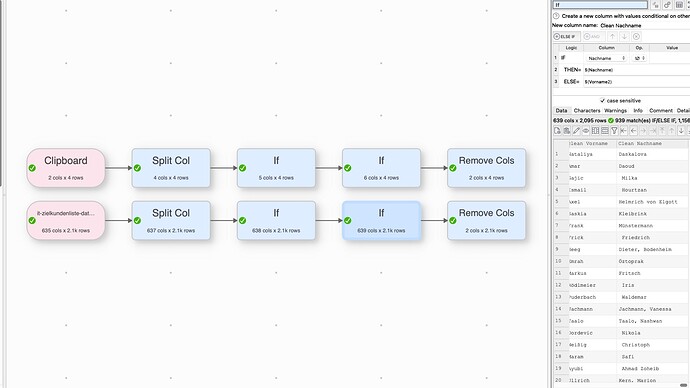
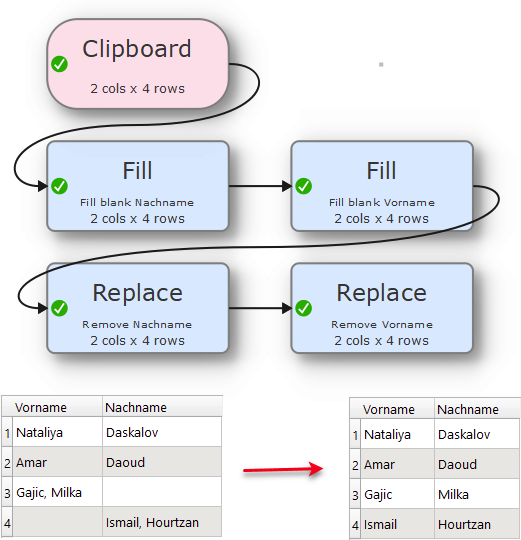
Hi everyone!
I am trying to reformat some data my colleague sent me. The chief problems are that in the Vorname column, there are sometimes names in this format: “Last Name, First Name”.
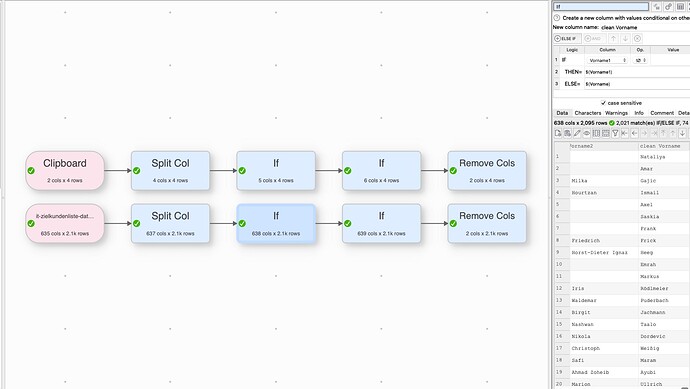
I have tried to fix this with a Split Col. For the most part, this has worked, which is good. However, whenever my colleague has correctly entered the data and has put first name and last name into the right columns, the split col messes it up.
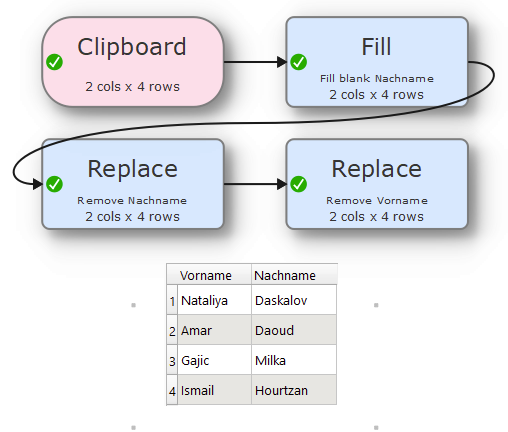
See example:
Here, Nataliya Dasklova is entered correctly.
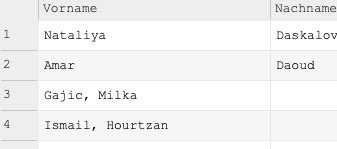
However, it is messed up when you look at the First Name and Last Name columns. Why is this?
