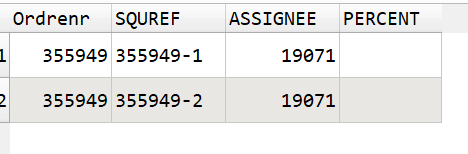
I have a set of data like this:
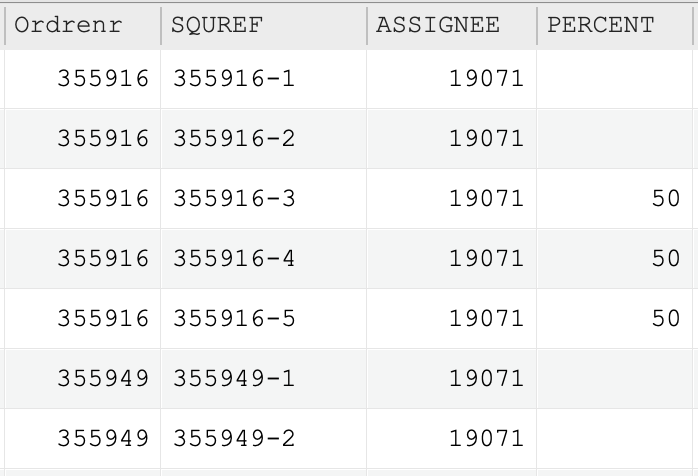
I want to remove all rows with the same “Ordrenr” if there is a value in PERCENT for any of the rows.
I bet there is a simple way of doing this, but please help me jumpstart my brain! ![]()
I have a set of data like this:
I want to remove all rows with the same “Ordrenr” if there is a value in PERCENT for any of the rows.
I bet there is a simple way of doing this, but please help me jumpstart my brain! ![]()
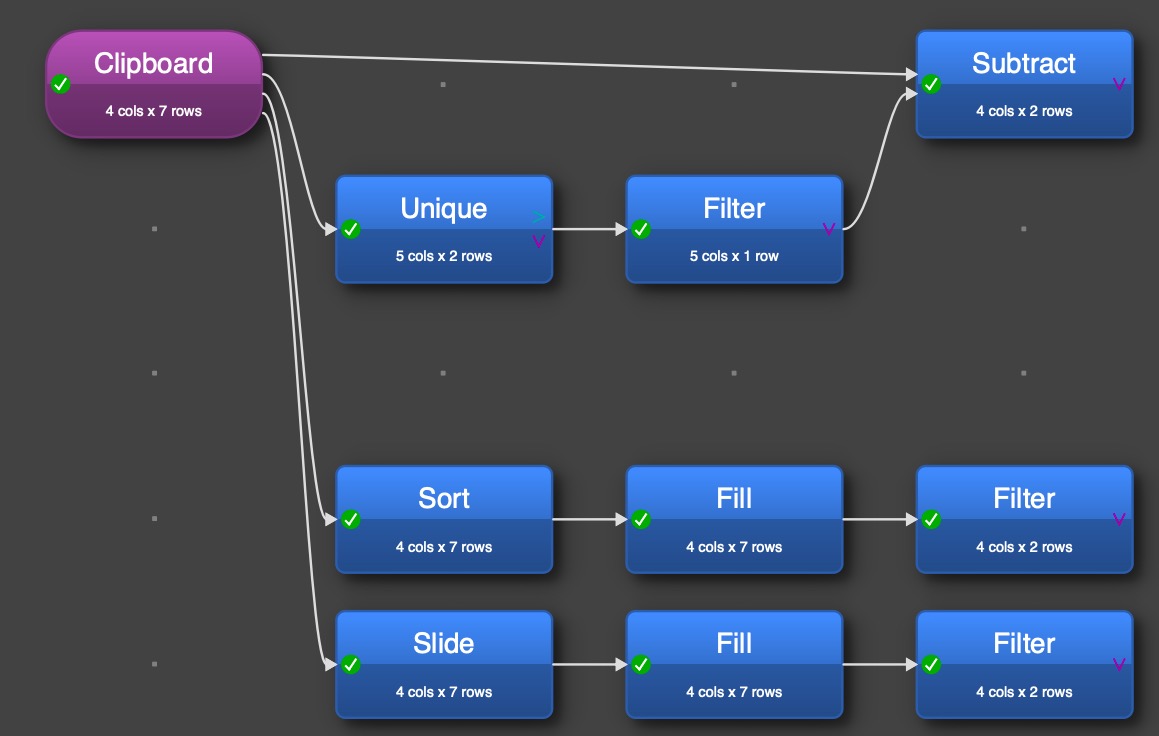
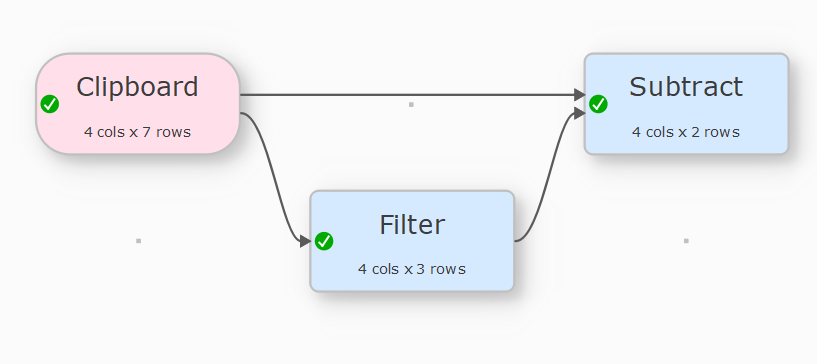
Use Unique with Ordrenr=Keep Unique and PERCENT=count non-empty.
Filter this to keep only the rows with PERCENT > 0.
Subtract this dataset from the original using Ordrenr as the key.
Brilliant! Thank you! ![]()
I had to try it to understand Admin’s suggestion, at top of the flow. I saw two further solutions:
The one with sort may result in a different order of the rows, the one with slide doesn’t change the order.
But the slide solution works only if the Ordrenr are on consequente blocks, so it is limited. My mathematical heart says Admin’s solution is the most elegant one ![]()
Filter Ordrenr.transform (5.9 KB)
Unless @Anonymous can do it in 2 transforms? ;0)
Yes, but that doesn’t help with:
Can you post the .transform?
Filter Ordrenr.transform (2.4 KB)
1st solution from Olaf without the “Unique”
I worked out how did it just before you posted the .transform. That is indeed a more elegant solution. ![]()
![]()