Is there a way to do something similar to Lookup transform, but that checks against more than one column in the bottom dataset?
Example, I would like to check a column with speaker names against BOTH the FirstName and the LastName in the bottom. I don’t know the order of names (could be first[ space]last; last[comma]first etc) or if a middle name is used in the top dataset, so I cannot easily pre ConcatColumns. Effectively would like to do something similar to LIKE ‘%first%last%’ OR LIKE ‘%last%first%’.
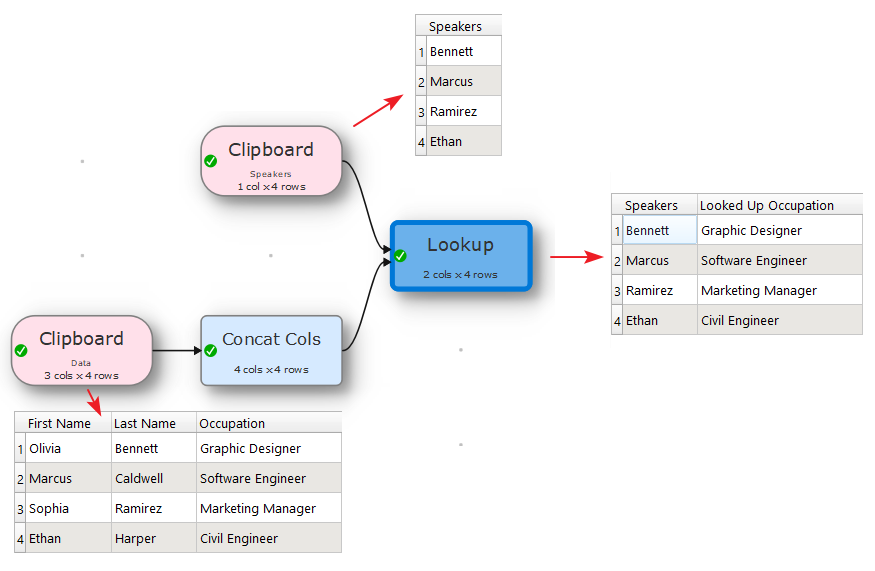
You can only do a Lookup on one column. But you could use Concat Cols to create columns with Last+First and First+Last, do a Lookup on each and then combine the results using If.
The Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other.
Your suggestion was what I already had: looking up assuming that the name+space+surname was exactly how the person would appear on the other source. What I was looking for was the ability to look for the 2 name components, regardless of where (and in what order) they appeared.
It would have been helpful, if you have provided a sample data, that would have avoided misunderstanding, as it is much easier to understand, if a sample input and output is provided, rather than explanation, which might be clear for the person asking the question, but it is not clear to ones who are trying to provide solution.
