I have a working solution, so this question is about a more efficient method or else a possible feature request.
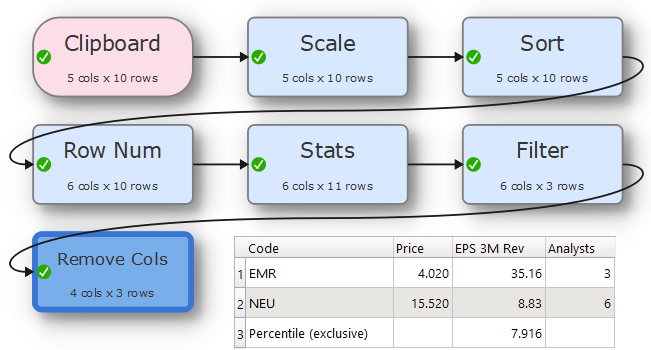
The nub of the problem is to filter rows by a value derived from a summary value or statistical output, in this case everything above a percentile value. The core transform with some sample data is attached. The general logic is to get the percentile value (Stats), trim rows and columns to isolate that value (Filter and Remove Col), then use Cross to add that value as a new column in the original data. This can now be Filtered normally before output formatting.
I am hoping for a more concise yet general solution for those four transform steps.
Another way to go about it would be to Sort the table on the column of interest then take the top 20%. For this I need an immediately available input of number of rows to avoid essentially the same steps as above.
For another option, I have never needed/wanted/bothered to learn javascript. I could but it is not my first preference.
@Anonymous. I had not earlier noticed that Meta Info is available, so that is immediately useful thanks.
I played around with Scale, then changed the number of input rows. Unless I missed something it appears that the scaling value must be adjusted manually for the number of input rows to get the right result. I replaced Scale with Calculate, multiplying Meta Info by 0.2 (i.e. one minus the desired percentile). After that (with related naming adjustments) it worked with different row counts.
A great use of If with Fill up. Technically I suppose this is only a step or two shorter but feels more elegant than the value isolation steps I originally used. The latter feels like chopping bits up on the side to reintroduce later, rather than progressive change on the original.
A good exercise for me thank you. It is interesting to see there are (at least) three clear solutions.
It would be useful if you could take a value from one dataset (e.g. the number of rows) and set it as the value of a parameter in a downstream transform. However it is a challenge to think of a way to do it that is simple for the user. It is something we hope to find time to think about a bit more.
The Outliers transform has the option to keep or remove rows outside a range. But the range is set by Inter Quartile Range or Standard Deviation, rather than percentage. Also it includes/excludes above and below the range, rather than just above below a cut off point.
Yes, that is definitely a possibility for future releases. But I need to do it in a way that doesn’t make Outliers too complex and confusing. Perhaps with a little text summary, similar to Filter.