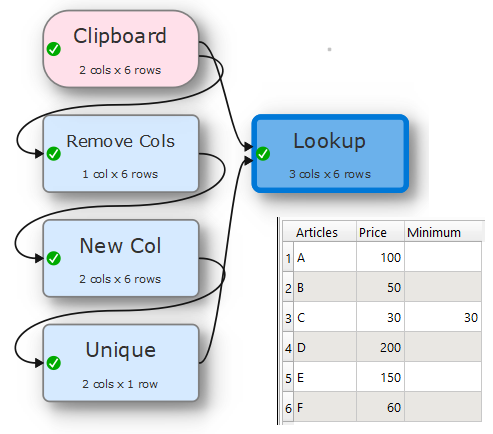
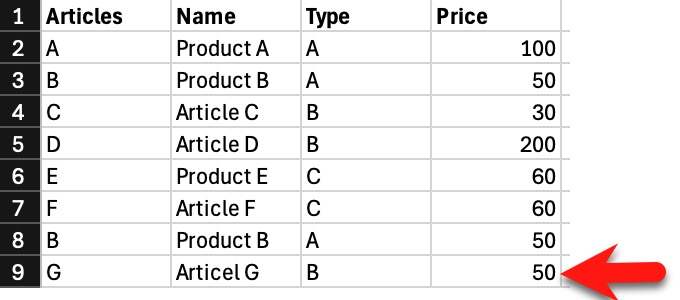
after mangling around with several files, I am looking for a way to select the row with the lowest value in on column for matching values in some other columns. I am looking for the lowest price for several alternative articles in a list with many articles in it.
Sounds like “unique” to me, but I need to keep the values from the row with the “minimal” hit and I can’t get this to work.
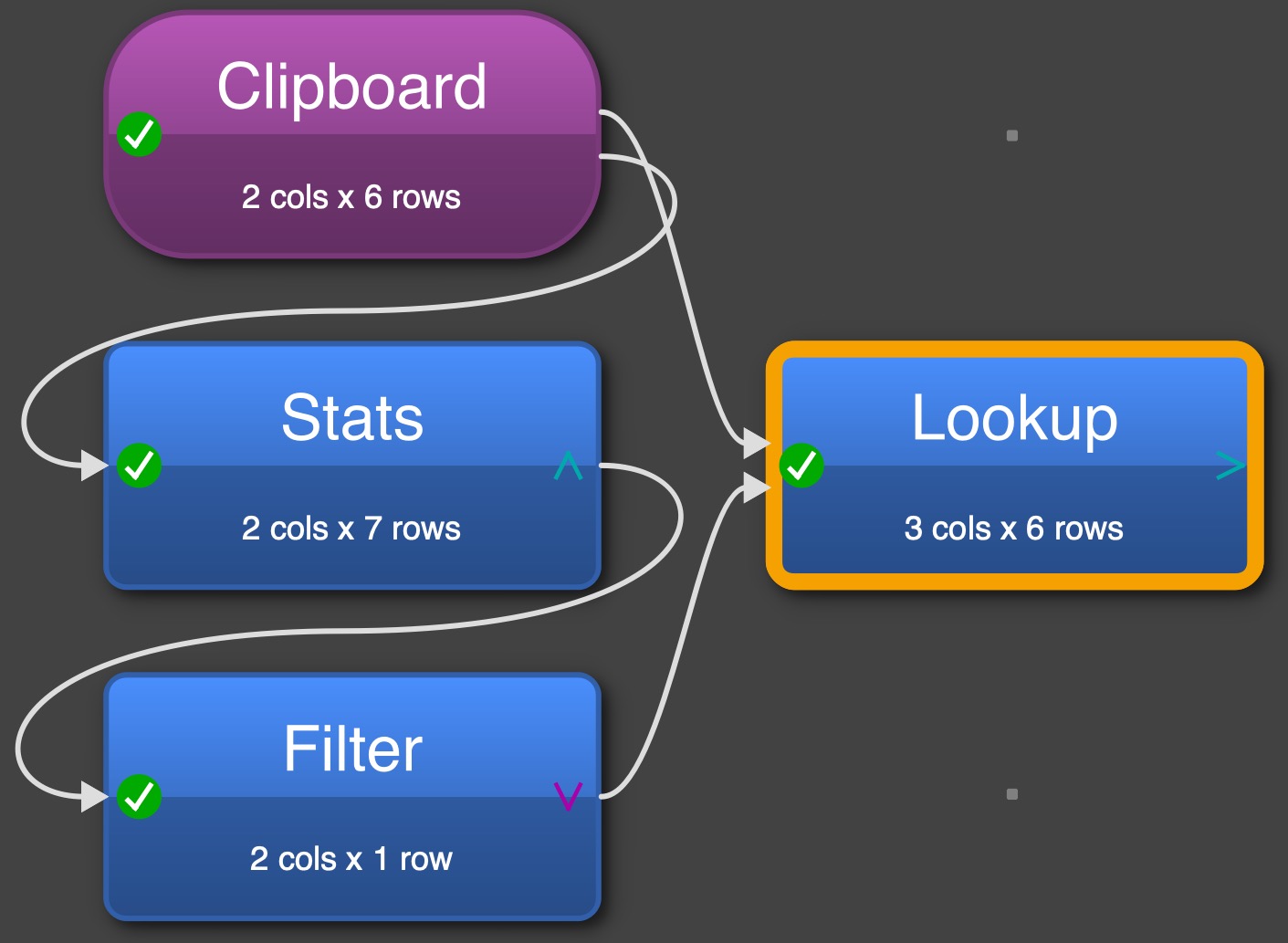
when I read it without seeing @Anonymous suggestion I had a similar idea. I would do the same using the Stats transformation, on step less, same out put. (yes it is nerdy, but just showing that EDT giver alternative ways)
and reading these approaches has inspired for me a much cleaner approach to a situation where I need to select only those rows for which a given value exceeds the nth percentile.