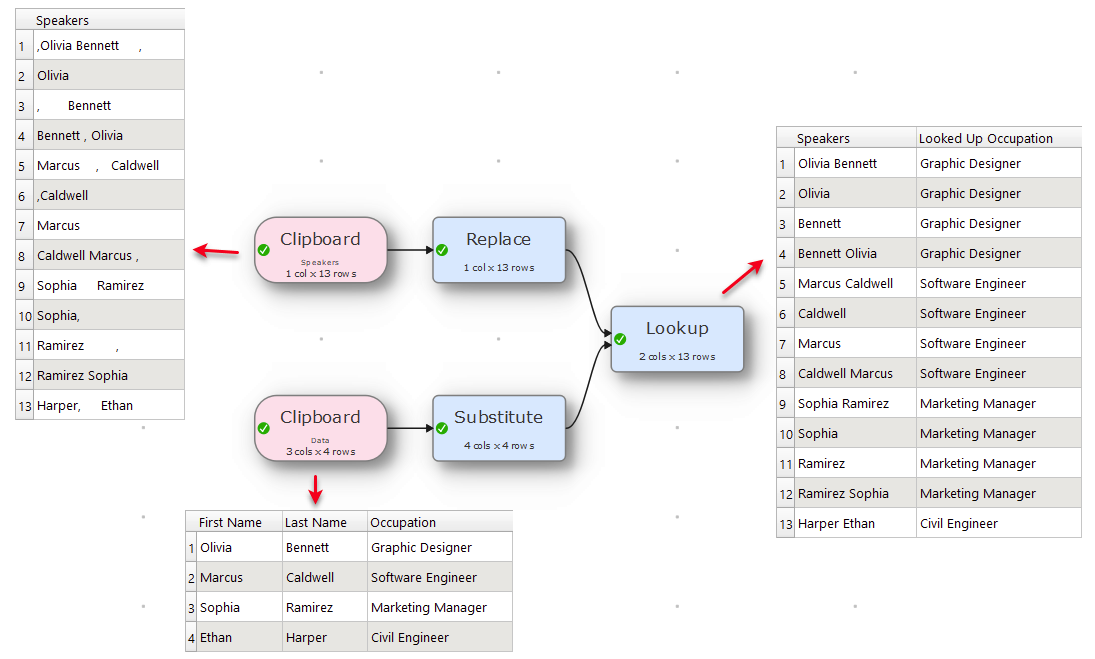
Hi, thanks for thinking along. That is indeed a valid suggestion, but it presupposes that what exists between the name and surname is only space(s) or a comma. If you look into my original post it, I would need for it to match also if there’s a middle name.
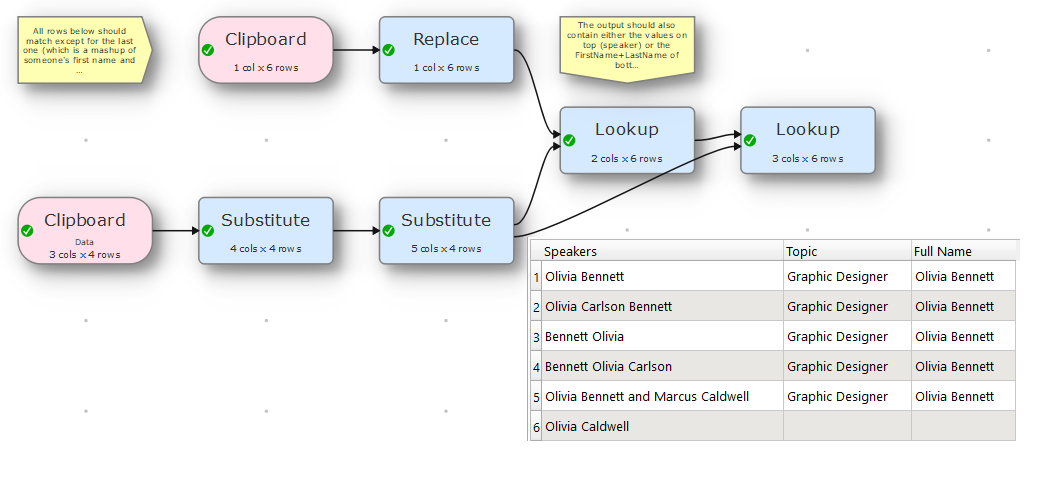
So, using some of the names in the sample you shared, I would need to match “Olivia Carlson Bennett”, not just “Olivia Bennett” and “Bennett, Olivia”.
I tried to come up with some way to - having Lookedup for just [first_name] in one branch, and [surname] in another, somehow intersect both sets (to get lines that had BOTH Olivia and Bennet). However, I could not get a good merge because of false positives e.g. A line with “Olivia Caldwell” (using your data set) would go though because it would’ve matched a [first_name] and a [surname], just not from the same person…
And that is why I asked to supply with the sample data, because in the post it is not clear where that surname is? is it in the Data or Only in the Speaker.
You have sample data from my solution, can you update that data set and provide how exactly it is with you.
Simply copy paste it in here, if you are not able to upload the file in here.
