One thing that we run into a lot is when our source data changes a format or has new data, like a new column as an example. We will have these long and complex conversions and then the input file changes and the new column can throw off lots of downstream stuff. this is the single hardest part we have found about using the transform program. If this doesn’t already exists, I wonder if there would ever be a way to say something like “the new input data doesnt look the same, are there new columns we can ignore”. I know that I can add a transform as the first step and remove the column, but to do that I have to first add the new input format and that alone will sometimes blow up filters and lookups downstream. hoping this makes sense.
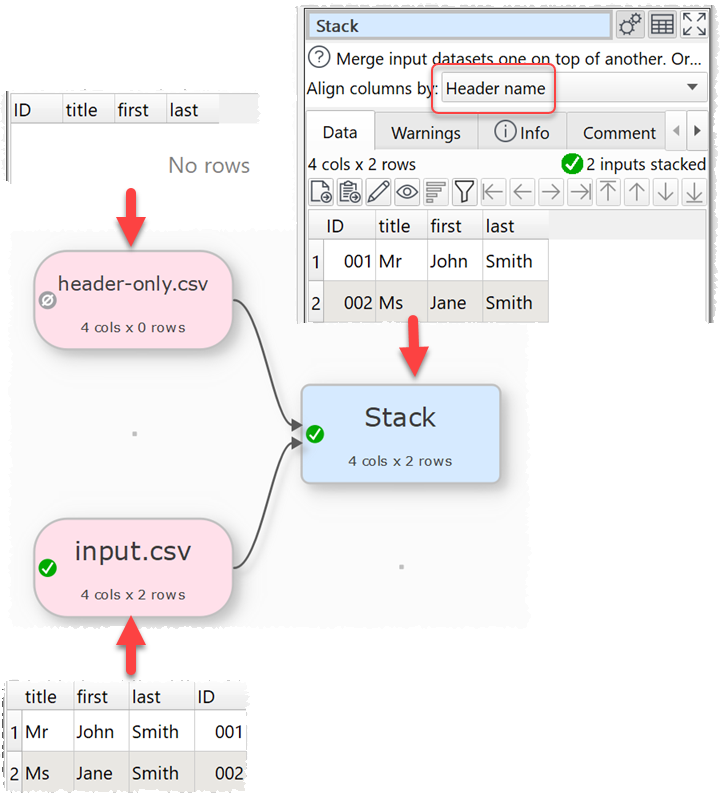
The way around this is to use a Stack to place all the expected columns in a particular order. Any unexpected columns will then be added to the end.
2 Likes
Ok, so in your example if a new column, say “birthdate” all of a sudden was in the input data, it would push that to the last column and then not impact any downstream transformations? with our developers, I can often have them add additional files to the last column, but I thought that would still impact the downstream conversions. ill try it out.
If you check use only top dataset columns then it won’t add any columns unless they are in the top dataset.
Coming across that as well and Stack is helping a lot, but it would be great if we could set the columns and order within the transform so we don’t have to keep separate template files.
Maybe calling it something like … Structure or Lock Columns?
The way I see it working is that the first time it is placed, it reads the columns in its input and puts them in a list. This way it can be added into an existing transform file before a new file with new or reordered columns is being read and the transform will stay intact.
Then have an interface that allows us to remove the columns we don’t want to keep and also to manually add/enter new columns if we want to have new columns in new files.
The key here is that it does not change the columns by itself any more if its input changes.
You can use Input from clipboard to add known column header to use with Stack. Then check use only top dataset columns in the Stack if you don’t want to add any additional columns. I’m not sure any additional functionality is needed.
what do you mean about “input from clipboard.” How does that prevent you from having to have a “column header file” for each transform. We have about 30 of them we use pretty consistently.
Hi,
What it means is that instead of using a file for the headers only, you can create your headers and then simply copy it to clip board and then in EDT use input From Clipboard, this way the headers are saved with the transform file and in future if you need to re-arange the columns simply create the new headers and select the Clipboard transform and then click on the Play button on the right pannel to import the new Headers.
Add Stack transform and add your file in whatever way your headers are, since the column headers are used from the clipboard and stacked based on headers.
