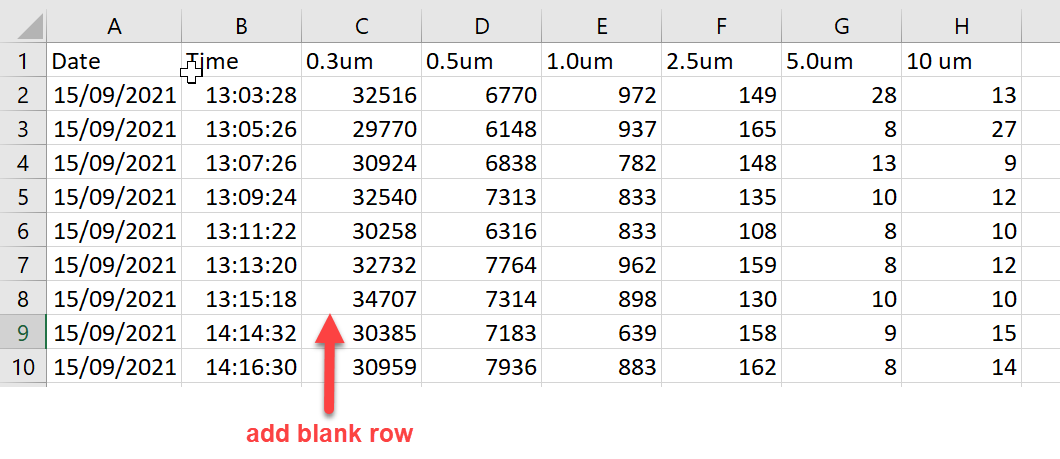
I have files such as the one attached which include a series of time observations, which are stopped and then restarted for another set of readings. The sequence is interrupted when more than 5 minutes occurs between readings.
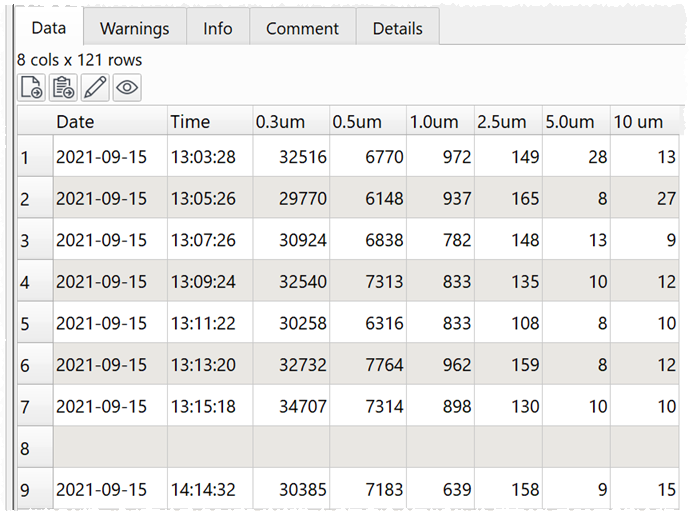
I would like to have a transform identify when a run is ended and place a blank row in the output file before continuing to write the data to the same file.
I wonder if you have any suggestions about how I might be able to do this?
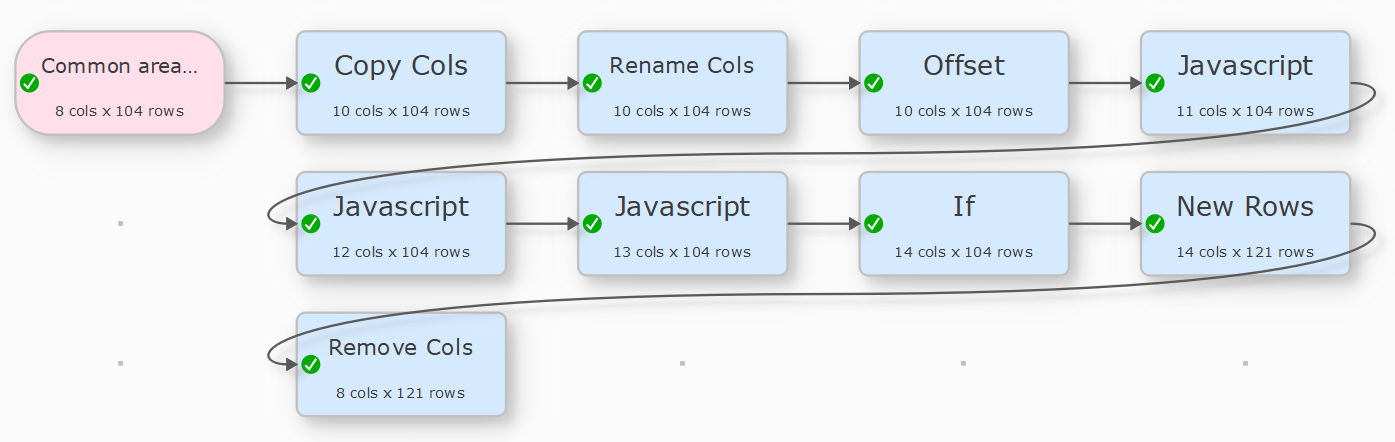
copy and rename the date and time columns (Copy Cols and Rename Cols)
offset the new columns by 1 (Offset)
convert the date and times into datetime strings that Javascript understand (should have done this before copying the columns in retrospect!) (Javascript, could have used Concat Cols)
calculate the difference between the datetime and the offset datetime in seconds using javascript (Javascript)
decide whether to add a new row based on whether the difference between the datetime and next (offset) datetime is > 300 seconds (If)