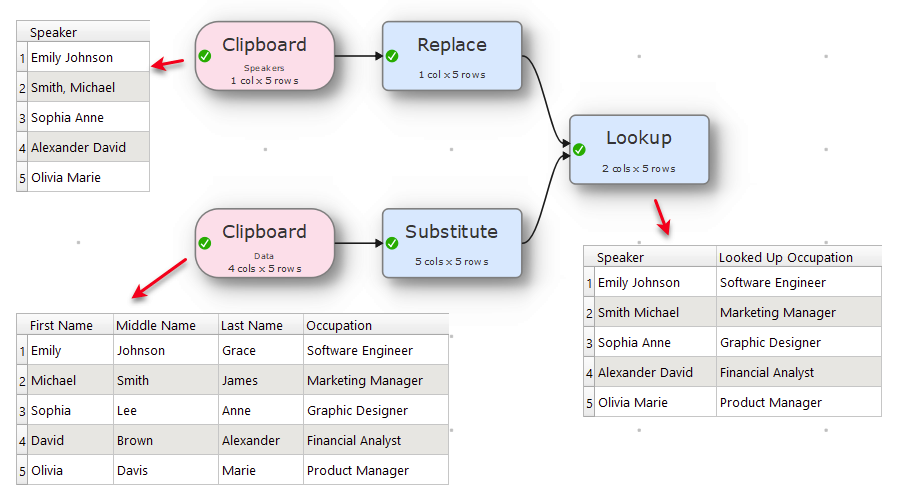
Here is an update and it should cover your requirements and if it still does not, then kindly share your data to know the edge cases and how to remedy it, if it is possible.
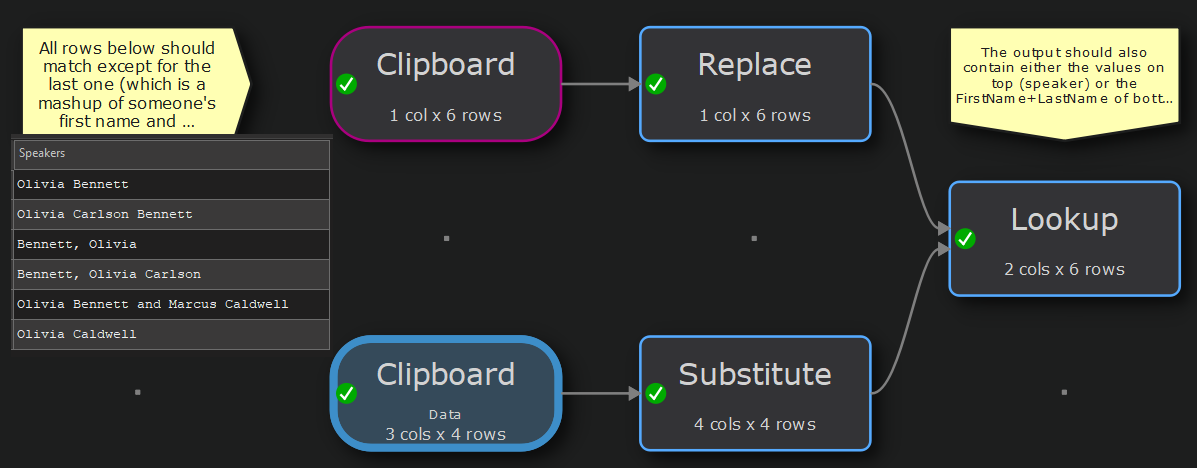
Hi, you’re right, it’s best I just add a sample. You misunderstood where the middle name may be found - it MAY be on the speakers lines (top dataset), not on the people lines (bottom dataset).
So, all speaker rows should match except for the last one (which is a mashup of someone’s first name and someone else’s surname). To be clear, the one before last SHOULD match, as it is made up of two valid people contributing to the same session as speakers.
(also, at the end the output must contain either the values on top (speaker) or the FirstName+LastName of bottom, but this is probably a minor thing we can achieve. I expect the two-column filtering is the crux of the problem).
Sorry for the delay in replying, I was away for a few days. This is awesome and exactly what I was looking for. I never noticed that you had the option “Top matches bottom regexp” - that’s the magic sauce.