Some knowledge sharing which might be helpful to others
Problem we solved
- Individualised reports to each employee regarding their task from project managers
- Individualised reports to each salesman regarding their orders from ERP
What we did
- We currently have tonnes of processes which require EDT to run on daily / weekly basis. Once we discovered batch processes we decided to use some automation to help out
- all files are downloaded from SQL in csv format using AutoSQL (One time purchase and just works fab)
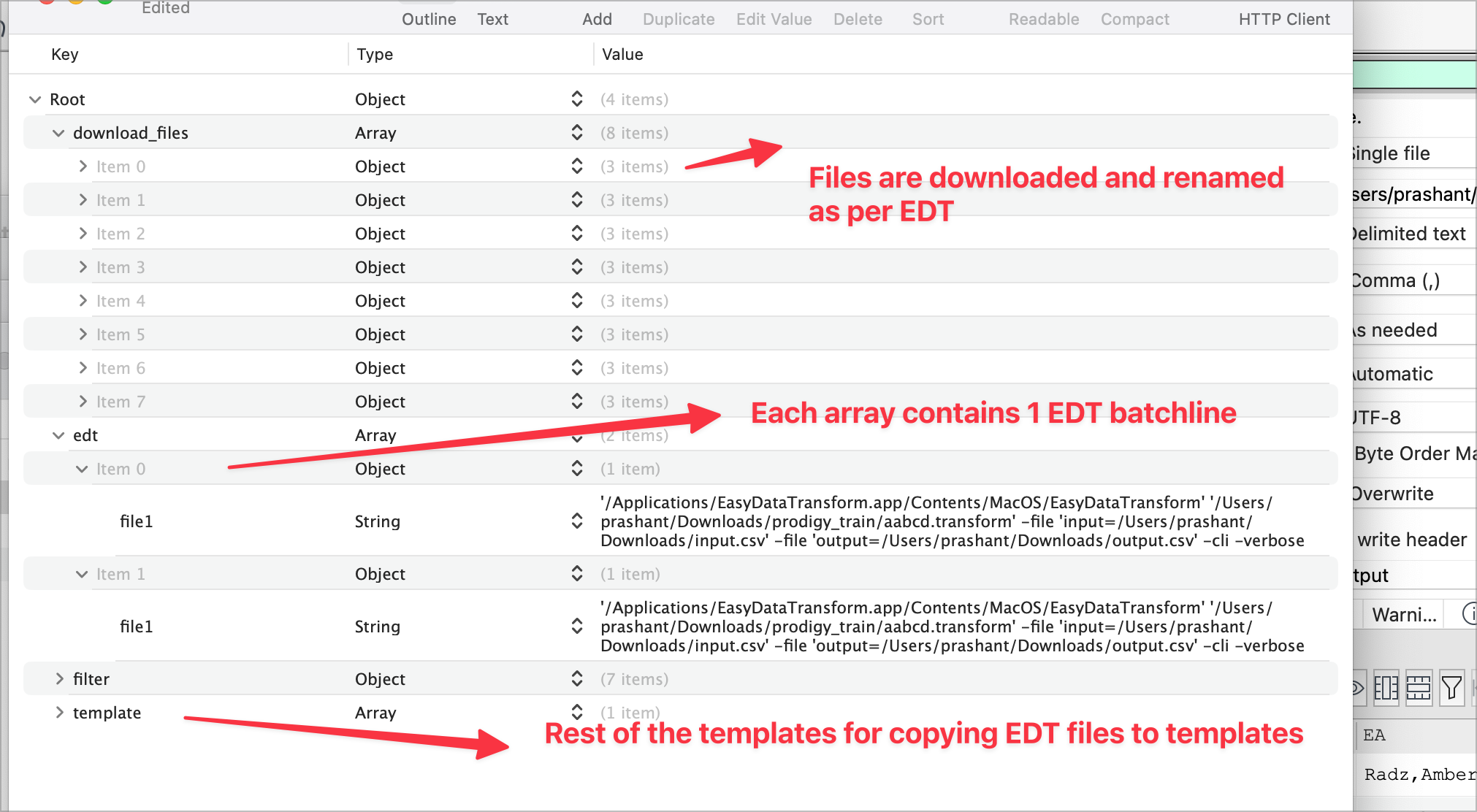
- using chatGPT we’ve made json files for each processes , it’s general structure is below
- Input Files from AutoSQL are renamed by AutoSQL
- Non SQL files are copied in 1 single input directory via python
- Python runs the CLI batch process for EDT
- EDT Processes files and outputs them
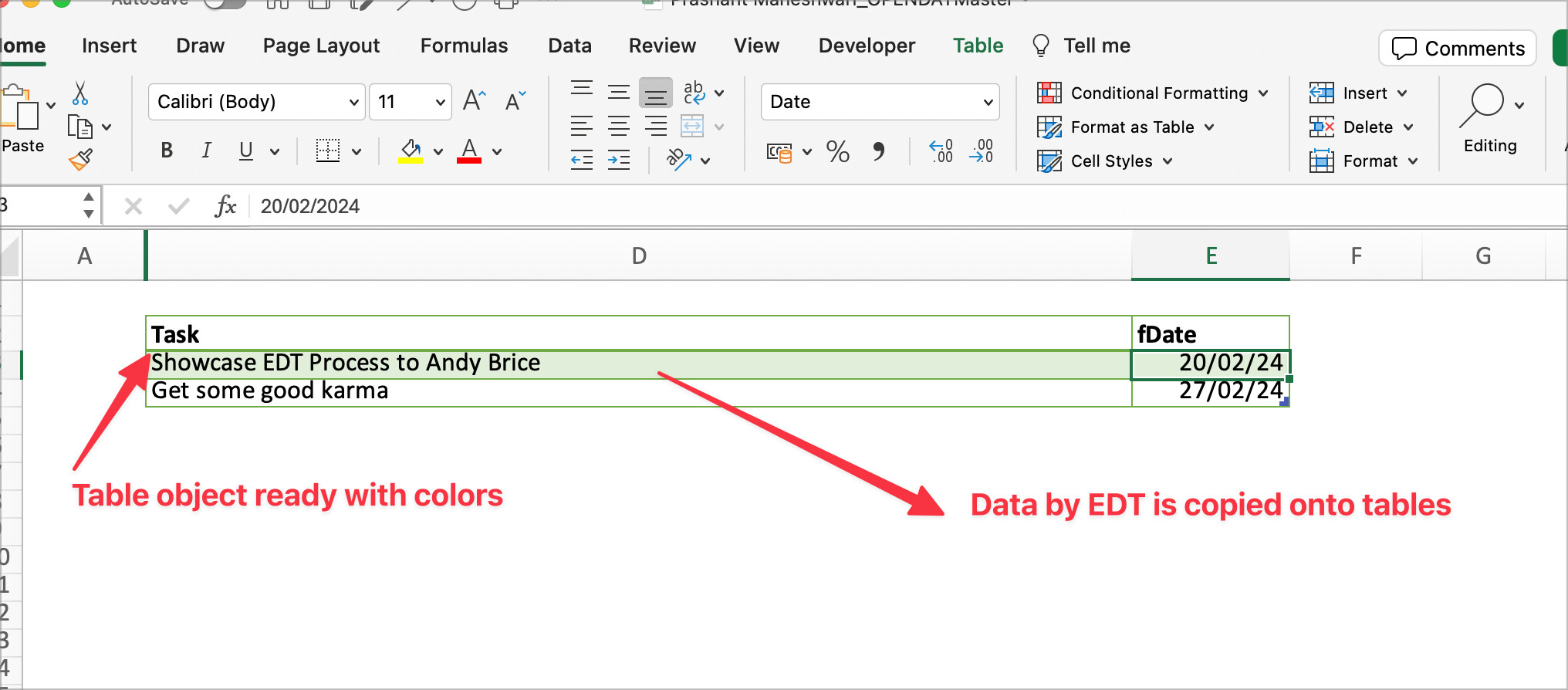
- Using python(xlwings) we copy the csv items in a templatised (is this a word?) ready XLSX file which contains ready made table objects
- Using XLWings solves the biggest problems I have with V1 of EDT , no templates
- Files are emailed to users using postmark api
Learnings
- the most tedious part was back and forth with chatGPT by team to make modular jsons, in hindsight we should have hired a programmer from fiverr
- We found more value in having some manual process , to verify data once downloaded , EDT is sensitive to column changes.
- XLWings was a game changer , it allows us to interact with excel tables as an object and add data to it directly without messing up ranges .
Questions
- what do your starting / end processes look like ?
- what tool you recommend ?
- Post not making sense ? well it’s 1:15 AM at time of posting this , what do you expect