I did gave users a template to enter data, the populated Files had to undergo some EDT transformations to be enriched and reformatted to be uploaded into a customer tool.
The template hat some headers, like: Value, Description, Amount
Now some users did change intended or by accident changed header names and distributed the template further.
e.g. Description was changed to Descrip or Descr
I described the Issue about a year ago already. In the past I had to open the files delivered all the time and check the headers and correct them if necessary.
I have now identified a solution to handle such cases, but only for known variances, like her that three different versions of the template are spread around and used.
Maybe this can help when facing something similar problem.
The solution is based on reading input data using schema, slide transformation and Remove columns.
In the schema I define all three variances of the “Description” header and read it in:
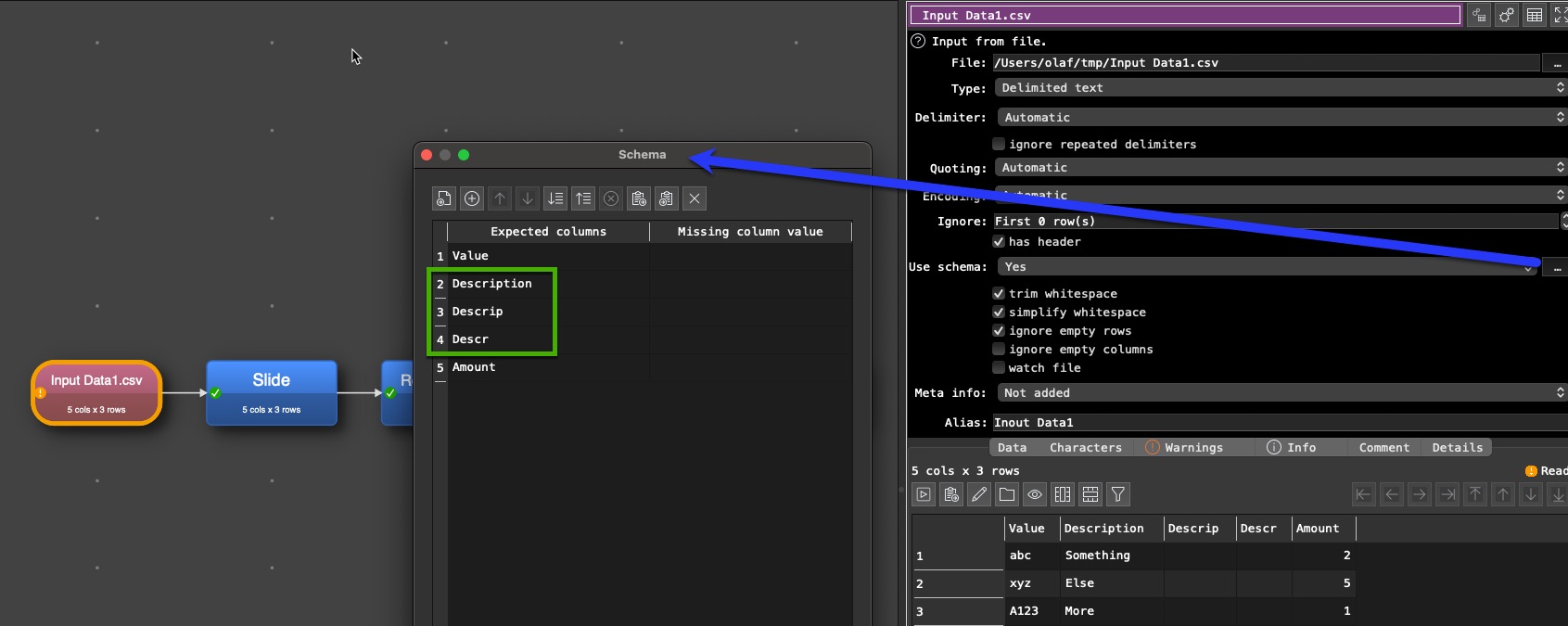
Only one of the three columns will be filled with data. The targeted header is the first one of the three.
Then I use slide to move data to the targeted column:
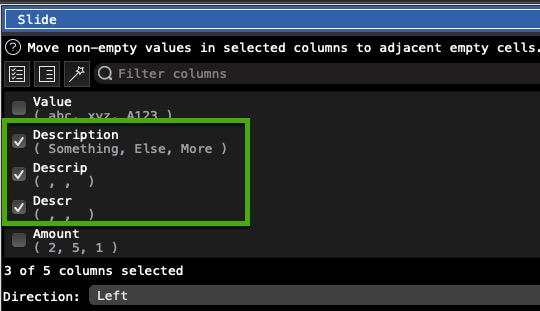
Afterwards, the to columns with the shortened header names are removed and further transformations can be done.
I added a example EDT file and three input files to try the effect.
Different Column names.transform (3.4 KB)
Input Data3.csv (63 Bytes)
Input Data2.csv (65 Bytes)
Input Data1.csv (69 Bytes)