I am wondering if Easy Data Transform could help me to verify if the CSV file columns headers are what they are expected to be. I download a CSV file regularly. The company producing the CSV is notorious for making unannounced changes to the CSV file without giving any sort of warning in advance or after the matter.
I am less concerned about the columns moving around and more concerned about the names of columns (fields) change. If columns name change, the values will likely change as well. So without being warned about it my import would import the CSV without importing the changed columns properly. I use Airtable to import the CSVs. The import in Airtable works well for CSVs if they remain same. If column moves around, it’s not an issue, but if the column header name changes, the import would not stop but would continue and would simply skip the columns that are missing and will not import any changed columns names.
I don’t think I can expect Airtable to add any CSV checking process because that is really not Airtable problem and they are a database company, so having an import tool for CSV, that is what they do have is all they would provide. Making sure the CSV is correct, would need to be done before that.
So I am thinking Easy Data Transform could be a great tool to do that since I can see it already does so many things.
I looked at the Javascript option and I don’t know if this is something that could do that, or is there anything else I should take a look at.
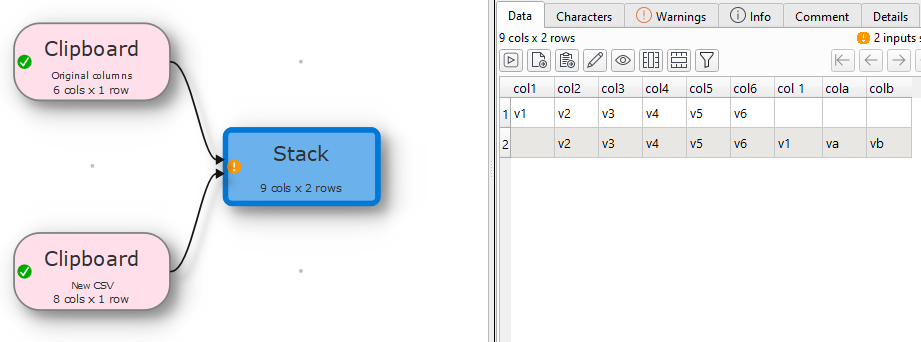
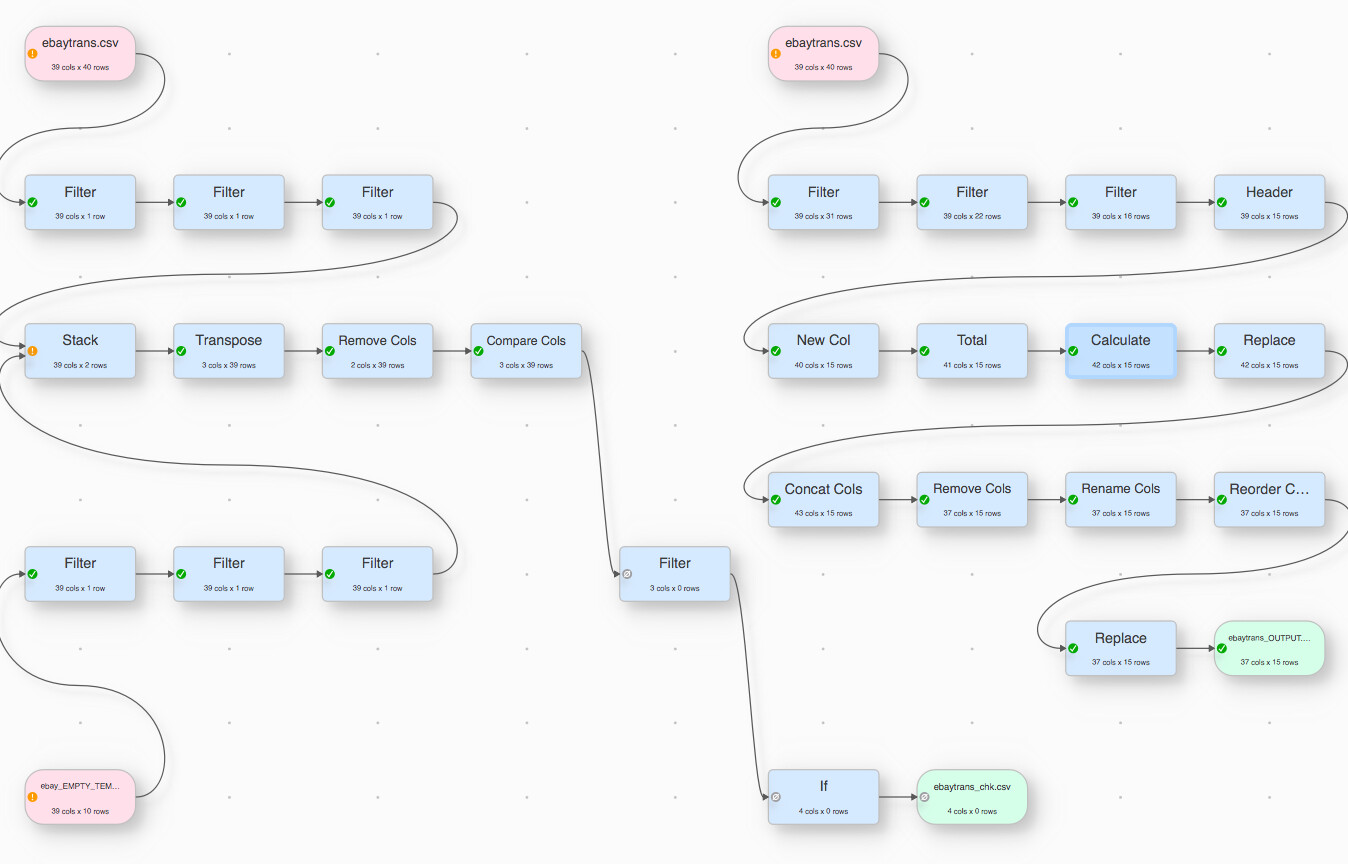
From what I read I may be able to take my original CSV template (empty) file and then either compare that against the newly downloaded CSV (after removing data) and then use e.g. Araxis Merge app to compare the files. Or I could just use EDT to compare the column names, but it requires quite a long javascript statement.
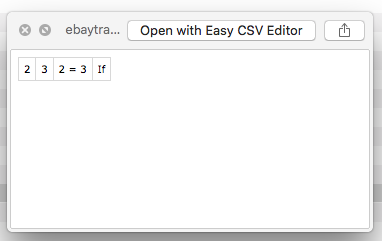
All I would be happy if I could create somehow a CRC value or something of all column names in the CSV file (or even count the total number of characters would suffice) and then compare it with a control number (which is what I would know my original template file has).
I am not a programmer so I am pretty much improvising here. Maybe a solution to what I am looking is pretty simple, which would be great. I am all ear.
I see here this page has description about Hash check but it seems only capable to handle values but now the column names?