Is there an easy way to filter based on the contents of values in adjacent rows? (a bit like the -A “after” and -B “before” options in ‘grep’)
For example, if I only wanted rows containing String1 in column 2 when the next row contained String2 in column 2 … and I wanted the option of keeping all pairs of rows (or ranges of rows) that matched, would that be possible?
It’s not critical if the timestamp value in column 1 in the second row is lost, so if it meant provisionally concatenating column 2 of the second row onto the first’s column 2, and then filtering, that wouldn’t be a problem - I just couldn’t work out a way to do that!
Apologies if I’m attempting to use EDT for something it’s not designed for; if needs be, I could always pre-process the file in something else first. I’m still trialing EDT and am just testing out some potential uses for it.
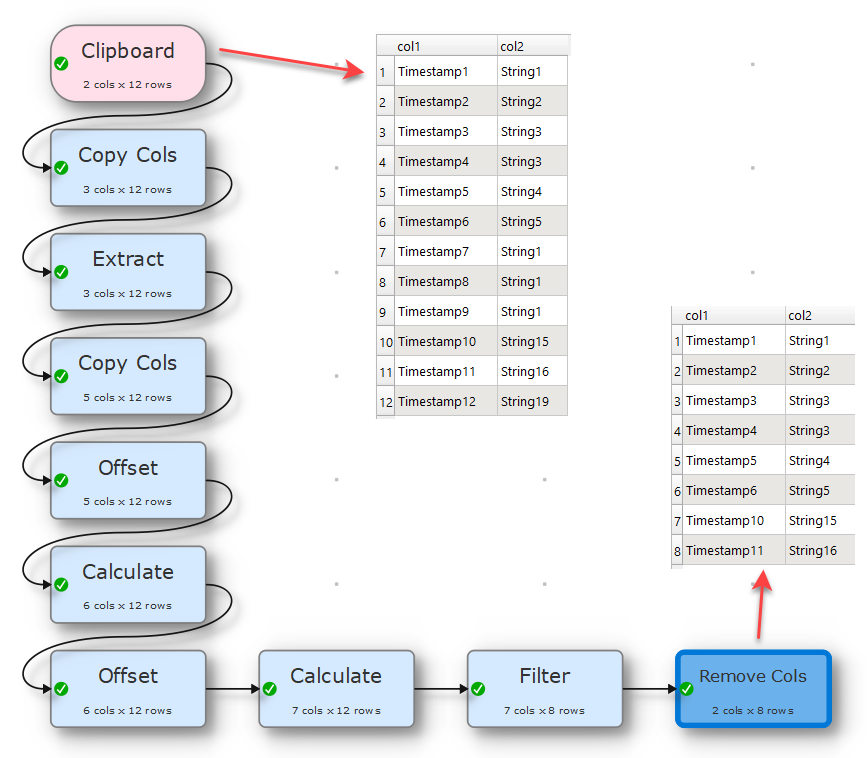
You need to copy the string column and work with “offset” to move the values in the copied column up or down. Then you can compare the values of the original String column and the copied one with “if” function. The result of “if” move with an offset again, afterwards you can filter and remove the interim columns. Maybe there are more elegant ways, but it works. See attached example.
Belated thanks to @Olaf, @Admin, and Anonymous for all of your swift and helpful replies (sorry - I was away for a few days without access to my computer, so couldn’t try out your suggestions).
This gave me just the help I needed to write exactly the set of transforms I wanted … and the confidence to buy a licence (which I’ve now done ).