These options, seeing different ways of dealing with the same or similar problems, are helpful for learning (for this relative newcomer at least).
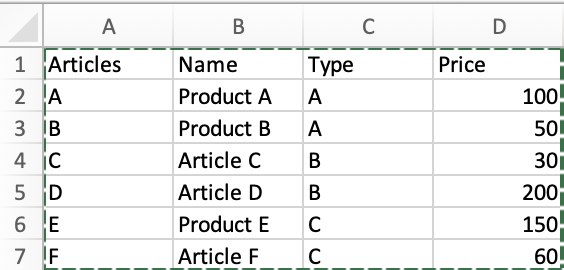
Wow, very cool solutions, thank you. I did not think that way at all. My data looks a little different as it contains a list of several articles of different kinds and I want to find the cheapest offer for each of them.
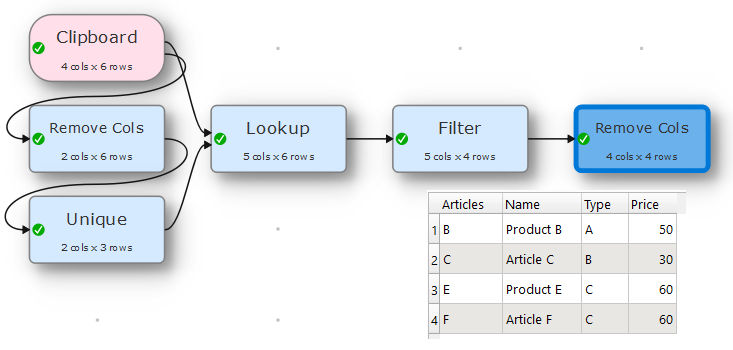
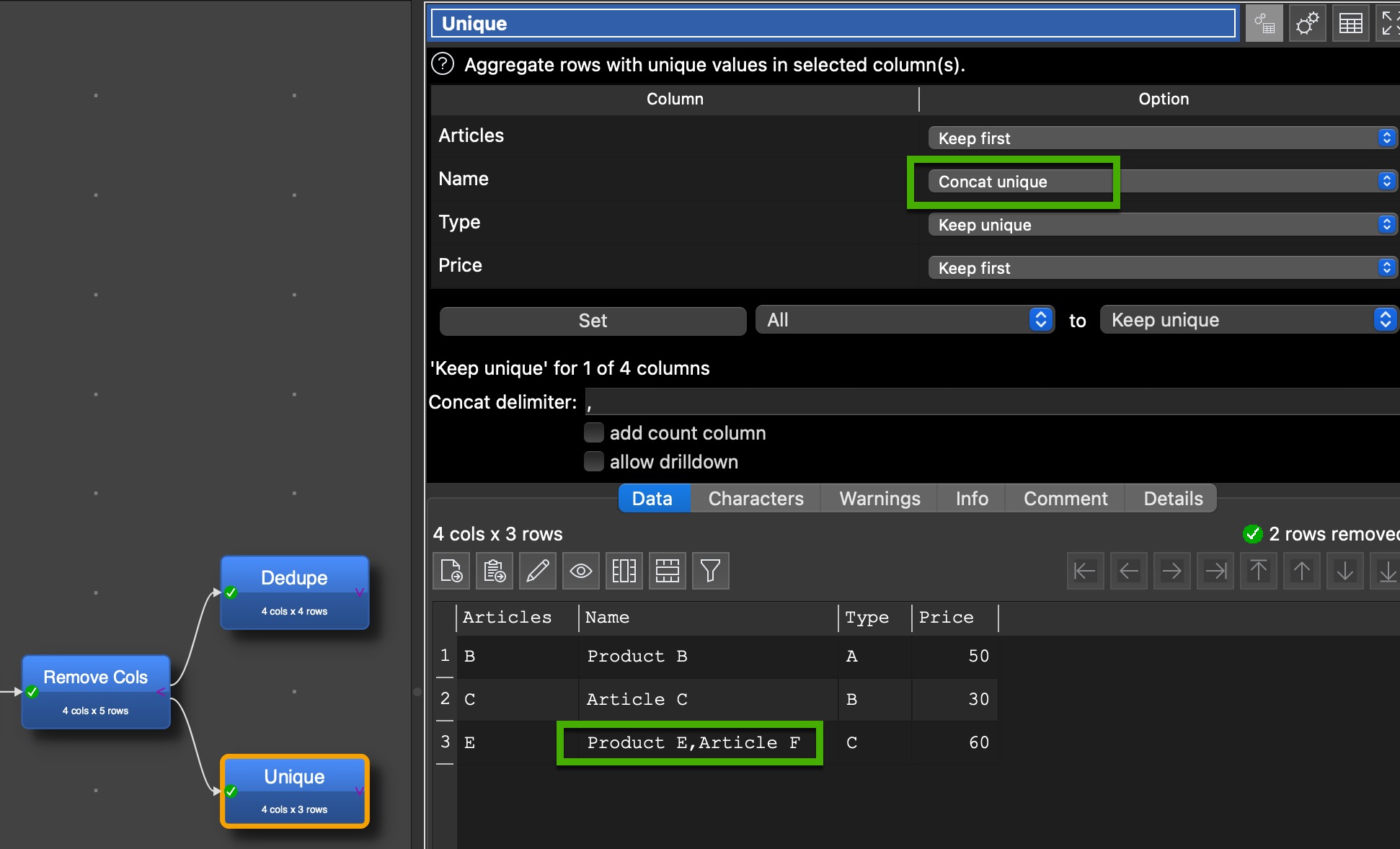
I came up with a solution using sort first. This way I organize my data so that the “use first” option works correctly. But to skip the sort step, perhaps Andy could implement an option to “keep from unique row”? This should be possible for cases where the unique row is identified through something like “minimum” or “maximum”
@joker , since you want to find the minimum Price based on Type, you did not mention the possibility of having same Price within the Type and if that is a possibility then none of the above solutions will work without making changes.
I modified my initial solution to accommodate possibility of having same low price for Type.
If that is not the case, then it is fine, but if it is a possibility then previous solutions need to be changed.
The current solution would show up Product G in Group B in the Lookup, too.
And if a row is duplicated like Product B, twice in row 3 and 8 it stays twice in the result.