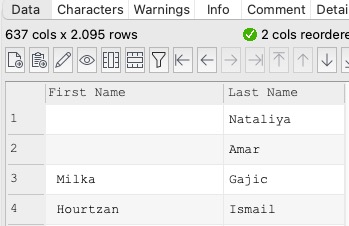
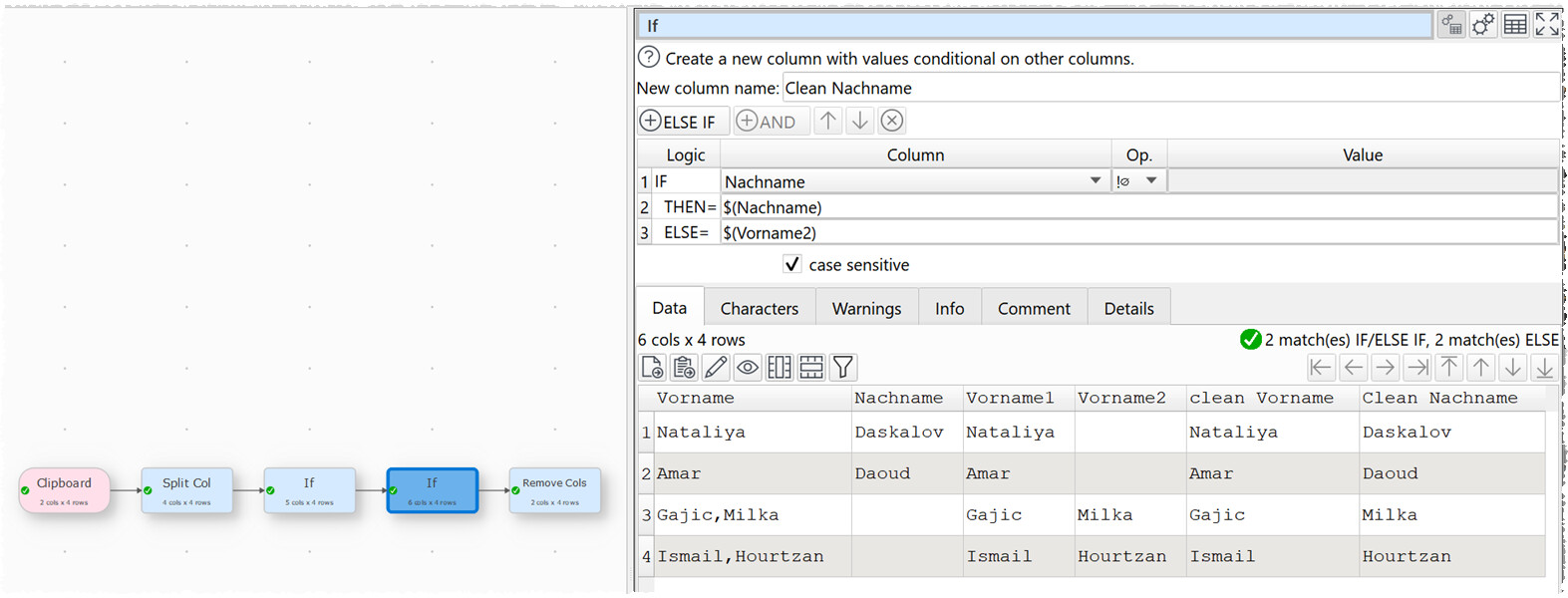
To be clear, Vorname and Nachname are the original data columns and First Name and Last Name are the reformatted data columns.
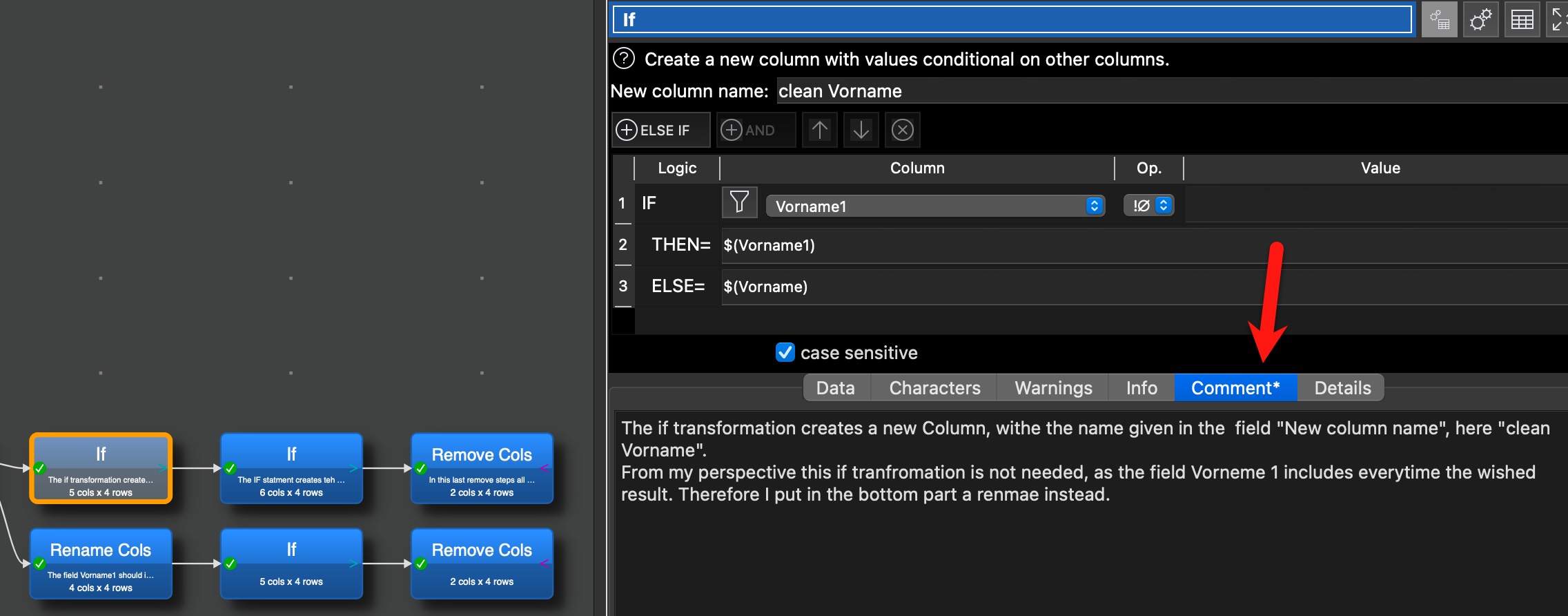
Whenever names are already written correctly, what is in the Vorname field appears in the Last Name field and what is in the Nachname field does not appear at all. Explain the functions Easy Data Transform has which can help me solve this. It would be best if there were a way to make the Split Col conditional on something, but the If function does not seem to do that.
I do not see any option in the Split Col function itself to introduce this condition either. What can I do to introduce a condition?
I have looked at the topics of other users revolving around conditionals, but none of them have helped me so far.