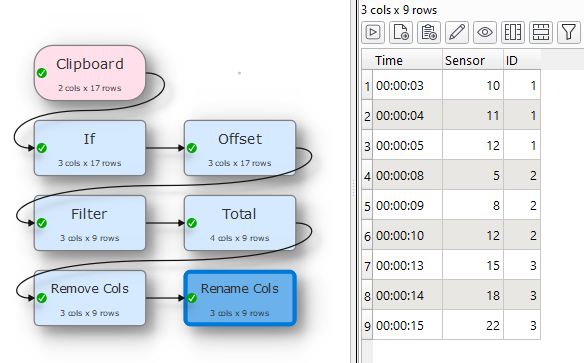
Hello,
I have a dataset with sporadic events of clustered values. I want to remove the rows with values less than 1 (which seems straight foward), then sequentially ID the events seperated by the dead space.
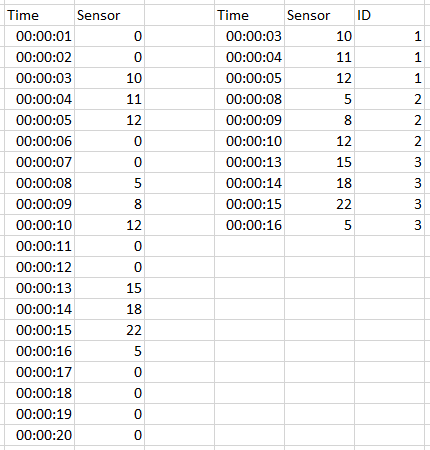
Thanks!
Hello,
I have a dataset with sporadic events of clustered values. I want to remove the rows with values less than 1 (which seems straight foward), then sequentially ID the events seperated by the dead space.
Thanks!