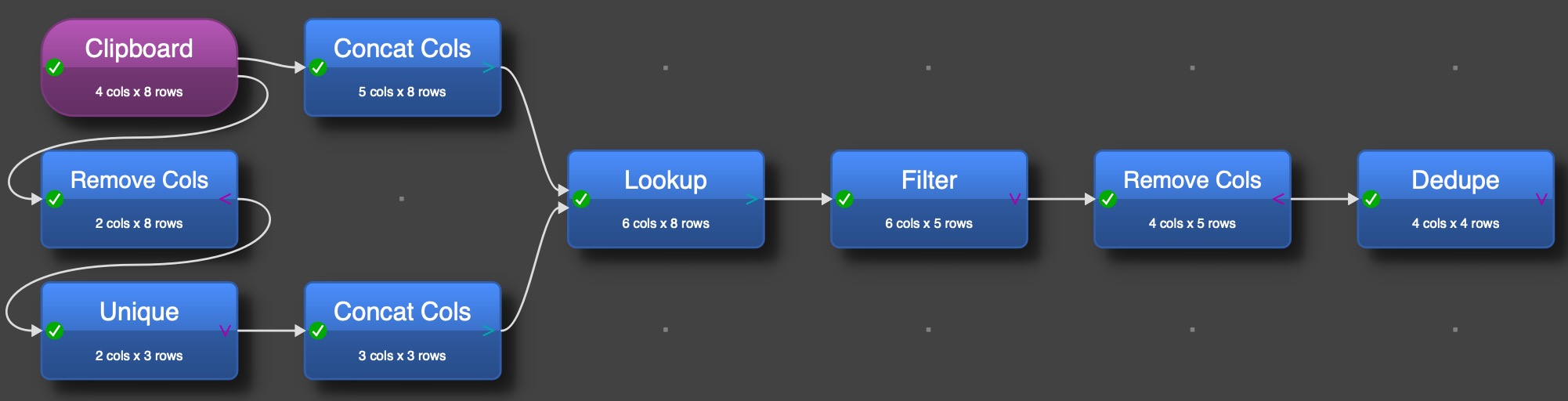
I inserted 2 Concat Cols to get this solved and a Dedup to remove any duplicates in the result.
The challenge with your topic was, as often, to guess what can happen in the data and treat it upfront.
But here we come back to a topic I recommended in the past, if some logic like here is build in a more complex transform graph, don’t forget to add Notes and use the comment in the transaction otherwise you lose track and don’t get what was build and why.
@joker , since you want to find the minimum Price based on Type, you did not mention the possibility of having same Price within the Type and if that is a possibility then none of the above solutions will work without making changes.
You are right, this might happen. To choose a product in this case is sort of undefined, you just have to pick one. My attempt with sorting first, than chosing the first per Type does just that.
Do you think my attempt has a problem?
There are often subtleties that aren’t clear when people first state a problem. For example:
Can a column have duplicates?
Can a column have blank or invalid values?
Is case important?
Is whitespace important?
Once we have added a Verify feature, you should be able to add something like “stop and show an error if there are any duplicates in this column”. That way you will be able to set up your .transform to make it clear what assumptions you are making.