This way even if you remove the file and add another file, your transforms down the line will stay intact or you can add additional file with same column in different order
For example:
Headers only
column1,column2,column3,column4
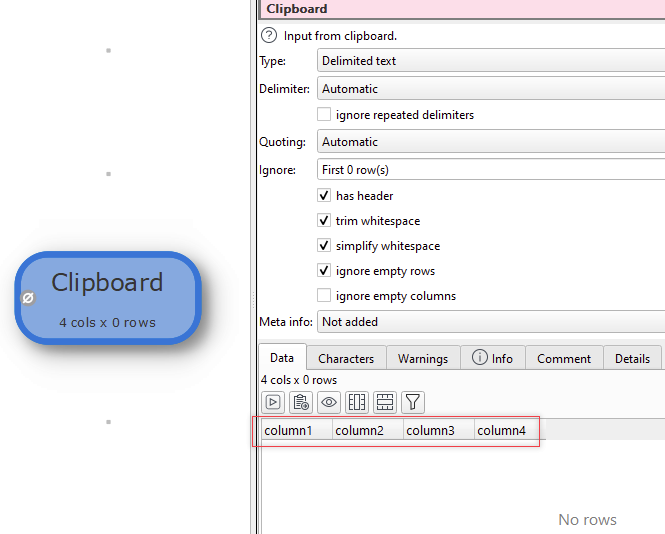
Add Stack trasnform
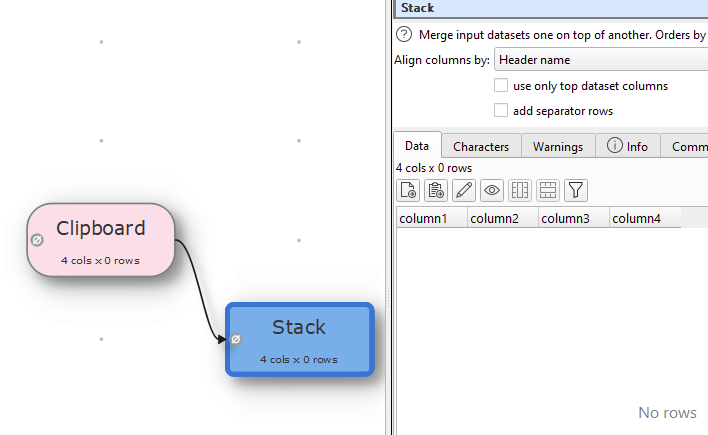
Add file1.csv
column1,column2,column3,column4
change me to upper,2,3,4
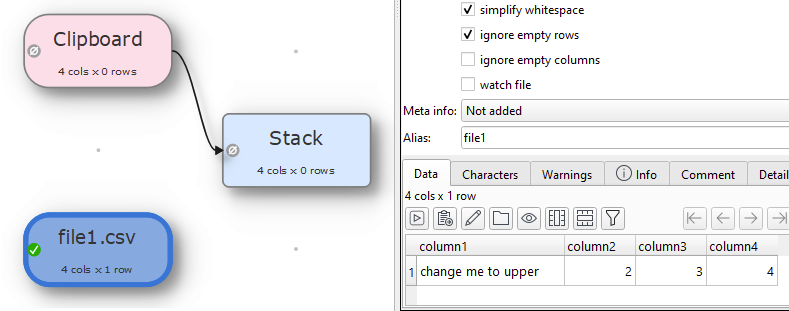
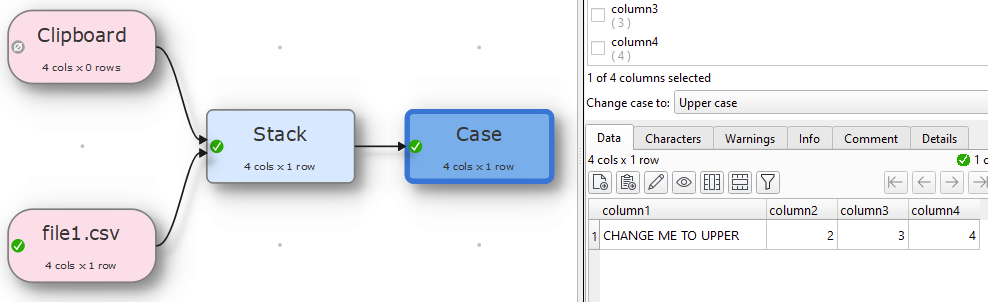
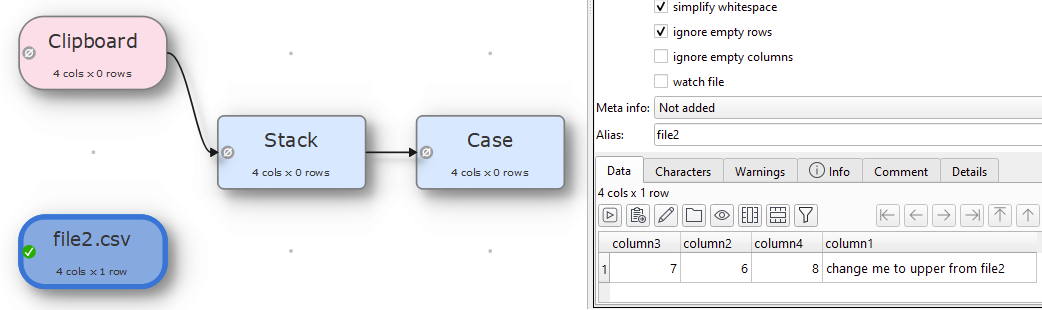
Now if you remove file one and add file2.csv that have the same column header but in different order the transforms will still work
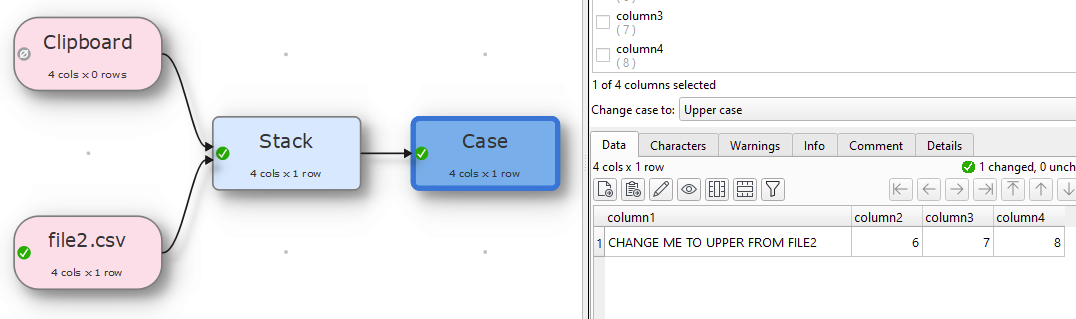
2 Likes
@Admin - I am still not understanding this and the new columns to data is really impacting how we use this program.
Even with the example from above, I dont understand how the clipboard function works. The way I understand the clipboard is that it’s a temp file that is created any time I copy something. As an example, I had just copied some data and when I tried to walk through the example above, and I inserted from clipboard, it was the data I had just copied.
Then to test, I copied something else and reprocessed the transform and the new data was now on the clipboard step.
My brain is not able to understand how something that is driven by variable use of the copy function on my computer is able to help me in this situation.
P
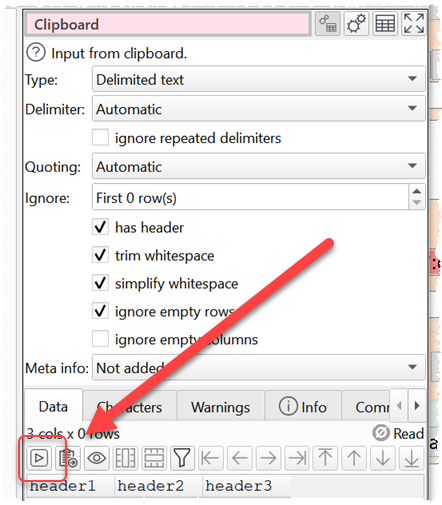
With Run>Auto Run checked, if you copy this:
header1,header2,header3
And then click From clipboard you should get this:
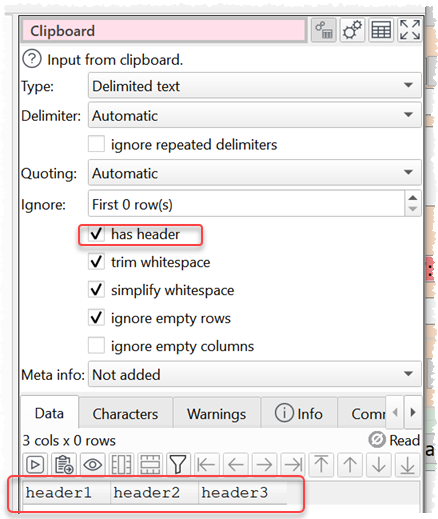
This dataset (with just a header) is then frozen in the .transform file and can be used for Stack etc.
If won’t ever change, unless you copy something else to the clipboard and click Import from clipboard:
It is on the wishlist to look at more sophsticated ways to handle changes in columns name/type/ordering (‘schema’) in v2.
My guess is that the downstream logic is associated with a column number and not a column name. even when I use a stack to lock the headers in and then add new columns at the end… by the time I do thinks like split cells/copy etc, the “end” is now 4th from the end and anything after that blows up. let me review what you said above and see if I can duplicate what you are talking about.
ok. I get what you are doing with the clipboard now. not sure how it’s any different than just have a saved file with “watch” on it and add new columns as needed. it still is going to blow up down stream stuff at a certain point. I know you are working on it Andy, and I always appreciate how responsive you are! Take care and have a great weekend.
Internally we are looking at the column position (index). But there would still be issues if we were going it by name. Schema versioning is tricky.
Issues can occur from transforms like Split Col where you can get a variable number of columns. But you can set Min values and Max values to the same to always get the same number of columns.
If you set Stack to use only top dataset columns then any extra columns will be ignored.
It is guaranteed not to change (unless you explicitly change it). Whereas a watched file can change.